TorpedoSync (works on pi and ubuntu) takes a different approach to other file sync applications like resilio and syncthing in that it does not compute a cryptographic hash for each file and consequently is much faster and uses less CPU cycles
Introduction
They say that "necessity is the mother of invention", well necessity and sometimes an itch to do the same yourself. This is how TorpedoSync came about, from the use of other software to sync "My Documents" across my machines and finding them troubling. Hence the immortal cry "I can do better!".
I start out by using bitsync which then became resilio sync (a free-mium product) which I liked at first but then became a real memory and disk space hog.
After searching a lot, I came across syncthing which is open source and written in go, which I found seemed to be connecting to the internet and was not as nice to use as resilio.
At this point I gave up and decided to write my own.
The source code can be found on github also at : https://github.com/mgholam/TorpedoSync
Main Features
TorpedoSync has the following features:
- Sync folders between computers in a local network
- Safe by default : changed and deleted files are first copied to the "archive" folder
- Based on .net 4 : so it will work on old Windows XP computers, good for backup machines.
- Built-in Web UI
- Run as a console app or as a Service
- Single small EXE file to copy deploy
- No database required
- Minimal memory usage
- Ability to zip copy small files : for better network roundtrip performance (syncing pesky folders like
node_modules ) - Read Only shares : one way syncing data from master to client
- Read Write shares : two way syncing
- Ignorable files and folders
- Raspberry Pi support
- Linux support
Installation
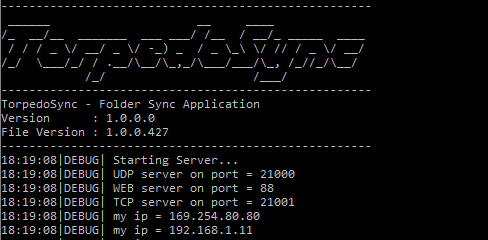
To run TorpedoSync just execute the file and it will start up and bring up the Web UI in your browser.
Alternatively you can install TorpedoSync as a windows service via torpedosync.exe /i and uninstall it with torpedosync.exe /u
Working with TorpedoSync
On the machine that you want to share a folder from, click on the add button under the shares tab:

Enter the required values, and optionally copy one of the tokens you want other machines to connect to.
On the client machines, open the connections tab and click on the connect to button:
Enter the required values and save, the client will wait for confirmation from the master:
Click on the confirm button under the connections list and the machine name of the client, after which the client will start syncing.
To see the progress you can click on the connection share name to see the connection information or you can switch to the logs tab.
You can view and change the TorpedoSync configuration via the settings tab
The Differences to Competitors
Torpedosync takes a different approach to other file sync applications like resilio and syncthing in that it does not compute a cryptographic hash for each file and consequently is much faster and uses less CPU cycles.
No relational database is used to store the file information, so again the performance is higher and the storage is much smaller.
TorpedoSync only works in a local network environment and does not sync across the internet, so you are potentially much safer, and your data is contained to your own network.
Definitions
To understand what is implemented in TorpedoSync you must be familiar with the following definitions:
- Share : is the folder you want to share
- State : is the list of files and folders for a share
- Delta : is the result of comparing states for which you get a list of Added, Deleted, Changed files and Deleted folders
- Queue : is the list of files to download for a delta
- Connection
- Master machine : is the computer which defined the share and the delta computation happens even in read/write mode
- Client machine : is the computer connecting to a master which initiates a sync
Sync Rules
- Master is the machine that defined the "share"
- Defaults to move older or deleted files to "old" folder for backup
- First time sync for Read/Write mode will copy all files to both ends
- Only clients initiate a sync even in read/write mode
- Delta processing is done on the master
- if OLDER or LOCKED -> put in error queue and skip to retry later in another sync
- if NOTFOUND -> put in error queue
How it works
For sync to work, machines on both ends of the connection should be roughly time synchronized, especially when 2 way or read write syncing if performed.
In the case of syncing My Documents between your own machines then this is not very important since you would not be changing files at the same time on both machines. If this does happen then you can recover your files from the .ts\old folder in your share directory.
As stated you have 2 types of synchronization, read only and read/write.
Read only / 1 way Sync
The client in this mode does the following :
- Generates a
State for the folder, i.e. getting a list of files and folders for the share. - Sends this
State to the server and waits for a Delta from the server. - Given the deleted files and deleted folders in the
Delta it will move them to .ts\old. - Given the added and changed files in the
Delta it will queue them for downloading.
The server in this mode does the following:
- Waits for a
State from a client. - Get the current
State of the share. - Computes a
Delta for the client based on the 2 states above and sends to the client.
Read Write / 2 way Sync
The client in this mode does the following :
- Generates a
State for the folder, i.e. getting a list of files and folders for the share. - Creates a
Delta from the above state and the last stored State if it exists. - Clears the added and changed files in the above
Delta. - Sends the current
State and the Delta to the server and waits for a Delta from the server. - Given the deleted files and deleted folders in the
Delta it will move them to .ts\old. - Given the added and changed files in the
Delta it will queue them for downloading.
The server in this mode does the following:
- Removes the files defined in
Delta sent from the client. - Compares the current
State and the last saved State on the master to create a Delta deleted files and folders for the client. - Process the client
State with the master State for the changed and added Delta for the master - Process the master
State with the client State for the changed and added Delta for the client. - Return the client
Delta to the client. - Queue the master
Delta on the master for downloading.
Downloading files
Once a Delta is generated, deleted files and folders defined in it are moved to .ts\old under the exact folder structure of the original files and the added and changed files are queued for downloading.
The downloader process the queue in one of two ways:
- If the files in the queue are smaller than 200kb (a configuration) and the total size of these files are less than 100mb (another configuration) they are grouped together and downloaded as a zip file from the master, this is for better roundtrip performance of smaller files.
- If the file is larger than 200kb, it is downloaded individually and chunked in 10mb blocks.
The download block size is configurable and should reflect the bandwidth of the network connection, i.e. for wired networks 10mb should be fine, and for wireless networks 1mb would be better (1 block per second).
The download outcome can be one of the following:
- Ok : the data is ok and written to disk.
- Not found : the requested file was not found on the master, and is ignored.
- Older : the file on the master is older than the one requested, the request is put on the error queue.
- Locked : the file on the master is locked and can not be downloaded, the request is put on the error queue.
The error queue is no more than a container for failed files and reset, since the files in question will probably be in the next sync anyway.
The internals
The source code is composed of the following:
| Class | Description |
| TorpedoSyncServer | The main class that loads every thing and processes TCP requests |
| TorpedoWeb | The Web API handler derived from CoreWebServer |
| ServerCommands | Static class for server side handling of TCP requests like syncing and zip creation etc. |
| ClientCommands | Static class for sending TCP client request |
| CoreWebServer | Web server code based on HttpListener designed as an abstract class |
| DeltaProcessor | Static class for State and Deltahandling and computation |
| QueueProcessor | The main class which handles a share connection, queueing downloads, downloading files and new sync initialization |
| UDP | Contains the UDP network discovery code which maintains the currently connected machine addresses |
| NetworkClient, NetworkServer | Modified TCP code from RaptorDB for lower memory usage |
| Globals | Global configuration settings |
The files and folders
Once a Share is created on the master, TorpedoSync creates a .ts folder in that shared folder for "old archive" files which is named old. Also in the .ts folder there is a file named .ignore which you can use to define what files and folders to ignore in the sync process ( i.e. will not be transferred).
Besides the EXE, TorpedoSync creates a log folder for logs and a Computers folder for connection information. Inside the Computers folder a folder is created for each connected machine which will be the machines name, which stores the state, config and download queue for each share that that computer is connected to.
.ignore file
Within the share folder inside the special .ts directory you have this special file which contains the list of files and folder you want to ignore when syncing, each line is a ignore item which follows the rules below:
# anything after in the line is a comment* or ? in the line indicates a wildcard which will be applied to match filenames\ in the line indicates a directory separator character- anything else will match the path
For example:
# comment line
obj # any files and folder under 'obj'
*.suo # any file ending in .suo
code\cache # any files and folder inside 'code\cache'
settings.config file
The settings.config file resides beside the TorpedoSync EXE file and stores the following configuration parameters in a json format:
| Parameter | Description |
| UDPPort | UDP port for network discovery (default 21000) |
| TCPPort | TCP port for syncing (default 21001) |
| WebPort | Web UI port (default 88) |
| LocalOnlyWeb | Web UI only accessible on the same machine (default true) |
| DownloadBlockSizeMB | Breakup block size for downloading files, i.e. if you are on a wireless network set this to 1 to match the transfer rate of the medium (default 10) |
| BatchZip | Batch zip download files (default true) |
| BatchZipFilesUnderMB | Batch zip download files if total size under this value (default 100) |
| StartWebUI | Start the Web UI if running from the console (default true) |
sharename.config file
This file stores the configuration for the share connections in a JSON format:
| Parameter | Description |
| Name | Name of the share |
| Path | Local path to the share folder |
| MachineName | Machine name to connect to |
| Token | Token for the share |
| isConfirmed | On the master this value indicates that the share is confirmed and ready to send data |
| ReadOnly | Indicates that this share is read only |
| isPaused | If this share connection is paused |
| isClient | if this share connection is a client |
sharename.state file
In 2-way read/write mode, this file stores the last list of files and folders form which TorpedoSync derives which files and folders were deleted since the last sync process.
If this file does not exist (i.e. first time sync), then TorpedoSync assumes that it is the first time and all missing files are transferred to both ends of the connection (no missing files and folders are deleted on both ends of the connection).
This file is in a binary json format.
sharename.queue and .queueerror files
These files store the files which should be downloaded from the other machine, and the list of failed download files.
These files are in a binary json format.
sharename.info file
These files store the share statistics and metrics information, and are in binary json format.
The Development Process
TorpedoSync repurposed some code from RaptorDB which I initially included raptordb.common.dll, but then decided to copy the code to the solution so I get one EXE to deploy which makes things easier for users.
The project is divided into two parts:
- The main c# code
- The Web UI which builds to a folder in the main code folder
The Web UI is built using vue.js.
So you must have the following to compile the source code:
- Visual Studio 2017 ( I use the community edition)
- Visual Studio Code
- node and npm
-
npm install in the WebUI folder
You can compile the c# code in Visual Studio.
You can debug the Web UI by running WebUI\run.cmd which will startup a node development server for debugging and fast code compilation in webpack.
After you are good with the UI code you do the following :
- WebUI\build.cmd to build a production version of the UI
- WebUI\deploy.cmd to copy the production files to the c# source folder
- Rebuild the c# solution to include the UI code
The pains
The following are a highlight of the pain points when writing this project.
Long filenames
While Windows supports long filenames (>260 characters), .net seems to be lacking in this area (especially .net 4). These files especially arise when working with node_modules folders which nest very deep and frequently go over the 260 character limit.
To handle this there are special longfile.cs and longdirectory.cs source files which use the underling OS directly.
One other pain point I encountered was that even Path.GetDirectoryName() suffers from this so I had to write a string parser to handle it.
UDP response from multiple machines
My initial UDP code didn't seem to get responses from all other machines in the network, which really took me a long time to figure out, the problem being, I was closing the UDP connection and not getting all the responses in the stream.
So the solution was to stay in a while loop and process not just the first response but any other responses or time out.
Brain dead dates in the zip format
Now this one took a long long time to figure out, and the problem started when the 2 way sync was downloading files that seemed to have already been downloaded and worst seemed to be going back to the master in a loop.
After much head scratching the problem seemed to be seen when the batch zip feature was used and going through the code by Jaime Olivares I found this gem in the comments :
DOS Date and time:
MS-DOS date. The date is a packed value with the following format. Bits Description
0-4 Day of the month (1..31)
5-8 Month (1 = January, 2 = February, and so on)
9-15 Year offset from 1980 (add 1980 to get actual year)
MS-DOS time. The time is a packed value with the following format. Bits Description
0-4 Second divided by 2
5-10 Minute (0..59)
11-15 Hour (0..23 on a 24-hour clock)
The problem being the seconds are divided by 2 when stored. After much research, I found this was a limitation of FAT in MSDOS back in the day and was carried through to today in the original zip format, later extensions to zip support the full date time, but unfortunately the code from Jaime didn't have this but it did have a comment section for each file zipped and I used that to store the date time for each file until Jaime gets round to supporting the extended zip headers.
Webpack
I'm not a web developer, and I'm recently getting into it, so figuring out webpack and npm was tricky for me especially the build process, which takes a long time. Also configuring Webpack for special functionality is really hard and frustrating since I always get errors from the snippets I found on the web, so I basically gave up for the most part.
After some time I found out that if you npm run dev the code you get hot code changes in your browser and the development cycle is much shorter and nicer (i.e. you don't have to build after each code change and wait and wait...)
The problem with npm run dev is that the web code runs on port 8080 and my server runs on port 88 so I came up with the following workaround in the debug.js file :
import './main.js'
window.ServerURL = "http://localhost:88/";
This sets a variable to my own web server in the c# code, and in the production build I ignore it and just package the main.js file so the webpack.config.js has the following:
var path = require('path')
var webpack = require('webpack')
module.exports = {
entry: './src/debug.js',
...
if (process.env.NODE_ENV === 'production') {
module.exports.entry = './src/main.js'
module.exports.devtool = '#source-map'
...
The only problem I encountered with this approach is that I can't POST json to my server and I get CORS (cross origin resource sharing) errors in the browser and my request don't make it to my server in developer mode.
While I only had 1 point in the code which I posted data here and I could work around it, in a larger project this will be a problem, so a better solution is needed.
The pleasures
The following are a list of what I enjoyed using while working on this project.
Visual Studio Code
At first I used Visual Studio Community 2017 for the Web UI code, but I found that the vue.js support was lacking and not very helpful. So I decided to use Visual Studio Code with the help of some extensions for vue.js, and I have to say that it is phenomenal and very enjoyable.
The general usability and productivity is very high and I absolutely recommend it for web development.
Vue.js
After getting webpack working and support for compiling .vue files in place I have to say that vue.js is outstanding and simple to code by (.vue files are a great help and simplify the development process).
I shopped around a lot for a "framework" and found vue.js powerful and most importantly simple to learn and use for someone who has never worked in JavaScript. I also looked at angular.js but I found that too complex and difficult.
Appendix v1.1 - pi and ubuntu
The refactoring of the code is done and TorpedoSync can now run on the raspberry pi and on the Ubuntu OS. The above animated gif in on my pi b2+ which is syncing data from my development machine running Win 10.
To run TorpedoSync on pi and Ubuntu you must install mono with the following command, the EXE file is the same that runs on Windows.
sudo apt-get install mono-complete
Appendix v1.2 - npm3
I recently came upon npm3 which is a newer version and has the ability to optimize the dependancy for the web ui project and in doing so my node_modules folder size came down from 76Mb to around 56Mb saving me 20Mb.
So I switched the build and run scripts accordingly (the usage is the same just add a 3 to the end).
Appendix v1.5.0 - Parcel Packager
With regular notifications from GitHub regarding security vulnerabilities in some javascript libraries in the node modules for TorpedoSync's web UI, I decided to upgrade webpack from v3 to v4, and what a pain that was, the build scripts failed and trying to fix it was beyond me, given that the scripts were mostly scrounged around from various sources and were beyond me in the first place.
Frustrated by the overly complex webpack packager, I searched around and came across the parcel packager (link) which was simple and without configuration and mostly did what I wanted out of the box.
The only problem I have with parcel is that it appends a hash value to the filename of the outputs, in the documentation it states that this is for the use of content delivery networks, I haven't been able to turn this off and it seems you can't.
This name mangling is a pain when trying to embed the files in TorpedoSync since you have to edit the project file each time it changes.
Other than the above, everything else is wonderful with parcel and I like it a lot since I don't have to fiddle with knobs and configurations.
Appendix v1.6.0 -Rewrite the Web UI in Svelte
Continuing my love affair with svelte which started with rewriting the RaptorDB Web UI, I decided to do the same with TorpedoSync. While the structure and mentality of vue and svelte are similar, the process of converting required me to create some svelte components from scratch (I could not find while searching). These components were:
- Movable/resizable modal forms
- A message box replacement for sweet alert, I'm quite proud of the message box control because it is tiny, powerful and really easy to use.
- It supports Ok, Ok/Cancel, Yes/No, single line input, multi line input and progress spinner.
The result is quite remarkable :
- vue distribution build :
- js size = 147 kb
- total size = 201 kb
- svelte distribution build :
- js size = 83 kb
- total size = 91 kb
Some of the highlights:
- I changed the icons from glyphicons font to svg font awesome component. While the overall size of the output was smaller it is not really a good option if you have a lot of icons in your app (the 14 icons used took ~13kb of space while the entire glyph font is ~23kb).
- The node_modules for the svelte project is approximately half the size of vue even with the font awesome icons.
- The rollup javascript packager while not configuration free like parcel (it has a manageable config file) is only 4mb on disk compared to nearly 100mb for parcel.
- I changed the CSS colours scattered around the source files to use the global CSS var() which allows for themes and on the fly colour changes (currently disabled in the UI).
Previous Releases
You can download previous version here:
History
- Initial Release : 17th January 2018
- Update v1.1 : 6th February 2018
- code refactoring
- working with mono on pi and ubuntu
- Update v1.2 : 14th February 2018
- bug fix web page refresh extracting server address
GetServerIP() retry logic- changed build run scripts for
npm3
- Update v1.3 : 2nd July 2018
- streamlined tcp network code
- removed retry if master returned null -> redo in next sync (edge case queue stuck and not syncing)
- check if file exists when ziping (no more exceptions in logs)
- Update v1.5.0 :
- moved to using parcel packager instead of webpack
- updated to new zipstorer.cs
- Update v1.6.0 : 20th August 2019
- rewritten the web ui with svelte
- Update v1.7.0 : 10th December 2019
- WEBUI: refactored tabs out of app into own component
- upgrade to fastJSON v2.3.1
- upgrade to fastBinaryJSON v1.6.1
- bug fix zipstorer.cs default not utf8 encoding
- added deleting empty folders
- updated npm packages
- Update v1.7.5 : 18th February 2020
- updated npm packages
- added support for env path variables (%LocalAppData% etc.)
- Update v1.7.6 : 23rd May 2020
- WEBUI using fetch()
- js code cleanup
- modal form default slot error
- network retry logic (thanks to ozz-project)

