Every public corporation in America is required to submit reports to the US Securities and Exchange Commission (SEC). The SEC makes many of these reports freely available through its Electronic Data Gathering, Analysis, and Retrieval system, better known as EDGAR. EDGAR provides a wealth of information for investors, and you can access the main site at https://www.sec.gov/edgar.shtml.
EDGAR provides a vast amount of data, but the documentation isn't particularly clear. In writing this article, my goal is to present a number of reports provided by EDGAR and the different methods available for accessing them.
1. Overview of EDGAR
EDGAR ended FTP support in 2016, and to the best of my knowledge, it doesn't provide report data through web services. To access reports, you need to submit an HTTPS request to a URL that starts with https://www.sec.gov/cgi-bin/browse-edgar?. I'll refer to this as the EDGAR URL.
To specify which reports you're interested in, you need to append a query string to the URL that provides the following information:
- The corporation's identifier (
CIK) - The type of the report (
type) - The prior-to date (
dateb) - The number of reports (
count) - Ownership (
owner)
For example, suppose you'd like to download IBM's annual reports before 2015. IBM's identifier is 0000051143 and annual reports are denoted by 10-K, so you'd send a request to the following URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0000051143&type=10-K&dateb=20150101&count=10&owner=exclude
As shown, the URL's query string consists of name=value pairs separated by the & symbol. The first pair, action=getcompany, identifies the goal of the EDGAR search. The rest of this section explores the remaining name=value pairs that you can set in the query string.
1.1 Central Index Keys (CIKs)
The SEC assigns a unique identifier to every company or individual that submits reports. This ten-digit identifier is called the central index key, or CIK. Before you can access a company's reports, you need to know its CIK. You can look up a company's CIK by visiting this site and entering the company's name.
Once you know the CIK of the company you're interested in, you can assign it to the CIK parameter in the EDGAR URL. For example, the CIK of eBay is 0001065088, so you can access eBay's financial reports by appending CIK=0001065088 to the EDGAR URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088
1.2 Form Types
EDGAR provides hundreds of different types of financial reports and you can download a PDF that describes all of them. In my experience, most investors only need to be concerned with the types listed in Table 1:
Table 1: Types of EDGAR Forms
| Form Type | ID | Description |
| Prospectus | 424 | Provides general information about the company |
| Annual report | 10-K | Annual statement of a company's finances |
| Quarterly report | 10-Q | Quarterly statement of a company's finances |
| Annual proxy statement | 14-K | Information about company owners |
| Current events report | 8-K | Notification of important event |
| Sale of securities | 144 | Notification of significant sale of stock |
| Beneficial ownership report | 13-D | Identifies prominent owner (>5%) of company |
For this article, all you need to know about these types is that you can access a report by setting the type parameter equal to the report's ID in the URL's query string. For example, you can access the annual reports (10-K) of eBay (0001065088) by sending a request to the following URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K
1.3 Report Dates and Count
EDGAR doesn't let you ask for reports on a specific date or in a range of dates. Instead, EDGAR accepts a prior-to date, which identifies the latest date you're interested in, and a count, which identifies the number of reports up to the prior-to date.
You can set the prior-to date in the EDGAR URL by setting the dateb parameter to the desired date in YYYYMMDD format. For example, you can access all the annual reports (10-K) of eBay (0001065088) up to 2016 (20160101) by sending a request to the following URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101
You can limit the number of reports provided by EDGAR by setting the URL's count parameter equal to the desired number. For example, you can access the ten annual reports (10-K) of eBay (0001065088) preceding 2016 (20160101) by sending a request to the following URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101&count=10
1.4 Ownership
The SEC requires filings from a company's director, the company's officers, and individuals who own significant amounts of the company's stock. By default, EDGAR provides all of the reports available for a company, regardless of the source. This is equivalent to setting the owner parameter to include in the EDGAR URL.
You can customize EDGAR's behavior by setting owner to exclude or only. If you set owner to exclude, EDGAR won't provide any reports related to a company's director or officer ownership. If you set owner to only, EDGAR will only provide reports related to director or officer ownership.
2. Obtaining Reports Programmatically
If you're interested in accessing EDGAR reports manually, you don't need to read any further. Just enter the right URL in a browser and click one of the download links. Keep in mind that a "Documents" link leads to downloadable files and an "Interactive Data" link displays the report's data in a web page.
If you want to download EDGAR reports programmatically, then determining the URL is just the first step. You'll need to perform at least four steps:
- Send a request to the URL and receive an HTML response.
- Parse the HTML to find the URL(s) of the report(s) of interest.
- For each report of interest, send a request to the report's URL.
- Parse the response to download the desired report.
This section explains how to parse HTML using Python and the Beautiful Soup package. After exploring the Beautiful Soup toolset, I'll explain how to find URLs for reports in EDGAR's HTML search results.
2.1 Parsing HTML with Beautiful Soup
At the time of this writing, the main site for the Beautiful Soup project is here and the latest version is 4.6.0. If you've installed Python and pip, you can install this package with the following command:
pip install beautifulsoup4
After you've installed the package, you're ready to use its capabilities. The general process of parsing HTML with Beautiful Soup consists of two steps:
- Create a
BeautifulSoup instance with an HTML file or a string containing HTML. - Read HTML tag data by accessing the child
Tags of the BeautifulSoup instance.
This brief discussion presents the fundamentals of the Beautiful Soup toolset, but it doesn't discuss all of its classes and features. For a more thorough exploration, I recommend the official documentation.
2.1.1 Creating a BeautifulSoup Instance
When you submit a request to EDGAR, the response consists of HTML-formatted text. You can parse this HTML in Python by creating an instance of the BeautifulSoup class. The class constructor accepts two parameters:
- A string containing HTML or a handle to an open file containing HTML
- (Optional) The name of the parsing library to use
If you call the constructor with one parameter, BeautifulSoup will use the best parser it can find. To specify the parsing library, you can set this parameter to lxml, html5lib, or html.parser. For example, the following code creates a BeautifulSoup instance that parses the content of html_str with Python's built-in html.parser library:
soup = BeautifulSoup(html_str, 'html.parser')
After you call the constructor, you can access the parsed data using properties and methods of the BeautifulSoup instance. I'll discuss them next.
2.1.2 Accessing Tags
The BeautifulSoup instance has many properties whose names correspond to HTML tags. If soup is the name of the instance, soup.head provides a Tag that represents the document's <head> tag, soup.body provides a Tag that represents the document's <body> tag, and soup.p provides a Tag that represents the first <p> tag in the document.
In each case, the property provides a Tag instance that contains the data of the corresponding HTML tag. Conveniently, each Tag has the same tag-related properties as the BeautifulSoup instance. Table 2 lists many of the properties available for BeautifulSoup and Tag instances.
Table 2: Tag-Related Properties of the BeautifulSoup and Tag Classes (Abridged)
| Property | Description |
head | Tag representing the document's <head> tag |
body | Tag representing the document's <body> tag |
a | Tag representing the first hyperlink (<a> tag) |
p | Tag representing the first paragraph (<p> tag) |
b | Tag representing the first bold-faced text span (<b> tag) |
i | Tag representing the first italicized text span (<i> tag) |
img | Tag representing the first image in the document (<img> tag) |
string | NavigableString containing the tag's body text |
Because the BeautifulSoup and Tag classes provide these properties, you can chain them together to access nested tags in an HTML document. For example, the following code prints the title of the document contained in example.html:
with open('example.html') as file:<br />
soup = BeautifulSoup(file, 'html.parser')<br />
print(soup.head.title.string)
After you've obtained a Tag, you can access the attributes of the corresponding tag using dict notation. To see how this works, suppose that example.html contains the following markup:
<html><br />
<body><br />
<p>Here's a link to <a href="https://www.google.com">Google!</a>.</p><br />
</body><br />
</html>
You can access the hyperlink's URL with the following code:
with open('example.html') as file:<br />
soup = BeautifulSoup(file, 'html.parser')<br />
url = soup.body.p.a['href']
You can use similar code to determine a tag's ID. If an attribute can have multiple values, the dict will return a list containing the attribute's values. As an example, if a document uses the class attribute to place a div in multiple CSS classes, you can obtain a list of the class names with div['class'].
2.1.3 find() and find_all()
The properties in Table 2 are only helpful if you're interested in the first tag of a given type. But in many cases, you'll want to access a tag or tags that meet a specific set of criteria. To make this possible, the Tag and BeautifulSoup classes provide the find() and find_all() methods. You can define tag-selection criteria by inserting arguments into the methods. Both methods accept the same types of arguments, but find() returns the first Tag that meets your criteria and find_all() returns a list containing all the Tags that meet your criteria.
To search for tags of a specific type, you can call find or find_all with a tag name or a list of tag names. For example, the following code returns a Tag that represents the document's first paragraph tag (equivalent to soup.p):
soup.find('p')
The following code returns a list containing a Tag for each paragraph and hyperlink:
soup.find_all(['p', 'a'])
You can search for tags with a specific attribute value by calling find/find_all with a name=value pair. For example, the following code accesses the element whose id attribute is set to mytag:
soup.find(id='mytag')
The following code finds the element whose title attribute is set to mytitle and whose href attribute is set to https://www.google.com:
soup.find(title='mytitle', href='https://www.google.com')
If you want to search for tags by their CSS class, you need to use the class_ attribute. For example, the following code returns a listing containing a Tag for each hyperlink that belongs to the new_link class:
soup.find_all('a', class_='new_link')
In addition to strings, find and find_all accept regular expressions, which you can obtain by calling the compile function of the re module. The Beautiful Soup documentation provides many examples.
2.2 Finding URLs for EDGAR Reports
Earlier, I explained how to find the EDGAR URL for the reports of a specific company. For example, if you want the latest ten annual reports of eBay preceding 2016, you can send a request to the following URL:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101&count=10
When I visit this URL in my browser, Chrome presents the web page illustrated in Figure 1:
Figure 1: The Search Page Provides Links for Financial Reports
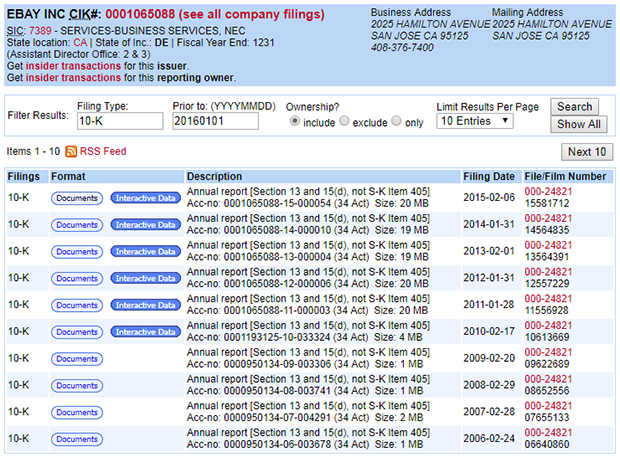
As shown, EDGAR provides search results in one large table. The first column provides the type of report (10-K), the second column provides links for downloading the reports, and the fourth column provides the date of filing. The following markup gives an idea of how this table's first row is defined in HTML:
<table class="tableFile2" summary="Results">
...
<tr>
<td nowrap="nowrap">10-K</td>
<td nowrap="nowrap">
<a href="..." id="documentsbutton">Documents</a>
<a href="..." id="interactiveDataBtn">Interactive Data</a>
</td>
<td class="small" >...</td>
<td>2015-02-06</td>
<td nowrap="nowrap"><a href="...">000-24821</a><br>15581712</td>
</tr>
...
</table>
You can access the table through its CSS class, tableFile2. I always thought that HTML IDs have to be unique, but in the search results page, every Documents link has an id of documentsbutton. Similarly, every Interactive Data link has its id set to interactiveDataBtn. I prefer the Documents link because this is available for all EDGAR reports, not just recent reports.
If you download an EDGAR search page to a Python string (edgar_str) and you use Beautiful Soup, you can print the URLs for the reports with the following code:
soup = BeautifulSoup(edgar_str, 'html.parser')<br />
tag_list = soup.find_all('a', id='documentsbutton')<br />
for tag in tag_list:<br />
print(tag['href'])
In my experience, each href attribute value in the search page has the same general form:
/Archives/edgar/data/.../.../...-...-...-index.htm
To obtain the absolute URL, prepend https://www.sec.gov to the href value. Therefore, the general form of a report's absolute URL is as follows:
https://www.sec.gov/Archives/edgar/data/.../.../...-...-...-index.htm
2.3 Downloading EDGAR Reports
If you click the Documents button in the first row of the table depicted in Table 1, you'll reach a second web page that provides links for directly downloading the report. Figure 2 shows what the second page looks like:
Figure 2: The Document Page Provides Links to Download Reports

In this page, the upper table provides report data in text form and the lower table provides data in a special XML format called XBRL (eXtensible Business Reporting Language). The *.xml files are easier for computers to parse, but they're only available for post-2010 reports. Reports submitted before 2010 are only available in text format.
If you look through the HTML for these two tables, it will look something like the following:
<table class="tableFile" summary="Document Format Files">
<tr>
<td scope="row">1</td>
<td scope="row">FORM 10-K</td>
<td scope="row"><a href="...">ebay201410-k.htm</a></td>
<td scope="row">10-K</td>
<td scope="row">3126866</td>
</tr>
</table>
<table class="tableFile" summary="Data Files">
<tr>
<td scope="row">11</td>
<td scope="row">XBRL INSTANCE DOCUMENT</td>
<td scope="row"><a href="...">ebay-20141231.xml</a></td>
<td scope="row">EX-101.INS</td>
<td scope="row">3504231</td>
</tr>
</table>
In this markup, the only way to distinguish between the two tables is to look at the summary attribute. For the table providing text files, the summary attribute is set to Document Format Files. For the table providing XBRL files, summary is set to Data Files.
In both tables, the hyperlinks have no attributes. Therefore, if you want to find a particular form, you'll need to iterate through the table rows, find the row with the right description (second column), and download the file from the row's URL (third column).
History
1/29/2018 - Initial article submission

