Introduction
How many times have you come a cross "NullReferenceException" in the production environment and spent long hours to figure out what causes the problem? While doing this, have you met one of the following statements?
return null;
or:
return 0;
or:
return -1;
Exception management is essential and one of the most important topics of the software development but also most underestimated one. Developers can be ignorant about logging and exception management while they develop business requirements. Because, they do nothing in normal conditions. On the other hand, when an exception occurs in production environment, it can take several hours to solve the problem because of lack of logging and badly managed exceptions.
In this article, I'm going to write about couple of exception handling practices like avoiding null values, writing predictable function signatures, avoiding null reference exceptions, etc.
Background
The first question is, why does an exception occur? Software programs have several functions and sub-functions. Each function is executed sequentially and can have input and output arguments. Generally, a function's output becomes another one's input (Figure 1-a). While we are writing a function, we're dealing these input and output variables. We make some assumptions about these variables, consciously or unconsciously. Our code works well if our assumptions work (Figure 1-a). If something happens contradicting our assumptions, then our code behaves unexpectedly (Figure 1-b). To prevent these unexpected behaviours, we usually throw exceptions. So, good exception management starts with the right assumptions.
Figure 1
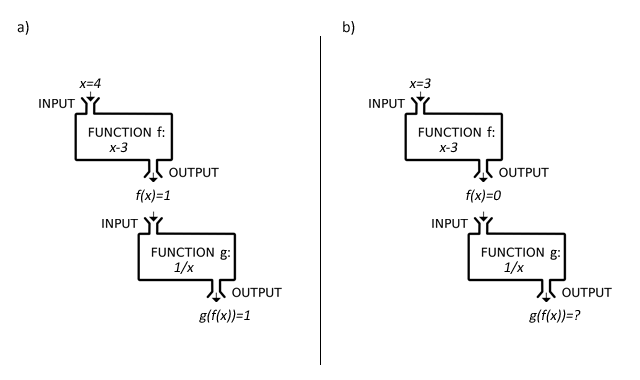
How to Make Assumptions?
Let's suppose that we are given an interface which contains the following two functions. One of these two functions returns null (we don't know which one) and other one throws an exception in case the customer does not exist.
Customer GetCustomerByEmail(String email);
Customer GetCustomerById(int customerId);
And we are using one of these functions:
Customer customer = customerProvider.GetCustomerByEmail(email);
CallCustomer(customer.PhoneNumber);
Should we check null value before using customer variable? Even if we know that, we might easily forget to check. We might also write unnecessary null-checking blocks which make our code messy. But if we return a nullable type instead of null value, then we can inform developers and force them to check a variable like this:
TNullable<Customer> GetCustomerByEmail(String email);
TNullable<Customer> customer = customerProvider.GetCustomerByEmail(email);
if (customer.HasValue()){
CallCustomer(customer.Value.PhoneNumber)
}
Note that Nullable<t> type cannot be used with reference types. So I wrote a TNullable<t> type that can be used with reference types. Luckily, nullable reference types were introduced in C# 8. You don't need to create a new type if you use C# 8.
And if we know that a function never returns a null value, then we don't have to write unnecessary null-checking blocks.
Now, we can focus on these two functions again and determine which one should return null and which one should throw an exception.
If we are writing GetCustomerById method as a helper method that we’re going to use internally, then we can suppose that this method always takes an identifier of an existing customer data.
Customer customer = customerProvider.GetCustomerById(order.CustomerId);
The situation that the customer doesn't exist in the database is an unexpected behavior. So it is good to throw an exception here. Don’t forget to log helpful information with the exception. It is recommended to have custom exception classes as well.
public Customer GetCustomerById(int customerId){
Customer customer = db.GetCustomerById(customerId);
if (customer == null)
throw new EntityNotFoundException("Customer not found. CustomerId:" + customerId);
return customer;
}
Now, let's say that we have a web page that can be used to search a customer with an email address.
TNullable<Customer> customer = db.GetCustomerByEmail(txtEmail.Text);
We can't suppose that a customer with a given email address always exists in the database. It's quite possible that any customer does not exist with given email address. In such cases, instead of returning a Customer type, it is better to return a nullable Customer type (TNullable<Customer>) to inform the developer this method might return a null value.
public TNullable<Customer> GetCustomerByEmail(String email){
Customer customer = db.GetCustomerByEmail(email);
return new TNullable<Customer>(customer);
}
When to Handle Exceptions?
Generally but not always true, it is good to handle exceptions in outer parts of call chain. But if an exception occurs in an unimportant or optional operation, you might want to write a warning to a log file and ignore the exception. Then, you might catch the exception inner part of the call chain. Also, you might want to catch exceptions and write informative lines to logger and rethrow exceptions to be handled by outer parts of the call chain.
Using the Code
To demonstrate the idea, that I talked about, I created a sample application. This sample application contains very simple model classes which contain just a few properties that we are going to use.

Other files/classes in the project:
DBConnection: A database mock class which returns predefined objectsTNullable: A class to define Nullable reference typesEntityNotFoundException: A custom exception classExample1, Example2, Example3: Three example files. Detailed information is belowProgram: Entry point of the application. By default Main method something like below:
static void Main(string[] args)
{
try
{
RunExample1();
}
catch (Exception ex)
{
LogEx(ex);
}
Console.ReadLine();
}
You can run other examples. Just comment out RunExample1() and uncomment one of the other lines.
Example1
Initial code with bad practices. Actually, there is no exception management at all. When you run, you get a "NullReferenceException". You don’t have any clue about what causes that exception.
Example2
A better implementation of the example. It throws an exception or returns TNullable object for null values. Now we know that the exception occurred while we load the City reference of the Address. But we still don't know which order's address has an invalid City reference.
Example3
In the third example, I added exception handling blocks, wrote helpful information and re-throwed exception. Now we know which order, address and city data causes the exception!
Conclusion
I tried to explain how to avoid null references, and write predictable method signatures to help developers to avoid unnecessary null-checking blocks. I hope you liked this article. Please share your opinions and suggestions.

