This article has been taken from the brand new edition of Python Machine Learning by Sebastian Raschka and Vahid Mirjalili.
What is TensorFlow?
TensorFlow is a scalable and multiplatform programming interface for implementing and running machine learning algorithms, including convenience wrappers for deep learning.
TensorFlow was developed by the researchers and engineers of the Google Brain team; and while the main development is led by a team of researchers and software engineers at Google, its development also involves many contributions from the open source community. TensorFlow was initially built for only internal use at Google, but it was subsequently released in November 2015 under a permissive open source license.
To improve the performance of training machine learning models, TensorFlow allows execution on both CPUs and GPUs. However, its greatest performance capabilities can be discovered when using GPUs. TensorFlow supports CUDA-enabled GPUs officially. Support for OpenCL-enabled devices is still experimental. However, OpenCL will likely be officially supported in near future.
TensorFlow currently supports frontend interfaces for a number of programming languages. Lucky for us as Python users, TensorFlow's Python API is currently the most complete API, thereby attracting many machine learning and deep learning practitioners. Furthermore, TensorFlow has an official API in C++.
The APIs in other languages, such as Java, Haskell, Node.js, and Go, are not stable yet, but the open source community and TensorFlow developers are constantly improving them. TensorFlow computations rely on constructing a directed graph for representing the data flow. Even though building the graph may sound complicated, TensorFlow comes with high-level APIs that has made it very easy.
How we will learn TensorFlow
We'll learn first of all about the low-level TensorFlow API. While implementing models at this level can be a little bit cumbersome at first, the advantage of the low-level API is that it gives us more flexibility as programmers to combine the basic operations and develop complex machine learning models. Starting from TensorFlow version 1.1.0, high-level APIs are added on top of the low-level API (for instance, the so-called Layers and Estimators APIs), which allow building and prototyping models much faster.
After learning about the low-level API, we will move forward to explore two high-level APIs, namely TensorFlow Layers and Keras. However, let's begin by taking our first steps with TensorFlow low-level API, and ease ourselves into how everything works.
First steps with TensorFlow
In this section, we'll take our first steps in using the low-level TensorFlow API. Depending on how your system is set up, you can typically just use Python's pip installer and install TensorFlow from PyPI by executing the following from your Terminal:
pip install tensorflow
In case you want to use GPUs, the CUDA Toolkit as well as the NVIDIA cuDNN library need to be installed; then you can install TensorFlow with GPU support, as follows:
pip install tensorflow-gpu
TensorFlow is under active development; therefore, every couple of months, newer versions are released with significant changes. At the time of writing this chapter, the latest TensorFlow version is 1.3.0. You can verify your TensorFlow version from your Terminal, as follows:
python -c 'import tensorflow as tf; print(tf.__version__)'
Note
If you should experience problems with the installation procedure, I recommend you to read more about system- and platform-specific recommendations that are provided at https://www.tensorflow.org/install/. Note that all the code in this chapter can be run on your CPU; using a GPU is entirely optional but recommended if you want to fully enjoy the benefits of TensorFlow. If you have a graphics card, refer to the installation page to set it up appropriately. In addition, you may find this TensorFlow-GPU setup guide helpful, which explains how to install the NVIDIA graphics card drivers, CUDA, and cuDNN on Ubuntu (not required but you can find recommended requirements for running TensorFlow on a GPU here).
TensorFlow is built around a computation graph composed of a set of nodes. Each node represents an operation that may have zero or more input or output. The values that flow through the edges of the computation graph are called tensors.
Tensors can be understood as a generalization of scalars, vectors, matrices, and so on. More concretely, a scalar can be defined as a rank-0 tensor, a vector as a rank-1 tensor, a matrix as a rank-2 tensor, and matrices stacked in a third dimension as rank-3 tensors.
Once a computation graph is built, the graph can be launched in a TensorFlow Session for executing different nodes of the graph. As a warm-up exercise, we will start with the use of simple scalars from TensorFlow to compute a net input z of a sample point x in a one-dimensional dataset with weight w and bias b:
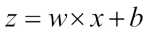
The following code shows the implementation of this equation in the low-level TensorFlow API:
import tensorflow as tf
## create a graph
g = tf.Graph()
with g.as_default():
x = tf.placeholder(dtype=tf.float32,
shape=(None), name='x')
w = tf.Variable(2.0, name='weight')
b = tf.Variable(0.7, name='bias')
z = w*x + b
init = tf.global_variables_initializer()
## create a session and pass in graph g
with tf.Session(graph=g) as sess:
## initialize w and b:
sess.run(init)
## evaluate z:
for t in [1.0, 0.6, -1.8]:
print('x=%4.1f --> z=%4.1f'%(
t, sess.run(z, feed_dict={x:t})))
After executing the previous code, you should see the following output:
x= 1.0 --> z= 2.7
x= 0.6 --> z= 1.9
x=-1.8 --> z=-2.9
This was pretty straightforward, right? In general, when we develop a model in the TensorFlow low-level API, we need to define placeholders for input data (x, y, and sometimes other tunable parameters); then, define the weight matrices and build the model from input to output. If this is an optimization problem, we should define the loss or cost function and determine which optimization algorithm to use. TensorFlow will create a graph that contains all the symbols that we have defined as nodes in this graph.
Here, we created a placeholder for x with shape=(None). This allows us to feed the values in an element-by-element form and as a batch of input data at once, as follows:
>>> with tf.Session(graph=g) as sess:
... sess.run(init)
... print(sess.run(z, feed_dict={x:[1., 2., 3.]}))
[ 2.70000005 4.69999981 6.69999981]
Note
Note that we are omitting Python's command-line prompt in several places in this chapter to improve the readability of long code examples by avoiding unnecessary text wrapping; this is because TensorFlow's function and method names can be very verbose.
Also, note that the official TensorFlow style guide recommends using two-character spacing for code indents. However, we chose four characters for indents as it is more consistent with the official Python style guide and also helps in displaying the code syntax highlighting in many text editors correctly as well as the accompanying Jupyter code notebooks here.
Working with array structures
Let's discuss how to use array structures in TensorFlow. By executing the following code, we will create a simple rank-3 tensor of size  , reshape it, and calculate the column sums using TensorFlow's optimized expressions. Since we do not know the batch size a priori, we specify
, reshape it, and calculate the column sums using TensorFlow's optimized expressions. Since we do not know the batch size a priori, we specify None for the batch size in the argument for the shapeparameter of the placeholder x:
import tensorflow as tf
import numpy as np
g = tf.Graph()
with g.as_default():
x = tf.placeholder(dtype=tf.float32,
shape=(None, 2, 3),
name='input_x')
x2 = tf.reshape(x, shape=(-1, 6),
name='x2')
## calculate the sum of each column
xsum = tf.reduce_sum(x2, axis=0, name='col_sum')
## calculate the mean of each column
xmean = tf.reduce_mean(x2, axis=0, name='col_mean')
with tf.Session(graph=g) as sess:
x_array = np.arange(18).reshape(3, 2, 3)
print('input shape: ', x_array.shape)
print('Reshaped:\n',
sess.run(x2, feed_dict={x:x_array}))
print('Column Sums:\n',
sess.run(xsum, feed_dict={x:x_array}))
print('Column Means:\n',
sess.run(xmean, feed_dict={x:x_array}))
The output shown after executing the preceding code is given here:
input shape: (3, 2, 3)
Reshaped:
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. 9. 10. 11.]
[ 12. 13. 14. 15. 16. 17.]]
Column Sums:
[ 18. 21. 24. 27. 30. 33.]
Column Means:
[ 6. 7. 8. 9. 10. 11.]
In this example, we worked with three functions—tf.reshape, tf.reduce_sum, and tf.reduce_mean. Note that for reshaping, we used the value -1 for the first dimension. This is because we do not know the value of batch size; when reshaping a tensor, if you use -1 for a specific dimension, the size of that dimension will be computed according to the total size of the tensor and the remaining dimension. Therefore, tf.reshape(tensor, shape=(-1,)) can be used to flatten a tensor.
Feel free to explore other TensorFlow functions from the official documentation here.
Developing a simple model with the low-level TensorFlow API
Now that we have familiarized ourselves with TensorFlow, let's take a look at a really practical example and implement Ordinary Least Squares (OLS) regression. (You can learn more about regression analysis in chapter 10 of Python Machine Learning, Predicting Continuous Target Variables with Regression Analysis.)
Let's start by creating a small one-dimensional toy dataset with 10 training samples:
>>> import tensorflow as tf
>>> import numpy as np
>>>
>>> X_train = np.arange(10).reshape((10, 1))
>>> y_train = np.array([1.0, 1.3, 3.1,
... 2.0, 5.0, 6.3,
... 6.6, 7.4, 8.0,
... 9.0])
Given this dataset, we want to train a linear regression model to predict the output y from the input x. Let's implement this model in a class, which we name TfLinreg. For this, we would need two placeholders—one for the input x and one for y for feeding the data into our model. Next, we need to define the trainable variables—weights w and bias b.
Then, we can define the linear regression model as , followed by defining the cost function to be the Mean of Squared Error (MSE). To learn the weight parameters of the model, we use the gradient descent optimizer. The code is as follows:
class TfLinreg(object):
def __init__(self, x_dim, learning_rate=0.01,
random_seed=None):
self.x_dim = x_dim
self.learning_rate = learning_rate
self.g = tf.Graph()
## build the model
with self.g.as_default():
## set graph-level random-seed
tf.set_random_seed(random_seed)
self.build()
## create initializer
self.init_op = tf.global_variables_initializer()
def build(self):
## define placeholders for inputs
self.X = tf.placeholder(dtype=tf.float32,
shape=(None, self.x_dim),
name='x_input')
self.y = tf.placeholder(dtype=tf.float32,
shape=(None),
name='y_input')
print(self.X)
print(self.y)
## define weight matrix and bias vector
w = tf.Variable(tf.zeros(shape=(1)),
name='weight')
b = tf.Variable(tf.zeros(shape=(1)),
name="bias")
print(w)
print(b)
self.z_net = tf.squeeze(w*self.X + b,
name='z_net')
print(self.z_net)
sqr_errors = tf.square(self.y - self.z_net,
name='sqr_errors')
print(sqr_errors)
self.mean_cost = tf.reduce_mean(sqr_errors,
name='mean_cost')
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=self.learning_rate,
name='GradientDescent')
self.optimizer = optimizer.minimize(self.mean_cost)
So far, we have defined a class to construct our model. We will create an instance of this class and call it lrmodel, as follows:
>>> lrmodel = TfLinreg(x_dim=X_train.shape[1], learning_rate=0.01)
The print statements that we wrote in the build method will display information about six nodes in the graph—X, y, w, b, z_net, and sqr_errors—with their names and shapes.
These print statements are optionally given for practice; however, inspecting the shapes of variables can be very helpful in debugging complex models. The following lines are printed when constructing the model:
Tensor("x_input:0", shape=(?, 1), dtype=float32)
Tensor("y_input:0", dtype=float32)
<tf.Variable 'weight:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'bias:0' shape=(1,) dtype=float32_ref>
Tensor("z_net:0", dtype=float32)
Tensor("sqr_errors:0", dtype=float32)
The next step is to implement a training function to learn the weights of the linear regression model. Note that b is the bias unit (the y-axis intercept at x = 0).
For training, we implement a separate function that needs a TensorFlow session, a model instance, training data, and the number of epochs as input arguments. In this function, first we initialize the variables in the TensorFlow session using the init_op operation defined in the model. Then, we iterate and call the optimizer operation of the model while feeding the training data. This function will return a list of training costs as a side product:
def train_linreg(sess, model, X_train, y_train, num_epochs=10):
## initialiaze all variables: W and b
sess.run(model.init_op)
training_costs = []
for i in range(num_epochs):
_, cost = sess.run([model.optimizer, model.mean_cost],
feed_dict={model.X:X_train,
model.y:y_train})
training_costs.append(cost)
return training_costs
So, now we can create a new TensorFlow session to launch the lrmodel.g graph and pass all the required arguments to the train_linreg function for training:
>>> sess = tf.Session(graph=lrmodel.g)
>>> training_costs = train_linreg(sess, lrmodel, X_train, y_train)
Let's visualize the training costs after these 10 epochs to see whether the model is converged or not:
>>> import matplotlib.pyplot as plt
>>> plt.plot(range(1,len(training_costs) + 1), training_costs)
>>> plt.tight_layout()
>>> plt.xlabel('Epoch')
>>> plt.ylabel('Training Cost')
>>> plt.show()
As we can see in the following plot, this simple model converges very quickly after a few epochs:
So far so good. Looking at the cost function, it seems that we built a working regression model from this particular dataset. Now, let's compile a new function to make predictions based on the input features. For this function, we need the TensorFlow session, the model, and the test dataset:
def predict_linreg(sess, model, X_test):
y_pred = sess.run(model.z_net,
feed_dict={model.X:X_test})
return y_pred
Implementing a predict function was pretty straightforward; just running z_net defined in the graph computes the predicted output values. Next, let's plot the linear regression fit on the training data:
>>> plt.scatter(X_train, y_train,
... marker='s', s=50,
... label='Training Data')
>>> plt.plot(range(X_train.shape[0]),
... predict_linreg(sess, lrmodel, X_train),
... color='gray', marker='o',
... markersize=6, linewidth=3,
... label='LinReg Model')
>>> plt.xlabel('x')
>>> plt.ylabel('y')
>>> plt.legend()
>>> plt.tight_layout()
>>> plt.show()
As we can see in the resulting plot, our model fits the training data points appropriately:
We hope you enjoyed this extract from Python Machine Learning 2nd Edition. If you want to learn more about TensorFlow and how to build and apply machine learning and deep learning algorithms to a range of different problems, visit the publisher’s website to find out more.

