(Example jembench Mandelbrot benchmark run)

(Example ISPC mandelbrot benchmark run)
(reproduced from Pohl et.al "An Evaluation of Current SIMD Programming Models for C++")
Introduction
(Note: You can find the latest version of the jembench project on the project releases page)
In this article, I will present and explain benchmark results from benchmarking CPU Single Instruction Multiple Data (SIMD) performance in .NET Core using jembench, the CLI benchmarking tool from the jemalloc.NET project. The results show .NET Core SIMD program accelaration using the Vector<T> SIMD-enabled types to be comparable to programs written using the Intel Single Program Compiler (ISPC) with 9x acceleration of single-threaded vectorized .NET programs on an AVX2 processor. Multi-threaded .NET programs showed acceleration of 40-50x on an 8 core i7 Skylake processor. Single-threaded and multi-threaded SIMD program performance in .NET Core using RyuJIT and the .NET Task Parallel Library (TPL) is about 3x slower than ISPC compiled native code on an AVX2 processor. The ranges of relative and absolute .NET Core Vector<T> performance compared to ISPC are well within the observed performance ranges of C++ SIMD libraries when compared to ISPC.
Use of SIMD-enabled C# types like Vector<T> together with the RyuJIT x64 compiler and new .NET features like ref value types, Span<T>, and zero-copy reinterpretation of data stuctures, allow .NET developers to utilize the full SIMD capabilities of CPUs with performance comparable to C++ SIMD libraries, while maintaining the high-productivity of using C# and the .NET Framework. By using explicit vectorization types like Vector<T> and allowing the RyuJIT compiler to generate the instructions required to utilize the CPU's vector units at runtime, the need to utilize low-level intrinsics in unmanaged C libraries is reduced. C# can be used to develop computation kernels for data-parallel workloads without the need to interface with external C or C++ libraries for achieving high performance. Use of concurrent tasks through the TPL can be combined with data parallelism on single CPU cores to maximize utilization of multi-core CPUs. As work on improving SIMD support in RyuJIT continues, .NET developers can expect the absolute performance numbers of .NET Core programs to move closer to the performance of native code. Vector<T> together with the jemalloc.NET native memory manager for managing very large in-memory arrays makes .NET a viable platform for developing in-memory numeric, scientific, and other type of HPC applications.
Background
SIMD
Several authors have observed that while SIMD vector units have been present in modern CPUs for decades, the SIMD programming model is still very effort-intensive and inflexible with the result being the vast majority of applications never utilize the SIMD capabilities of CPUs, and so never utilize the most effective and important way of maximizing the data processing performance of modern CPUs. The triple constraints of having to access the CPU hardware at a low-level, while enabling porting existing algorithms and routines to 'vectorized' implementations, while also ensuring that code is portable and effective across different SIMD instruction sets and possibly different chip architectures, makes creating an effective SIMD programming model for developers a daunting task.
The Internet and the ubiquity of massive-scale distributed and client-server applications meant that in recent years, application performance has been generally seen as I/O-bound, with optimizations at the CPU hardware level only being important for games and other specialized kinds of applications. For general business applications, the extra effort needed for developers to utilize SIMD capabilities on the CPU has not seen as justifiable compared to the productivity gains from using high level programming languages like C# and Java which were designed to insulate programmers from the complexity of such low-level programming. For instance, SIMD support was only first seen in the .NET RyuJit JIT compiler in 2014, 10 years after the introduction of .NET and the introduction of the SSE2 instruction sets by Intel and AMD. (To its credit Mono began supporting SIMD six years earlier in 2008.)
The emergence of cloud and big-data computing, machine learning, and many other computing advances has put the application performance focus back on achieving low-level hardware performance. Applications in languages like Java and C# are increasingly being called upon to work at scale processing huge amounts of data within a specific time-frame with workloads that exhibit large amounts of data parallelism. The use of GPGPUs with their parallel Single Program Multiple Data (SPMD) capabilities has been viewed as the next-generation hardware solution for these workloads, but general purpose CPUs are still more effective at handling diverse sets of programs and data. At least one paper has questioned the promised performance gains of GPUs over multi-core CPUs on highly parallel workloads. But GPU performance notwithstanding, it is still extremely important today from multiple POVs, like energy-efficency for instance, that software be able to maximize the capabilities of the underlying CPU hardware.
Writing computation kernels in assembly language or using SIMD intrinsics in languages like C is still the only way to guarantee maximum SIMD performance from CPUs. But raw performance is not the whole story. SIMD programming is always a tradeoff between programmer effort and productivity, and performance. Even though performance in today's data center environments can be literally measured in dollars and cents, code that performs 3x faster may not be more desirable if it requires more than 3x the effort and costs to develop, maintain and integrate into an existing application. As a newcomer to general SPMD programming, I admit it took me a week to convert the serial programs benchmarked here to effective vectorized implementations in C#. Writing vectorized code requires you think about familiar concepts like loops in more general logical terms, rather than in simply operational terms. It also requires you to think about memory access and the instructions your compiler is going to generate, and to work iteratively towards optimizing your algorithms. This unfamiliarity and additional difficulty and complexity required to vectorize existing code has undoubtedly contributed to the lack of uptake of SIMD programming.
Vectorizing Your Code
There are a couple of ways that compilers help you to write code that takes advantage of SIMD capabilities or vectorize existing code. Probably the simplest approach is to use libraries like Intel MKL which contain code that has already been optimized for SIMD. Apart from the extensive costs this can incur, a major drawback of this approach is that these libraries must already exist for the domain you are working in. Building on or extending these libraries with custom code for your specific problem leaves you with the same problems of how to optimize your code for SIMD.
The next simplest approach is to simply tell the compiler to do auto-vectorization of your existing code, where the compiler analyzes your code looking for places that would benefit from using vectorization and generates the best-effort vector code. C++ compilers like LLVM and GCC and MSVC have switches that enable emitting SIMD instructions for loop vectorization and the use of auto-parallelization algorithms like Super-Word Level Parallelism. However, auto-vectorization will obviously only be possible when the code is relatively simple such that the compiler's static analysis can deduce the correct vectorized version of your code. Although auto-vectorization is a highly-desired feature of compilers and can be implemented without any changes to the core language, the effectiveness of auto-vectorization implementations by modern compilers is not clear.
Another method of utilizing SIMD is provided at the compiler or tool level by implicit-vectorization. With implicit vectorization, you use #pragma or other directives and attributes and keywords to tell the compiler or pre-processsor which blocks of code should be vectorized, and to provide hints on how to generate the correct vectorized code. The advantage of implicit vectorization over auto-vectorization is that the compiler has a lot more information about how to vectorize a particular code block. This disadvantage is that implicit vectorization must be implemented as compiler-specific directives or extensions that are not portable among compilers and may not have support at the language level. The application logic is not explicitly vectorized and the compiler may not be able to optimize use of the SIMD registers and instructions for the particular implementation.
Explicit vectorization libraries require the programmer to explicitly vectorize their serial algorithms either via low-level intrinsics or through interfaces and types that are abstract representations of SIMD vector registers and operations. Intrinsics libraries in C and most C++ SIMD libraries like UME::SIMD, Vc, Boost.Simd, and others fall into this category.
Other solutions exist like embedded DSLs for SIMD vectorization, or JIT compilation to SIMD instructions during program execution, as well as approaches that are considered hybrids of these classes of vectorization solutions. ISPC and Vector<T> can both be considered hybrid vectorization solutions.
Vector<T>
The .NET Vector<T> type abstracts a SIMD register and the arithmetic and bitwise and logical operations that can be performed in parallel on data in SIMD registers. At runtime, the RyuJIT compiler generates the CPU instructions needed to execute the operations specified by the developed. Vector<T> is therefore a hybrid of the explicit vectorization model and JIT compilation to SIMD instructions.
Intel Single Program Compiler
The ISPC compiler provides C language extensions that allow the developer to express Single Program Multiple Data algorithms in a dialect of C. With ISPC, you must separate the parts of your application logic that will be parallelized and implement your parallel algorithms in the ISPC language and parallel programming model, which is then compiled into native code that can run on the CPU and can be linked to other C or C++ code. Unlike Vector<T>, there are no explicit types for abstracting SIMD registers or operations; rather you express your logic in a serial fashion using C and scalar variables, and the ISPC compiler infers how the program should parallelized. ISPC is thus a hybrid of the implicit vectorization model and a DSL or language extension for vectorized code.
ISPC is noteworthy for the high performance that can be achieved by its generated native code. In "An Evaluation of Current SIMD Programming Models for C++" by Pohl et.al, ISPC ranked at the top of Mandelbrot benchmark results for C and C++ SIMD libraries.
The ISPC source distribution for Windows is a VS 2015 solution that comes with a bunch of MSVC examples that have built in timings using the CPU rdtsc timer. This makes it possible to directly compare the performance of vectorized algorithms implemented in ISPC and compiled to native code, versus implementations in .NET managed code that are JIT compiled at runtime by the RyuJIT compiler. This can give us a good idea of the performance of .NET Vector<T> vs. SIMD vectorization solutions in C and C++.
Benchmarks
I originally started the code for these benchmarks as a way to compare Vector<T> performance using arrays on the managed heap vs. arrays backed by unmanaged memory allocated by the jemalloc.NET native memory manager. FixedBuffer<T> is a data structure type provided by the high-level API of jemalloc.NET which is an array type of primitives backed by unmanaged memory that is not allocated on the .NET managed heaps, and satisfies certain constraints like zero-allocations or marshalling for interop with unmanaged code, avoiding 'struct tearing', and being correctly aligned for SIMD operations. I then became interested in how the performance of the .NET Core explicit vectorization types compared to SIMD libraries written in C or C++. If the performance was comparable, then it meant C# could be a viable choice for implementing real HPC applications without the need to link to native C or C++ libraries.
The low-level performance of .NET has been receiving a lot of love from Microsoft and the .NET Core development team in recent times. Work on jemalloc.NET was spurred by the recent work around Span<T>, Memory<T> and similar types by the .NET Core team. These recent additions to the .NET Core framework have been focused on improving low-level performance and memory utlilization with the goal being to make .NET operations on data more efficient and scalable on modern hardware and operating environments. The following paragraphs from the Span<T> design documents explain the motivations behind these changes:
Quote:
Span<T> is a small, but critical, building block for a much larger effort to provide .NET APIs to enable development of high scalability server applications.
The .NET Framework design philosophy has focused almost solely on productivity for developers writing application software. In addition, many of the Framework’s design decisions were made assuming Windows client-server applications circa 1999. This design philosophy is a big part of .NET’s success as .NET is universally viewed as a very high productivity platform.
But the landscape has shifted since our platform was conceived almost 20 years ago. We now target non-Windows operating systems, our developers write cloud hosted services demanding different tradeoffs than client-server applications, the state of the art patterns have moved away from once popular technologies like XML, UTF16, SOAP (to name a few), and the hardware running today’s software is very different than what was available 20 years ago.
When we analyze the gaps we have today and the requirements of today’s high scale servers, we realize that we need to provide modern no-copy, low-allocation, and UTF8 data transformation APIs that are efficient, reliable, and easy to use. Prototypes of such APIs are available in corefxlab repository, and Span<T> is one of the main fundamental building blocks for these APIs.
Frameworks like .NET must walk a line between enabling high performance applications while maintaining the productivity gains, and especially, the safety from certain classes of bugs that .NET developers love. Types like Span<T> are designed to allow you to access the memory that backs .NET objects and values by utilizing pointers, while still preserving a measure of safety against bugs like invalid memory references.
Additionally, the System.Runtime.CompilerServices.Unsafe library allows .NET developers to take more risks in the name of performance, by adding more framework support for directly addressing and manipulating memory. For instance, in the following debugger screenshot, notice how many instructions there are between the call to Unsafe.Read, and the cmp test:
The use of Unsafe.Read allows us to perform direct pointer arithmetic on data structures and then reinterpret an element span of a scalar array data structure as a vector data type without allocating memory. Notice also how the vectorized compare operation Vector<T>.LessThan() mapped directly onto the CPU instruction vpcmpgtd which is the AVX2 instruction for "Compare packed 32-bit integers in a and b for greater-than, and store the results in dst."
jembench
Using the jembench CLI program allowed me to quickly implement and iteratively compare different implementations of vectorized algorithms with a baseline serial algorithm implementation. jembench proved invaluable in the learning process because it was often the case that early attempts at vectorization failed miserably. Firing up the Visual Studio debugger and looking at the disassembly quickly showed me the error of my ways. jembench is built on the terrific BenchmarkDotNet library which provides accurate and customizable benchmarks for use cases like these. The combination of the jembench CLI runner and the Visual Studio debugger proved a very effective way to iteratively develop vectorized algorithms and immediately test their performance over baseline serial algorithms while comparing the machine code generated by RyuJIT.
Benchmark Code
ISPC
The main operation or kernel that will be used as a benchmark is the Mandelbrot set algorithm, which is a highly-parallel algorithm where each member of the set can be calculated independently from any other and which is often used as a benchmark for parallel operations. Here is the ISPC code for a vectorized Mandelbrot algorithm implementation from the examples folder that comes with the ISPC release:
export void mandelbrot_ispc(uniform float x0, uniform float y0,
uniform float x1, uniform float y1,
uniform int width, uniform int height,
uniform int maxIterations,
uniform int output[])
{
float dx = (x1 - x0) / width;
float dy = (y1 - y0) / height;
for (uniform int j = 0; j < height; j++) {
foreach (i = 0 ... width) {
float x = x0 + i * dx;
float y = y0 + j * dy;
int index = j * width + i;
output[index] = mandel(x, y, maxIterations);
}
}
}
static inline int mandel(float c_re, float c_im, int count) {
float z_re = c_re, z_im = c_im;
int i;
for (i = 0; i < count; ++i) {
if (z_re * z_re + z_im * z_im > 4.)
break;
float new_re = z_re*z_re - z_im*z_im;
float new_im = 2.f * z_re * z_im;
unmasked {
z_re = c_re + new_re;
z_im = c_im + new_im;
}
}
return i;
}
The code is similar to C with the addition of new keywords like uniform and new loop constructs like foreach. The key thing here is that the programmer does not have to explicitly express how to parallelize the operations across the vector registers of the CPU. By use of the foreach keyword the programmer signals to the ISPC compiler that the next statement block needs to be vectorized. The ISPC compiler will handle the implementation details based on information the programmer supplies in the code. The keyword uniform tells the compiler that this variable will vary in a uniform fashion and can be shared as a single value across all the parallel executing computations. This code is compiled into native code using the ISPC compiler The export keyword signals that the mandelbrot_ispc function will be exported as a library function that can be called from regular C code.
.NET
Let's look at a C# implementation of a Mandelbrot set plot:
private unsafe void _MandelbrotUnmanagedv5(ref FixedBuffer<int> output)
{
Vector2 C0 = new Vector2(-2, -1);
Vector2 C1 = new Vector2(1, 1);
Vector2 B = new Vector2(Mandelbrot_Width, Mandelbrot_Height);
Vector2 D = (C1 - C0) / B;
FixedBuffer<float> scanLine = new FixedBuffer<float>(Mandelbrot_Width);
for (int j = 0; j < Mandelbrot_Height; j++)
{
for (int x = 0; x < Mandelbrot_Width; x++)
{
float px = C0.X + (D.X * (x));
scanLine.Write(x, ref px);
}
Vector<float> Vim = new Vector<float>(C0.Y + (D.Y * j));
for (int h = 0; h < Mandelbrot_Width; h += VectorWidth)
{
int index = j * Mandelbrot_Width + h;
Vector<float> Vre = scanLine.Read<Vector<float>>(h);
Vector<int> outputVector = GetByte(ref Vre, ref Vim, 256);
output.Write(index, ref outputVector);
}
}
scanLine.Free();
return;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
Vector<int> GetByte(ref Vector<float> Cre, ref Vector<float> Cim, int max_iterations)
{
Vector<float> Zre = Cre;
Vector<float> Zim = Cim;
Vector<int> MaxIterations = new Vector<int>(max_iterations);
Vector<int> Increment = One;
Vector<int> I;
for (I = Zero; Increment != Zero; I += Vector.Abs(Increment))
{
Vector<float> S = SquareAbs(Zre, Zim);
Increment = Vector.LessThanOrEqual(S, Limit) & Vector.LessThan(I, MaxIterations);
if (Increment.Equals(Zero))
{
break;
}
else
{
Vector<float> Tre = Zre;
Zre = Cre + (Zre * Zre - Zim * Zim);
Zim = Cim + 2f * Tre * Zim;
}
}
return I;
}
GetByte is the equivalent of the mandel function in the ISPC code. In this implementation, we use a FixedBuffer<float> array to represent each scan-line and the entire Mandelbrot plot as an array of floats. We can re-interpret segments of floats as Vector<float>s using the Read<T>() and Write<T>() methods to load SIMD vector registers and execute operations in parallel. We use execution masks to mask off the elements of the current vector that we are finished processing. The C# code is much more verbose than the ISPC code due to the need to explicitly declare variables as vector types and marshal data to and from scalar arrays to vector registers and set execution masks and so on.
Benchmark Setup
.NET
The Mandelbrot operation will be implemented in two ways: a serial version which serves as the benchmark baseline, and a vectorized/parallel version. Vectorized operations are parametrized by the Scale factor which determines how large the Mandelbrot set plot area is. Different parallel implementations use single- or multi-threaded operations which utilize the .NET Task Parallel Library for concurrency support. Operations are also compared between 2 kinds of memory: .NET managed arrays and jemalloc.NET FixedBuffer<T> arrays.
The benchmark runs are timed using the default BenchmarkDotNet timers and also by the CPU TSC. The TSC values are obtained from the Win32 API function QueryThreadCycleTime(). This allows us to directly compare results from the .NET benchmarks with the ISPC benchmarks. The results of the ISPC benchmark are run separately and inserted as a column into the BenchmarkDotNet results.
Every benchmark has a validation step that validates the algorithm ran correctly and produced the correct results. The output of all the different Mandelbrot algorithm versions are compared to the baseline serial version and an exception is thrown if the arrays are not equal. Each Mandelbrot implementation also produces a bitmap in .PPM format that can be used to visually validate that the Mandelbrot operation completed successfully,
Every .NET benchmark described here can be run from the included jembench CLI program. E.g: jembench vector --mandel 3 will run the Mandelbrot benchmarks at a scale factor of 3x.
ISPC
The ISPC Mandelbrot benchmark also has a serial and a vectorized version and is also parameterized by scale. The benchmark is timed using the __rdtsc MSVC intrinsic. The program also produces a bitmap as output so you can visually validate that the algorithm ran successfully and is identical to the .NET program output. You can start a benchmark run from the command-line using: mandelbrot --scale=1 25 25 The ISPC examples also include a multi-threaded vectorized version which is invoked from the command-line with the mandelbrot_tasks command.
Test Hardware
I used 2 machines for running the benchmarks. As these benchmarks only measure CPU calculations on a small in-memory set of x-y co-ordinates, the only relevant hardware spec for this benchmark is the CPU type:
- Intel Core i7-6700HQ CPU 2.60GHz (Skylake). This is a relatively recent Intel processor with support for AVX2 instructions.
- 2 x Intel Xeon CPU X5650 2.67GHz. The Xeon X5650 is an older CPU that only supports SSE4.2 with no AVX extensions. However, it makes up for this by having 6 physical cores, which in a dual CPU system gives 12 physical cores in contrast to the 4 physical cores of the Skylake processor.
We'd expect the Xeon chip to fare much better in the multi-threaded test with the Skylake chip performing better in the single-threaded tests.
Results
- 1 M = 1 million CPU cycles as timed by the CPU TSC.
- 1 G = 1 billion CPU cycles as timed by the CPU TSC.
- Scale x1 bitmap size = 768 * 512 = .4 M pixels
- Scale x3 bitmap size = 768 * 512 * 32 = 3.5M pixels
- Scale x3 bitmap size = 768 * 512 * 33 = 14M pixels
Test Machine 1 (AVX2)
ISPC @ Scale x1,x3,x6
| | Single-threaded serial | Single-threaded vectorized | Multi-threaded vectorized | Single-threaded vector speedup | Multi-threaded vector speedup |
| Scale x1 | 328 M | 26.8 M | 5.6 M | 12x | 59x |
| Scale x3 | 2971 M | 236 M | 48.2 M | 12x | 62x |
| Scale x6 | 11.9 G | 940 M | 196.26 | 12.6x | 60x |
.NET @ Scale x1,x3,x6
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=Throughput
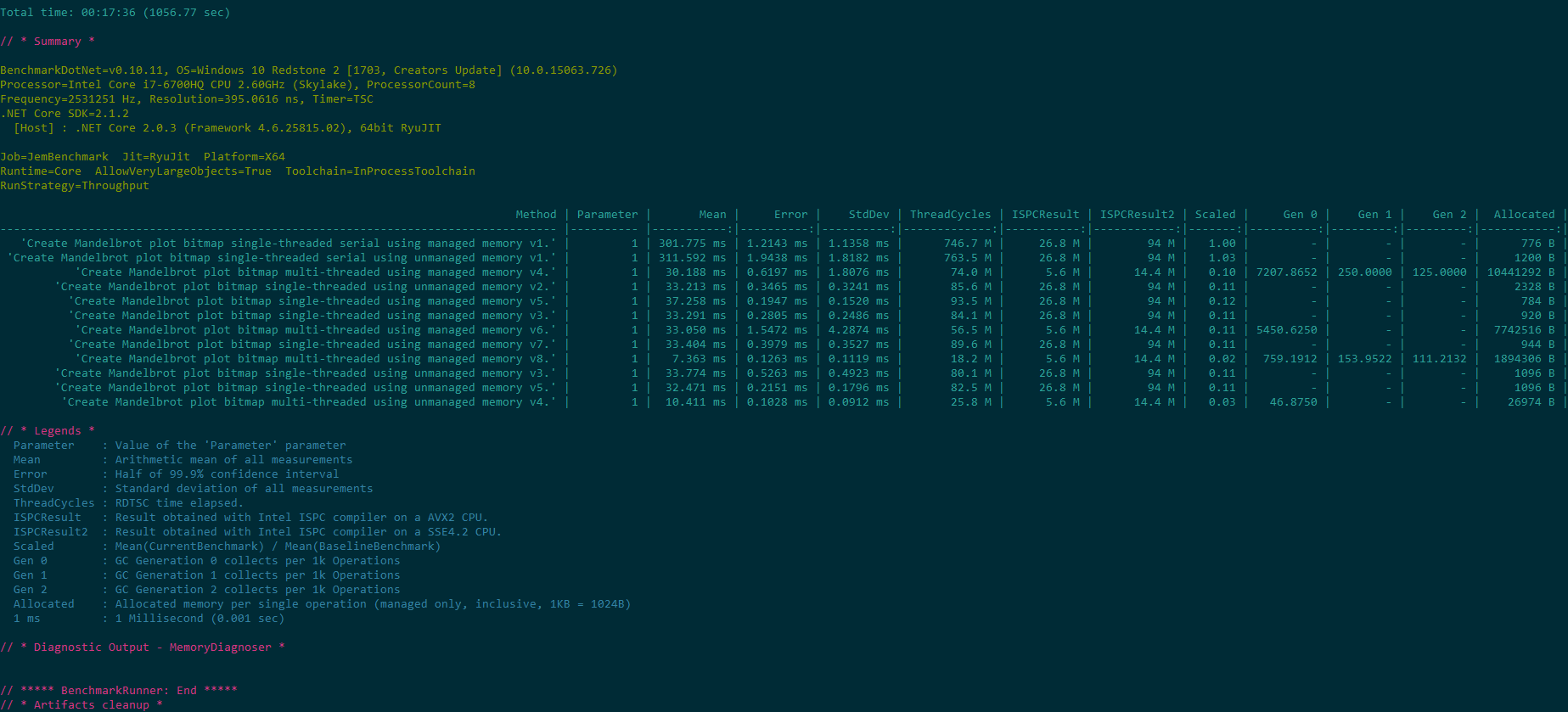
| Method | Parameter | Mean | Error | StdDev | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | Gen 0 | Gen 1 | Gen 2 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 1 | 301.775 ms | 1.2143 ms | 1.1358 ms | 746.7 M | 26.8 M | 94 M | 1.00 | - | - | - | 776 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 1 | 311.592 ms | 1.9438 ms | 1.8182 ms | 763.5 M | 26.8 M | 94 M | 1.03 | - | - | - | 1200 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 1 | 33.404 ms | 0.3979 ms | 0.3527 ms | 89.6 M | 26.8 M | 94 M | 0.11 | - | - | - | 944 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 1 | 7.363 ms | 0.1263 ms | 0.1119 ms | 18.2 M | 5.6 M | 14.4 M | 0.02 | 759.1912 | 153.9522 | 111.2132 | 1894306 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 1 | 32.471 ms | 0.2151 ms | 0.1796 ms | 82.5 M | 26.8 M | 94 M | 0.11 | - | - | - | 1096 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 1 | 10.411 ms | 0.1028 ms | 0.0912 ms | 25.8 M | 5.6 M | 14.4 M | 0.03 | 46.8750 | - | - | 26974 B |
| Method | Parameter | Mean | Error | StdDev | Median | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | ScaledSD | Gen 0 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 3 | 2,737.59 ms | 40.764 ms | 38.130 ms | 2,728.30 ms | 6.5 G | 236 M | 819.5 M | 1.00 | 0.00 | - | 768 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 3 | 2,780.78 ms | 33.610 ms | 31.439 ms | 2,768.50 ms | 6.7 G | 236 M | 819.5 M | 1.02 | 0.02 | - | 1195 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 3 | 293.73 ms | 5.656 ms | 8.465 ms | 293.95 ms | 689.4 M | 236 M | 819.5 M | 0.11 | 0.00 | - | 944 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 3 | 57.84 ms | 1.133 ms | 2.209 ms | 57.58 ms | 144.3 M | 48.2M | 61.6 M | 0.02 | 0.00 | 4000.0000 | 16967131 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 3 | 273.98 ms | 5.428 ms | 9.363 ms | 277.00 ms | 679.0 M | 236 M | 819.5 M | 0.10 | 0.00 | - | 1099 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 3 | 72.32 ms | 1.415 ms | 1.453 ms | 72.13 ms | 169.6 M | 48.2M | 61.6 M | 0.03 | 0.00 | - | 82613 B |
| Method | Parameter | Mean | Error | StdDev | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | Gen 0 | Gen 1 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 6 | 10,846.5 ms | 53.641 ms | 50.176 ms | 26.1 G | 940 M | 3.3 G | 1.00 | - | - | 776 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 6 | 11,116.5 ms | 66.343 ms | 62.057 ms | 26.9 G | 940 M | 3.3 G | 1.02 | - | - | 1203 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 6 | 1,112.2 ms | 21.838 ms | 29.153 ms | 2.7 G | 940 M | 3.3 G | 0.10 | - | - | 936 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 6 | 230.4 ms | 4.511 ms | 7.022 ms | 546.4 M | 196.2M | 244.6 M | 0.02 | 17957.4468 | 148.9362 | 66783734 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 6 | 1,094.5 ms | 21.365 ms | 39.067 ms | 2.6 G | 940 M | 3.3 G | 0.10 | - | - | 1090 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 6 | 274.8 ms | 1.516 ms | 1.418 ms | 601.8 M | 196.2M | 244.6 M | 0.03 | - | - | 138660 B |
Test Machine 2 (SSE4.2)
ISPC @ Scale x1,x3,x6
| | Single-threaded serial | Single-threaded vectorized | Multi-threaded vectorized | Single-threaded vector speedup | Multi-threaded vector speedup |
| Scale x1 | 295 M | 95 M | 7.3 M | 3x | 42x |
| Scale x3 | 2663.3 M | 819.5 M | 61.6 M | 3x | 43x |
| Scale x6 | 10.8 G | 3.3 G | 244.6 M | 3x | 44x |
.NET @ Scale x1,x3,x6
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 1 [1607, Anniversary Update] (10.0.14393.1944)
Processor=Intel Xeon CPU X5650 2.67GHz, ProcessorCount=24
Frequency=2597656 Hz, Resolution=384.9624 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=ColdStart
| Method | Parameter | Mean | Error | StdDev | Median | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | ScaledSD | Gen 0 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 1 | 362.379 ms | 6.9952 ms | 7.485 ms | 361.012 ms | 898.4 M | 26.8 M | 95 M | 1.00 | 0.00 | - | 776 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 1 | 373.978 ms | 5.1484 ms | 4.816 ms | 372.067 ms | 904.1 M | 26.8 M | 95 M | 1.03 | 0.02 | - | 1203 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 1 | 59.493 ms | 1.1786 ms | 1.835 ms | 59.320 ms | 149.6 M | 26.8 M | 95 M | 0.16 | 0.01 | - | 912 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 1 | 6.324 ms | 0.5008 ms | 1.477 ms | 5.965 ms | 9.1 M | 5.6 M | 7.3 M | 0.02 | 0.00 | - | 1732035 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 1 | 58.324 ms | 1.1369 ms | 2.021 ms | 58.082 ms | 141.3 M | 26.8 M | 95 M | 0.16 | 0.01 | - | 1098 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 1 | 8.376 ms | 0.5052 ms | 1.490 ms | 7.840 ms | 16.1 M | 5.6 M | 7.3 M | 0.02 | 0.00 | - | 13147 B
|
| Method | Parameter | Mean | Error | StdDev | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | ScaledSD | Gen 0 | Gen 1 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 3 | 3,229.10 ms | 47.5660 ms | 44.493 ms | 7.9 G | 236 M | 819.5 M | 1.00 | 0.00 | - | - | 768 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 3 | 3,241.58 ms | 32.4737 ms | 30.376 ms | 8.2 G | 236 M | 819.5 M | 1.00 | 0.02 | - | - | 1195 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 3 | 518.36 ms | 10.3181 ms | 13.049 ms | 1.2 G | 236 M | 819.5 M | 0.16 | 0.00 | - | - | 904 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 3 | 43.42 ms | 0.8537 ms | 1.801 ms | 88.3 M | 48.2M | 61.6 M | 0.01 | 0.00 | 2000.0000 | - | 15217779 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 3 | 511.90 ms | 2.6393 ms | 2.469 ms | 1.3 G | 236 M | 819.5 M | 0.16 | 0.00 | - | - | 1091 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 3 | 55.52 ms | 1.0988 ms | 2.009 ms | 137.9 M | 48.2M | 61.6 M | 0.02 | 0.00 | - | - | 32816 B |
| Method | Parameter | Mean | Error | StdDev | ThreadCycles | ISPCResult | ISPCResult2 | Scaled | Gen 0 | Gen 1 | Allocated |
| 'Create Mandelbrot plot bitmap single-threaded serial using managed memory v1.' | 6 | 12,802.5 ms | 111.763 ms | 104.543 ms | 31.6 G | 940 M | 3.3 G | 1.00 | - | - | 776 B |
| 'Create Mandelbrot plot bitmap single-threaded serial using unmanaged memory v1.' | 6 | 12,976.0 ms | 119.839 ms | 112.098 ms | 32.0 G | 940 M | 3.3 G | 1.01 | - | - | 1203 B |
| 'Create Mandelbrot plot bitmap single-threaded using managed memory v7.' | 6 | 2,018.6 ms | 13.527 ms | 12.653 ms | 5.3 G | 940 M | 3.3 G | 0.16 | - | - | 904 B |
| 'Create Mandelbrot plot bitmap multi-threaded using managed memory v8.' | 6 | 168.7 ms | 3.318 ms | 3.104 ms | 371.3 M | 196.2M | 244.6 M | 0.01 | 9000.0000 | 3000.0000 | 60010046 B |
| 'Create Mandelbrot plot bitmap single-threaded using unmanaged memory v5.' | 6 | 1,985.7 ms | 17.230 ms | 16.117 ms | 5.1 G | 940 M | 3.3 G | 0.16 | - | - | 1091 B |
| 'Create Mandelbrot plot bitmap multi-threaded using unmanaged memory v4.' | 6 | 209.2 ms | 4.043 ms | 3.781 ms | 535.0 M | 196.2M | 244.6 M | 0.02 | - | - | 71691 B |
Analysis and Discussion
The first thing we observe is that the ThreadCycles TSC values match up with the BenchmarkDotNet times: e.g., for Test Machine 1 in the first .NET benchmark 2.5 Ghz * .3 s ~= 750 M CPU cycles so direct comparison between the ISPC results and .NET results should be accurate. These benchmark numbers are theoretical based on the highly data-parallel Mandelbrot kernel, but they do give a good idea of what is theoretically possible for the software and a target to aim at during optimization attempts.
Generally on the Skylake processor AVX2 support provided about 12x acceleration for single-threaded ISPC compiled programs and about 9x acceleration for single-threaded .NET Core programs using Vector<T>. Multi-threaded ISPC programs were able to utilize more of the 8 logical cores of the Skylake processor to yield about 60x acceleration. Multithreaded vectorized .NET Core programs utilizing AVX2 were able to achieve a 50x improvement over the serial implementations. Multi-threaded acceleration on the dual SSE CPUs system was quite good yielding in some cases almost 60x acceleration over the serial implementation.
As expected single-threaded performance on the SSE4.2 processor was a lot slower than the AVX2 processor. However on the multi-threaded tests the SSE system was able to utilize the 24 logical cores available to close the gap between the 2 processors.
Unmanaged FixedBuffer<T> arrays were generally slower than managed arrays in these benchmarks. The unmanaged arrays must incur the overhead of repeatedly freeing the memory that was allocated during the benchmark runs, whereas .NET managed arrays that are allocated can simply wait for the next GC cycle. The benefits of FixedBuffer<T> and other data structures from the high-level API really kick in at the scale of millions and tens of millions of elements where fragmentation of the LOH will lower performance of managed heap objects, or when interop with native code libraries must be done.
In Pohl et.al benchmarks were done on native code SIMD libraries using the Mandelbrot kernel on an Intel i7-4770 processor with AVX2 support. .NET Core performance in the benchmarks presented here would rank it among the lower-performing C++ SIMD libraries like gSIMD and Sierra. Vectorized.NET Core programs are about 3x slower than the ISPC compiled native code programs. However, vectorized .NET Core code is still a lot faster than serial native code. E.g., at scale x3, single-threaded NET Core vectorized code using AVX2 is 4x faster than the serial native code equivalent. This means that one could write HPC programs in .NET if the productivity gains of using a high-level framework and language outweighed the cost and effort of developing native code programs. Use of the .NET Task Parallel Library together with Vector<T> yielded a more than 17x improvement over single-threaded serial native code at scale x3. At scale x6 with a bitmap size of about 14M pixels, multi-threaded .NET Core vectorized code for AVX2 was .5x faster than ISPC single-threaded vectorized code. The performance gap between multi-threaded vectorized managed code and single threaded serial native code on the SSE system is even larger.
The ability to use high-level types and programming models for data parallelism and concurrency can make .NET a appealing choice for developing high-performance applications. Integrating native code libraries into .NET code for the sake of performance is not guaranteed to yield the benefits of native code optimization unless the custom code itself is also optimized. With the high-level programming models in .NET for SIMD, concurrency I/O, database access, network programming, and many other kinds of operations, developers could choose to develop all their HPC code in .NET and avoid incurring the cost and effort of integrating low-level native code into their applications.
Conclusion
The low-level features added to .NET Core for efficient memory access combined with high-level programming models like the TPL and Vector<T> make .NET Core a feasible choice for developing applications or components that require high performance.

