Introduction
This short series is aimed at those who are new to data warehousing and those who are used to the more traditional approaches but who are looking to the cloud with interest. In Part 1, we'll do a quick overview of the traditional on-premise data warehouse and how the state of the art has evolved and can now be found in the cloud. In Part 2, we'll get our hands dirty and build a toy cloud based data warehouse and feed it some data.
What is a Data Warehouse?
Data warehouses provide businesses the ability to analyse their data so they can make better business decisions. Decisions based on data are more effective than those based on hunches and intuition. A good data warehouse gives the business the ability to slice and dice their data and extract valuable insights into their business. Typically, this means report generation and dashboards for executives and managers, and tooling for analysts to explore the data.
Data warehouses need to be fed from the original data sources. These data sources could be relational/NoSQL databases in the enterprise, third party APIs like Salesforce APIs and partner organisation integrations that might involve flat files. All these data sources need to be combined into a coherent data set that is optimised for fast database queries.
We’ll take a look at the traditional on-premise approach and then compare and contrast that to the cloud services of today.
In the cloud, we often talk about IaaS, PaaS and SaaS, but what do those terms mean?
- Infrastructure as a Service (IaaS) basically means VMs, networks and storage. This is similar to on-premise but with additional elastic scaling mechanisms.
- Platform as a Service (PaaS) provide services where you don’t have to worry about VMs, backups, configuration, etc. They are higher level abstractions that reduce complexity and speed up your time to market.
- Software as a Service (SaaS) is PaaS on steroids. Usually abstracting away almost all the technical complexity and allow you to focus on what really matters.
The biggest cloud provider today is AWS. It has many PaaS services for data storage, computation and data analysis, in addition to some SaaS offering from companies like the Panoply cloud data warehouse, Periscope Unified Data Platform and Snowflake.
The Traditional Approach
The traditional way was on-premise, using an expensive relational database product with ETL jobs to feed it on a periodic basis. It worked but it could be slow to get data in and costly both in terms of the expertise necessary to maintain and operate it but also the software licenses and hardware. But businesses need the insights that a data warehouse can provide and so the costs were worth it.
The traditional relational database is row oriented. The data of one row is stored together. But data analysts usually want to perform aggregations on a small subset of columns at a time. For example, if we have a table of orders, we might want to perform aggregations by product. Each order row might consist of twenty or thirty columns and the GROUP BY queries would have to scan over every row, including having to read past all the columns that it is not interested in. This is a lot of wasted IO and is not great for performance or scalability.
So the dimensional model was born to compensate for this limitation. Now we store the order as a "fact" and have "dimension" tables for things like product, store, date, customer, etc.
For example, an eCommerce system runs on an OLTP database with following schema:
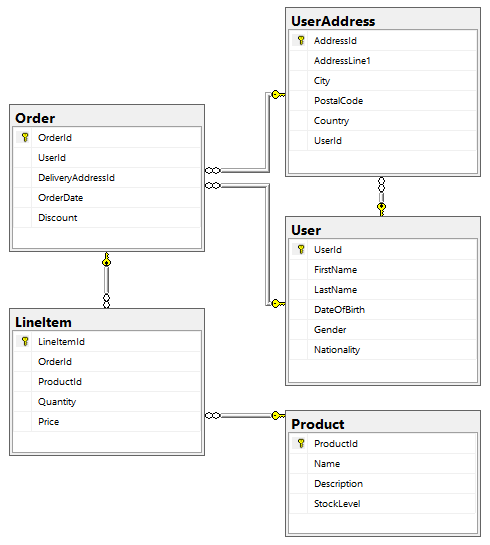
The ETL job periodically reads from the OLTP database and converts that model into a star schema as follows:

This star schema makes queries more efficient. We could even take it further and use snowflake schemas that carve up the dimensions even further. In addition to avoiding scanning over data that was not related to the query, dimensions could be augmented with precomputed values that avoided the need for on the fly functions to be applied. For example, the time dimension could include day, week, month, quarter and year columns or could be augmented with enterprise specific data such as company fiscal periods.
The move to the dimensional model made high performance data analysis possible on these row oriented data stores. The problem with this approach is that it is difficult to populate the dimensions in an efficient piecemeal way. Expensive ETL tools are often needed to automate away some of that complexity and it also makes online data warehouses unrealistic. At best, you can load data on an hourly basis but more often nightly.
ETL also has some costs. It can be slow to develop, often slow to run and you end up with a final generic transformation that is optimised for generic analysis. New and creative ways of transforming the data are now not possible because we don't have access to the original data. Transformations could include filters and once data is filtered out, there is no way of going back and getting the data unless you run a modified ETL process over all the data again. When new data sources become available, the business has to wait for new, often complex ETL pipelines to be developed, tested and deployed.
The cost per MB of storage in a relational database is much higher than typical file storage. Therefore, there are limits on how much data can be stored in the data warehouse. That means we have to think carefully about what to put in and the data retention time period. It eliminates whole data sets due to the size and cost of hosting it.
The Cloud Revolution
Today, the state of the art has moved on, and moved into the cloud. Today, we can store vast amounts of data more cheaply and more reliably than we could ever have hoped to do on premise. Not only is storage ridiculously cheap but the cost of compute has come down and new cloud technologies for analyzing and exploiting our data have emerged. Platform as a Service (PaaS) has come to data warehousing and now we see the rise of Software as a Service (SaaS) offerings too.
If we take a look at AWS, we see multiple PaaS offerings for data storage and querying that are seriously compelling. We can store all of our data in S3 cheaply, reliably and securely. We don't need to transform the data first, we just put it all straight into S3 and it will forever be there when we need it. This is usually referred to as a Data Lake. Data Lakes are not the same as Data Warehouses. They are essentially large dumps of data, both structured and unstructured, stored in cost-effective and reliable storage such as S3 with an accompanying meta-data store. Meta data is needed to keep a record of what data is stored where. If you lose control of your data lake by losing track of what the data is, where it is you end up with what's known as a Data Swamp.
Almost every AWS service, every third party cloud product and service integrates with S3. From there, we can move our data from our Data Lake into other PaaS services like EMR and Redshift. You could use Redshift today and tomorrow move to a SaaS offering and not worry about how to get your data across. The original data is all there in its original format in S3. You are not tied to your current data warehousing strategy and can shift as technology and services evolve.
Redshift
Redshift is a distributed, columnar store, data warehouse. That means it stores data not by its rows but by its columns, meaning that it can efficiently scan data of a single column for aggregations. This makes for much more efficient aggregations over massive datasets. It's still relational, you still write SQL, do joins and pretty much everything you are used to doing in a relational database.
But it is a paradigm shift where facts and dimensions are not always required anymore. Firstly, as it is already column oriented and secondly, it is a Massively Parallel Processing (MPP) platform. That means that computation is distributed across many nodes and we can do things that just weren't possible before. Those two things mean that we don't need to optimize our data in a rigid set of dimensions. We can perform efficient aggregations and projections leveraging the columnar nature of the data storage and the massively parallel compute.
So gone is the ETL of yesterday, it has been replaced by simpler ETL and ELT. ELT is that we Extract and Load, then Transform. We can do the Transform in Redshift in the form of a query. Transforms are no longer always performed before loading the data into the warehouse, but in the queries themselves. Again, made possible by the massive parallel processing of Redshift. It's not a panacea though and as with everything, it depends on your use case and how often these queries are run. Modelling can still be important if you have low latency query performance needs or very large datasets.
The data warehouse can even be an ephemeral construct that we build, use and discard on demand. We can use automation to create a right-sized Redshift cluster, pull in only the data we need, transform it and run our analyses over it, then once we have gained the insight we need we can materialize those results in another database and discard the data warehouse. It really is a revolution!
There are still some headaches you have to deal with:
- How do you keep track of your data stored in S3? Without an effective meta-data management strategy, you'll end up with a lot of data and not much idea of what it is or where it came from - the data swamp.
- Security. Access control, audit logging, monitoring. Security is almost always the hardest part of any architecture, be it on premise or in the cloud. The costs of getting it wrong can be getting on front page news as another data breach.
- S3 document sizing. I mentioned that S3 is super cheap, but that is only true if you use it right. One way to use it badly is to have a large amount of tiny files. S3 is most economical when you get a good balance of size. Too big and you end up reading more data than you need, and too little you pay more for data access and pay in performance as it is less efficient making that number of HTTP requests.
Getting Data into Redshift
There are too many options for getting data into Redshift to list. But below, I’ll give a couple of simple examples to get us going.
S3 to Redshift Direct
Export your data from on-premise data sources to S3. You can put your data into S3 as is or message it a bit first. We can run the COPY command from inside Redshift to copy delimited data in our S3 documents into tables in Redshift.
S3 to Lambda to Redshift
Adding an S3 document triggers a lambda function which performs some data transformations and then writes to Redshift. You can even write back to S3 and then use the COPY command as before.
S3 to EMR to Redshift
Sometimes, you need to do some serious transformations on your source data that only Hadoop can manage. You can run Hadoop jobs on Amazon EMR and write the results to Redshift.
What's Next
Then, there are the cloud data warehousing companies such as Panoply and Periscope Data that can read from pretty much any AWS service and even offer data exporters for your on-premise data sources, simplifying further your data architecture.
In the next part, we’ll start simple and build the S3 to Redshift architecture in AWS. We’ll cover the basics on how Redshift works, including how the distributed nature of the database affects our table designs. Once the data is in Redshift, we’ll run some queries and see how Redshift queries compare to the regular SQL you’re used to.
History
- 19th December, 2017: Initial version

