In a typical Data Warehouse project there is one step no developer can avoid: merge and loading data. Usually the Data Warehouse database merges data that comes from different data sources so, the proper data cleaning and data loading processes must be implemented.
The load process may require intermediate steps that load data into a staging area tables, perform data quality processes, validate business rules, validate iterations and finally load the fact table. The final fact table load process performs mostly lookup operations to enrich data. Those lookup operations will allow linking data among all dimensions and the fact record, as they migrate the correct dimension surrogate key into the fact grain.
Once the lookup operations represent most of the final load process overhead I will try to provide evidences regarding lookup approaches when enriching fact tables from bounded dimension records. Typical examples are age ranges, addresses that change over time (slowly changing dimensions - SCDs), household members that vary over time (delimited by dates), etc.
In this situation the condition required to identify the mapped surrogate key is a >= and <= one preventing database engines from using unique indexes and making the search operation much slower. Those lookups are usually called range lookups. In this tutorial I will “play with” a wage range dimension.
Attached to this tutorial is a T-SQL script that generates over than thirty two million rows of random wages between 250 Eur and 19999 Eur. The reader just needs to create an empty SQL Server database, run the procedure creation script and execute it (this script was tested on a SQL Server 2017 database running on a core I7 machine with 16Gb Ram and a 512Gb Solid State Drive, the same results should be obtained if similar code is created on Oracle or other relational database engines, even Microsoft Access). The procedure creates the proper range dimension, the corresponding auxiliary lookup table, the random wage values and runs a series of sequential insert statements using three lookup approaches into a fact table. The approaches are:
- A sub-query using a between clause against the dimension;
- A sub-query using the auxiliary lookup table;
- An outer join operation against the auxiliary lookup table;
Per each insert sequence, the records are pulled from the base raw data table using a random approach (the sample increases as powers of 2). In the end the procedure presents the milliseconds each join approach took to perform a single massive insert statement into the final fact table. To explain the used logic please check the schema bellow
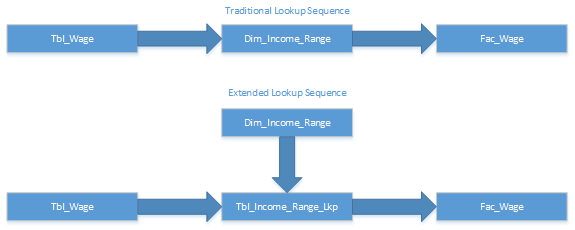
In the top schema (traditional lookup sequence) the ETL process raw data and performs a lookup against the required dimension using a bounded value approach (range lookup).
If the wage value in Tbl_Wage is between value A and value B the corresponding surrogate key from Dim_Income_Range is pulled and added to the final fact table. This approach prevents typical database engines from using unique index scans.
A possible approach to bypass these situations is to create an auxiliary lookup table that will be used only in the ETL enrichment process. At report or data exploration level the corresponding Dimension should be used as it is there that resides the range description (that should appear in reports).
This said, I must mention this approach may not be applied to all situations it will depend on the final auxiliary table size. So, let’s look at an arbitrary range
[1500 to 2000[
If we assume wages will only have two decimals the possible values between range bounds is limited so they can be enumerated (as a finit set). What I mean is, it is possible to create a single table with only two fields: the absolute wage value (e.g. 45.01 ; 45.02 ; 45.03 etc.) and the corresponding surrogate key present in the analysis dimension.
This table will be able to accommodate a proper unique index (cluster, non-cluster, SQL Server columnstore, oracle IOT, etc.) that will be able to speed up the lookup process a lot. It is relevant the first column on index is the wage value.
When using this approach the developer must be prepared to make concessions. The number of decimals may need to be truncated so one must balance the precision required to the ETL speed improvement. Questions like:
- Do I really need so much precision on data?
Should help reducing the final number of records the auxiliary table will have. There is also another limitation with this approach that is related to the bottom and top ranges. If they are unlimited on one bound side (-oo or +oo) the process must assume a very high or very low value to define lower and upper boundaries. The auxiliary lookup table cannot accommodate such a huge number of rows mostly because in the end the expected gains could vanish. So, if upper or lower limits are very high or very low a proper hard-coded condition can be added to the insert statement that verifies if the wage falls on those ranges and assigns the hard-coded surrogate key.
Of course this could be handled by using dynamic SQL but usually these dimensions are highly static so there shouldn’t be any problem on hard-coding one or two surrogate key values.
You should consider this post relates mostly to SQL approach, there are tools that are able to optimize lookups even on a parallel multi-thread approach. IBM Datastage for instance makes use of datasets. They are highly optimized data structures that will make lookup processes run much faster. Also, Microsoft SSDT (former SSIS) allows developers to use the full power of .net framework so it is possible to make use of memory data structures (like hash-maps or dictionaries) to improve range lookups a lot. Some of the most interesting posts I found and read on web related to this subject are the following ones
Developers should really consider approaches like the above ones if the required number of lookups is huge. Using those approaches it can even be possible to develop proper .net components, include them in SSDT project and even prepare them to process data subsets (that will allow parallel data flows). But this post is about SQL as ETL tools may not be available and nothing is really faster than running plain SQL statements if you do not need to leave database scope.
Let’s look at the final conclusions based in the attached script. After running it the final output should look like the one bellow (some rows were excluded). The most important part is the final list. There you will be able to observe the timings regarding each join operation per sample. Let’s put the final outcome in a chart, check the image after please.
*************************************************************************************
Creating wage range dimension ...
*************************************************************************************
Loading wage range dimension ...
*************************************************************************************
Creating auxiliar lookup table from the base dimension (this step runs only once) ...
*************************************************************************************
Row 50000
...
Row 2000000
*************************************************************************************
Finished creating auxiliary lookup table ...
*************************************************************************************
Generating over than 30 million random wage records between
250 Eur and 19999 Eur (this step runs only once) ...
*************************************************************************************
Finished generating over than 30 million random wage records ...
*************************************************************************************
Starting sample chunks insertion ...
*************************************************************************************
| Time in milliseconds | Sub Query (between) | Sub Query (Aux Lkp) | Outer Join (Aux Lkp) |
| Sample Size [2] | 616 | | 10774 | | 230 | |
| Sample Size [4] | 0 | | 7040 | | 223 | |
| Sample Size [8] | 3 | | 7217 | | 227 | |
| Sample Size [16] | 0 | | 6926 | | 227 | |
| Sample Size [32] | 3 | | 7007 | | 230 | |
| Sample Size [64] | 3 | | 7020 | | 230 | |
| Sample Size [128] | 4 | | 6870 | | 230 | |
| Sample Size [256] | 10 | | 7020 | | 233 | |
| Sample Size [512] | 17 | | 6850 | | 233 | |
| Sample Size [1024] | 30 | | 6880 | | 240 | |
| Sample Size [2048] | 64 | | 6946 | | 254 | |
| Sample Size [4096] | 123 | | 7257 | | 330 | |
| Sample Size [8192] | 246 | | 7157 | | 317 | |
| Sample Size [16384] | 470 | | 7190 | | 426 | |
| Sample Size [32768] | 927 | | 7363 | | 604 | |
| Sample Size [65536] | 1833 | | 7747 | | 910 | |
| Sample Size [131072] | 3643 | | 8627 | | 1513 | |
| Sample Size [262144] | 7273 | | 10820 | | 2577 | |
| Sample Size [524288] | 14490 | | 14057 | | 4840 | |
| Sample Size [1048576] | 29360 | | 21273 | | 9227 | |
| Sample Size [2097152] | 58430 | | 35203 | | 17977 | |
| Sample Size [4194304] | 93333 | | 52910 | | 28367 | |
| Sample Size [8388608] | 93660 | | 52556 | | 27184 | |
| Sample Size [16777216] | 93483 | | 53087 | | 27683 | |
| Sample Size [33554432] | 93007 | | 53486 | | 26930 | |

When looking at the above chart the gains seem evident as the sample size increases. After 250.000 rows sample size the range lookup approach against the dimension table seems to start increasing almost exponentially. On the other hand performing the unique scan against the indexed table allows much faster lookup operations. Now imagine you need to perform twenty range lookup operations per record, if we assume the gains are around 50%~70% one should expect very big improvements regarding the final ETL process.
Once again and as usual these are not dogmas, each project has its own requirements and there is no perfect solution for all cases. But a rule of thumb seems evident, make database work as smooth as possible, avoid brute force approach and make use of database features. Do not perform lookups when they could be avoided and know your base data well. Analyse it and try to find lookup patterns that may allow you to use unique index scans instead of range lookups. Column concatenation, full value list enumeration or even full surrogate key value hard-coding may allow huge improvements in lookup and load times. Perform conditional lookups, for instance, if the incoming value is null a simple NVL or ISNULL statement inside a CASE statement will prevent the lookup operation and will assign the default UNKNOWN or EMPTY value. As always be creative and search for other developers opinions and solutions.
The full T-SQL script that can be executed by you is presented below
create procedure [dbo].[sp_test_range_lookup]
as
declare @min_inf_limit decimal(18, 2)
declare @max_inf_limit decimal(18, 2)
declare @income_range_sk int
declare @c_base_rows cursor
declare @start_time datetime
declare @end_time datetime
declare @i int
declare @k int
declare @time_sub nvarchar(50)
declare @time_sub_aux nvarchar(50)
declare @time_sub_outer nvarchar(50)
declare @tmp_message nvarchar(500)
declare @u int
declare @t int
begin
set nocount on
if object_id('dbo.Dim_Income_Range', 'U') IS NOT NULL
drop table dbo.Dim_Income_Range;
print '*************************************************************************************'
raiserror(N'Creating wage range dimension ...', 0, 1) with nowait;
create table dbo.dim_income_range(Income_Range_Sk [int] identity(1,1) NOT NULL,
Inf_Limit [decimal](18, 2) NOT NULL,
Sup_Limit [decimal](18, 2) NOT NULL,
Range_Desc [nvarchar](50) NOT NULL,
constraint PK_Dim_Income_Class primary key clustered (Income_Range_Sk asc)) on [primary]
print '*************************************************************************************'
raiserror(N'Loading wage range dimension ...', 0, 1) with nowait;
set identity_insert [dbo].[dim_income_range] on
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (1, cast(0.00 as decimal(18, 2)), cast(500.00 as decimal(18, 2)), N'[0 to 500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (2, cast(500.01 as decimal(18, 2)), cast(1000.00 as decimal(18, 2)), N'[500,01 to 1000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (3, cast(1000.01 as decimal(18, 2)), cast(1500.00 as decimal(18, 2)), N'[1000,01 to 1500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (4, cast(1500.01 as decimal(18, 2)), cast(2000.00 as decimal(18, 2)), N'[1500,01 to 2000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (5, cast(2000.01 as decimal(18, 2)), cast(2500.00 as decimal(18, 2)), N'[2000,01 to 2500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (6, cast(2500.01 as decimal(18, 2)), cast(3000.00 as decimal(18, 2)), N'[2500,01 to 3000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (7, cast(3000.01 as decimal(18, 2)), cast(3500.00 as decimal(18, 2)), N'[3000,01 to 3500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (8, cast(3500.01 as decimal(18, 2)), cast(4000.00 as decimal(18, 2)), N'[3500,01 to 4000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (9, cast(4000.01 as decimal(18, 2)), cast(4500.00 as decimal(18, 2)), N'[4000,01 to 4500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (10, cast(4500.01 as decimal(18, 2)), cast(5000.00 as decimal(18, 2)), N'[4500,01 to 5000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (11, cast(5000.01 as decimal(18, 2)), cast(5500.00 as decimal(18, 2)), N'[5000,01 to 5500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (12, cast(5500.01 as decimal(18, 2)), cast(6000.00 as decimal(18, 2)), N'[5500,01 to 6000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (13, cast(6000.01 as decimal(18, 2)), cast(6500.00 as decimal(18, 2)), N'[6000,01 to 6500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (14, cast(6500.01 as decimal(18, 2)), cast(7000.00 as decimal(18, 2)), N'[6500,01 to 7000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (15, cast(7000.01 as decimal(18, 2)), cast(7500.00 as decimal(18, 2)), N'[7000,01 to 7500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (16, cast(7500.01 as decimal(18, 2)), cast(8000.00 as decimal(18, 2)), N'[7500,01 to 8000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (17, cast(8000.01 as decimal(18, 2)), cast(8500.00 as decimal(18, 2)), N'[8000,01 to 8500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (18, cast(8500.01 as decimal(18, 2)), cast(9000.00 as decimal(18, 2)), N'[8500,01 to 9000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (19, cast(9000.01 as decimal(18, 2)), cast(9500.00 as decimal(18, 2)), N'[9000,01 to 9500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (20, cast(9500.01 as decimal(18, 2)), cast(10000.00 as decimal(18, 2)), N'[9500,01 to 10000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (21, cast(10000.01 as decimal(18, 2)), cast(10500.00 as decimal(18, 2)), N'[10000,01 to 10500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (22, cast(10500.01 as decimal(18, 2)), cast(11000.00 as decimal(18, 2)), N'[10500,01 to 11000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (23, cast(11000.01 as decimal(18, 2)), cast(11500.00 as decimal(18, 2)), N'[11000,01 to 11500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (24, cast(11500.01 as decimal(18, 2)), cast(12000.00 as decimal(18, 2)), N'[11500,01 to 12000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (25, cast(12000.01 as decimal(18, 2)), cast(12500.00 as decimal(18, 2)), N'[12000,01 to 12500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (26, cast(12500.01 as decimal(18, 2)), cast(13000.00 as decimal(18, 2)), N'[12500,01 to 13000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (27, cast(13000.01 as decimal(18, 2)), cast(13500.00 as decimal(18, 2)), N'[13000,01 to 13500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (28, cast(13500.01 as decimal(18, 2)), cast(14000.00 as decimal(18, 2)), N'[13500,01 to 14000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (29, cast(14000.01 as decimal(18, 2)), cast(14500.00 as decimal(18, 2)), N'[14000,01 to 14500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (30, cast(14500.01 as decimal(18, 2)), cast(15000.00 as decimal(18, 2)), N'[14500,01 to 15000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (31, cast(15000.01 as decimal(18, 2)), cast(15500.00 as decimal(18, 2)), N'[15000,01 to 15500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (32, cast(15500.01 as decimal(18, 2)), cast(16000.00 as decimal(18, 2)), N'[15500,01 to 16000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (33, cast(16000.01 as decimal(18, 2)), cast(16500.00 as decimal(18, 2)), N'[16000,01 to 16500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (34, cast(16500.01 as decimal(18, 2)), cast(17000.00 as decimal(18, 2)), N'[16500,01 to 17000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (35, cast(17000.01 as decimal(18, 2)), cast(17500.00 as decimal(18, 2)), N'[17000,01 to 17500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (36, cast(17500.01 as decimal(18, 2)), cast(18000.00 as decimal(18, 2)), N'[17500,01 to 18000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (37, cast(18000.01 as decimal(18, 2)), cast(18500.00 as decimal(18, 2)), N'[18000,01 to 18500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (38, cast(18500.01 as decimal(18, 2)), cast(19000.00 as decimal(18, 2)), N'[18500,01 to 19000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (39, cast(19000.01 as decimal(18, 2)), cast(19500.00 as decimal(18, 2)), N'[19000,01 to 19500[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (40, cast(19500.01 as decimal(18, 2)), cast(20000.00 as decimal(18, 2)), N'[19500,01 to 20000[')
insert [dbo].[dim_income_range] ([income_range_sk], [inf_limit], [sup_limit], [range_desc]) values (41, cast(20000.01 as decimal(18, 2)), cast(9999999999999999.00 as decimal(18, 2)), N'[20000,01 to +oo[')
set identity_insert [dbo].[dim_income_range] off
create unique nonclustered index ix0_dim_income_range on dbo.dim_income_range(inf_limit asc, sup_limit asc,income_range_sk asc);
print '*************************************************************************************';
raiserror(N'Creating auxiliar lookup table from the base dimension (this step runs only once) ...', 0, 1) with nowait;
print '*************************************************************************************';
if object_id('dbo.tbl_Income_Range_Lkp', 'U') IS NOT NULL
drop table dbo.tbl_income_range_lkp;
create table dbo.tbl_income_range_lkp
(income_range_sk [int] not null,
wage_value [decimal](18, 2) not null) on [primary];
select @min_inf_limit = min(inf_limit),
@max_inf_limit = max(inf_limit)
from dbo.dim_income_range
set @u = 0;
while @min_inf_limit <= @max_inf_limit
begin
select @income_range_sk = income_range_sk
from dim_income_range l
where @min_inf_limit between l.inf_limit and l.sup_limit
insert into tbl_income_range_lkp
values(@income_range_sk, @min_inf_limit)
select @min_inf_limit = @min_inf_limit + 0.01
set @u = @u + 1;
if @u % 50000 = 0
begin
set @tmp_message = N'Row ' + cast(@u as nvarchar(20));
raiserror(@tmp_message, 0, 1) with nowait;
end;
end;
create clustered columnstore index [ics_tbl_income_range_lkp] on [tbl_income_range_lkp] with (drop_existing = off, compression_delay = 0) on [primary];
print '*************************************************************************************'
raiserror(N'Finished creating auxiliar lookup table ...', 0, 1) with nowait;
if object_id('dbo.tbl_wage', 'U') IS NOT NULL
drop table dbo.tbl_wage;
print '*************************************************************************************'
raiserror(N'Generating over than 20 million random wage records between 250 Eur and 19999 Eur (this step runs only once) ...', 0, 1) with nowait;
with tbl_a(id_seq) as (select 1 as id_seq),
tbl_b as (select id_seq
from tbl_a
union all
select id_seq + 1 as id_seq
from tbl_b
where id_seq < 5800),
tbl_cross_join as (select tbl1.id_seq
from tbl_b tbl1
cross join tbl_b tbl2)
select cast(row_number() over (order by id_seq) as int) as wage_id,
cast(round(rand(checksum(newid()))*(19999 - 250) + 250, 2) as decimal(18, 2)) as wage_value
into tbl_wage
from tbl_cross_join
option (maxrecursion 5800);
print '*************************************************************************************'
raiserror(N'Finished generating over than 12 million random wage records ...', 0, 1) with nowait;
if object_id('dbo.fac_wage', 'U') IS NOT NULL
drop table dbo.fac_wage;
create table dbo.fac_wage(
wage_sk [int] not null,
wage_value [decimal](18, 2) null,
income_range_sk [int] null
) on [primary];
print '*************************************************************************************';
print 'Starting sample chunks insertion ...';
print '*************************************************************************************';
print '';
print 'Time in milliseconds Sub Query (between) Sub Query (Aux Lkp) Outer Join (Aux Lkp)';
set @tmp_message = '---------------------------------------------------------------------------------------------';
raiserror(@tmp_message, 0, 1) with nowait;
set @i = 1;
set @u = 2;
set @k = @u;
while @k <= 35000000
begin
set @t = cast(floor(rand(checksum(newid())) * 10) as int);
set @start_time = getdate();
truncate table fac_wage
insert into fac_wage
select o.wage_id as wage_sk,
o.wage_value,
(select t.Income_Range_Sk
from dim_income_range t
where o.wage_value between t.inf_limit and t.sup_limit) as income_range_sk
from (select top (@k) h.wage_id,
h.wage_value
from tbl_Wage h
where h.wage_id % 10 = @t) o;
set @end_time = getdate();
set @time_sub = cast(datediff(millisecond, @start_time ,@end_time) as nvarchar(50));
set @start_time = getdate();
truncate table fac_wage
insert into fac_wage
select o.wage_id as wage_sk,
o.wage_value,
(select t.Income_Range_Sk
from tbl_income_range_lkp t
where t.wage_value = o.wage_value) as income_range_sk
from (select top (@k) h.wage_id,
h.wage_value
from tbl_Wage h
where h.wage_id % 10 = @t) o;
set @end_time = getdate();
set @time_sub_aux = cast(datediff(millisecond, @start_time ,@end_time) as nvarchar(50));
set @start_time = getdate();
truncate table fac_wage
insert into fac_wage
select o.wage_id as wage_sk,
o.wage_value,
t.income_range_sk
from (select top (@k) h.wage_id,
h.wage_value
from tbl_Wage h
where h.wage_id % 10 = @t) o
left outer join tbl_income_range_lkp t
on o.wage_value = t.wage_value;
set @end_time = getdate();
set @time_sub_outer = cast(datediff(millisecond, @start_time ,@end_time) as nvarchar(50));
set @tmp_message = 'Sample Size [' + replicate(' ', 12 - len(cast(@k as nvarchar(50)))) + cast(@k as nvarchar(50)) + ']' +
replicate(' ', 20 - len(@time_sub)) + @time_sub + ' | ' +
replicate(' ', 20 - len(@time_sub_aux)) + @time_sub_aux + ' | ' +
replicate(' ', 20 - len(@time_sub_outer)) + @time_sub_outer + ' | ';
raiserror(@tmp_message, 0, 1) with nowait;
set @i = @i + 1;
set @k = power (@u, @i);
end
end

