Dimensional model rules in the Data Warehouse world and it is useless if no proper report response time is provided.
When dealing with several million or even billion rows of data, databases may take time performing data grouping or data sorting operations even if very powerful CPUs are available.
One possible approach to make queries response time as fast as possible, is to pre-aggregate data after the main ETL process finishes loading fact tables so it is pre-computed when users demand it. To be more precise, the possible data aggregation step should even be part of the overall ETL chain (usually called in the end).
Oracle has a great feature that allows developers to achieve this without the need of expensive exploration tools (of course, Oracle itself is not cheap … but as far I am aware, it should be the best database around). The feature Oracle provides to developers is called Materialized Views and works like a data snapshot built from an underlying base query. This feature is available in other database engines as well even with different names (e.g. SQL Server has something similar called Indexed Views and IBM DB2 has materialized query tables).
Using Materialized Views, we end up having the main fact table aggregated using several approaches, it is almost as if we have smaller fact tables like the ones presented in the schema below.
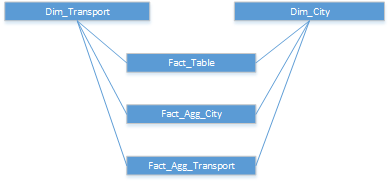
If Materialized Views exist, Oracle database engine is able to rewrite queries so they make use of those pre-computed persisted queries. This article will not provide details regarding associated SQL syntax or deep explanations on how they can be created. There is a lot of information about that already. Materialized views, once created can be refreshed manually, on commit, scheduled, etc. Oracle can even advise you what type of materialized view can be created to speed up a specific query. The package’s name is DBMS_ADVISOR.QUICK_TUNE. Links like https://docs.oracle.com/database/121/DWHSG/toc.htm or this ETL wiki will provide you technical information related to Materialized Views creation, a lot of information about Oracle and general Data Warehouse or ETL development insights.
This article will show evidences regarding the gains when materialized views are used. I will create a test dimensional model with a fact table and two dimensions. The model will simulate travelling information regarding time and cost to five European cities. It will store sixteen million rows of data randomly generated.
In the end, a simulation is made so 100 queries are run against our dimensional model. The first 50 queries are executed after disabling query rewrite option for each materialized view. The syntax for that is:
alter materialized view fac_trip_agg_city_cost disable query rewrite
The second 50 queries are executed with query rewrite enabled instead. The queries will differ between iterations using a random generated “where” clause as the underlying lower and upper limits will be random generated numbers. That way, we minimize the cache result usage and force the query to be executed all times.
So, in the next steps, we will create the required source tables, after that four materialized views, statistics tables and in the end, a simulation script is executed. Let’s proceed.
Step 1
Follow the script below (proper grants must be assigned to the user being used, pay attention to this) - it creates the two dimension tables and inserts data in all of them.
create table dim_city (city_sk number(5), city_name varchar2(50)) compress nologging;
create unique index ix_pk_dim_city on dim_city (city_sk) nologging pctfree 1 storage _
(buffer_pool default flash_cache default cell_flash_cache default) noparallel;
alter table dim_city add constraint ix_pk_dim_city primary key (city_sk);
insert into dim_city values(0, 'Unknown');
insert into dim_city values(1, 'Lisbon');
insert into dim_city values(2, 'London');
insert into dim_city values(3, 'Paris');
insert into dim_city values(4, 'Amsterdam');
insert into dim_city values(5, 'Brussels');
commit;
create table dim_transport(transport_sk number(5), transport_name varchar2(50)) compress nologging;
create unique index ix_pk_dim_transport on dim_transport (transport_sk) nologging pctfree _
1 storage (buffer_pool default flash_cache default cell_flash_cache default) noparallel;
alter table dim_transport add constraint ix_pk_dim_transport primary key (transport_sk);
insert into dim_transport values(0, 'Unknown');
insert into dim_transport values(1, 'Plane');
insert into dim_transport values(2, 'Car');
insert into dim_transport values(3, 'Train');
insert into dim_transport values(4, 'Bus');
commit;
Step 2
The next statement will create the main fact table making use of random number generation approach. The City and Transport foreign keys are randomly generated so are the remaining fields on the table like cost or travel time.
create table fac_trip
nologging
compress
noparallel as
with tbl_aux(line_id) as (select level - 1 as line_id
from dual
connect by level <= 4000),
tbl_aux_2 as (select rownum as fac_sk,
round(dbms_random.value(0, 5), 0) as city_fk,
round(dbms_random.value(0, 4), 0) as transport_fk,
date'2016-01-01' + dbms_random.value(0, 500) as dat_trip_start,
dbms_random.value(0, 9) as val_trip_dur_hours,
dbms_random.value(0, 2250) as val_trip_cost,
1 as qty_trip
from tbl_aux a
cross join tbl_aux b)
select cast(w.fac_sk as number(10)) as fac_sk,
cast(w.city_fk as number(5)) as city_fk,
cast(w.transport_fk as number(5)) as transport_fk,
w.dat_trip_start,
case when w.city_fk in (2, 3, 4) then w.val_trip_dur_hours * dbms_random.value(1, 1.5) _
else w.val_trip_dur_hours end as val_trip_dur_hours,
case when w.city_fk in (2, 3, 4) then w.val_trip_cost * dbms_random.value(1, 1.5) _
else w.val_trip_cost end as val_trip_cost,
cast(w.qty_trip as number(1)) as qty_trip
from tbl_aux_2 w;
Step 3
After data and required support tables are created, let’s update their underlying statistics:
execute dbms_stats.gather_table_stats(ownname => 'your_owner_here', _
tabname => 'dim_city', cascade => true, estimate_percent => dbms_stats.auto_sample_size);
execute dbms_stats.gather_table_stats(ownname => 'your_owner_here', _
tabname => 'dim_transport', cascade => true, estimate_percent => dbms_stats.auto_sample_size);
execute dbms_stats.gather_table_stats(ownname => 'your_owner_here', _
tabname => 'fac_trip', cascade => true, estimate_percent => dbms_stats.auto_sample_size);
Step 4
Now let’s create four materialized views that join and aggregate the main fact table data per city and transport type. The queries compute the average costs and travel times.
create materialized view fac_trip_agg_city_cost
nologging
cache
build immediate
enable query rewrite as
select b.city_sk,
b.city_name,
avg(a.val_trip_cost) as metric_value
From fac_trip a,
dim_city b
where a.city_fk = b.city_sk
group by b.city_sk,
b.city_name;
create materialized view fac_trip_agg_city_duration
nologging
cache
build immediate
enable query rewrite as
select b.city_sk,
b.city_name,
avg(A.val_trip_dur_hours) as metric_value
From fac_trip a,
dim_city b
where a.city_fk = b.city_sk
group by b.city_sk,
b.city_name;
create materialized view fac_trip_agg_transp_cost
nologging
cache
build immediate
enable query rewrite as
select b.transport_sk,
b.transport_name,
avg(a.val_trip_cost) as metric_value
From fac_trip a,
dim_transport b
where a.transport_fk = b.transport_sk
group by b.transport_sk,
b.transport_name;
create materialized view fac_trip_agg_transp_duration
nologging
cache
build immediate
enable query rewrite as
select b.transport_sk,
b.transport_name,
avg(A.val_trip_dur_hours) as metric_value
From fac_trip a,
dim_transport b
where a.transport_fk = b.transport_sk
group by b.transport_sk,
b.transport_name;
Step 5
Let’s create three auxiliary tables to store statistics data and timings obtained in the simulation script:
create table tbl_aux_stats_city
(
iteration number(3),
iteration_type varchar2(1),
metric_name varchar2(50),
city_name varchar2(50),
metric_value number
)
nologging
noparallel
nocache;
create table tbl_aux_stats_transport
(
iteration number(3),
iteration_type varchar2(1),
metric_name varchar2(50),
transport_name varchar2(50),
metric_value number
)
nologging
noparallel
nocache;
create table tbl_aux_stats_time
(
iteration number(3),
iteration_type number(1),
start_time timestamp,
end_time timestamp
)
nologging
noparallel
nocache;
Step 6
Now we can run the following script:
declare
start_time timestamp;
inf_value number(5);
sup_value number(5);
begin
execute immediate 'alter session set query_rewrite_enabled = true';
execute immediate 'truncate table tbl_aux_stats_time';
execute immediate 'truncate table tbl_aux_stats_city';
execute immediate 'truncate table tbl_aux_stats_transport';
for idxm in 1..2 loop
if idxm = 1 then
execute immediate 'alter materialized view fac_trip_agg_city_cost disable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_city_duration disable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_transp_cost disable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_transp_duration disable query rewrite';
else
execute immediate 'alter materialized view fac_trip_agg_city_cost enable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_city_duration enable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_transp_cost enable query rewrite';
execute immediate 'alter materialized view fac_trip_agg_transp_duration enable query rewrite';
end if;
for idx in 1..50 loop
start_time := systimestamp;
inf_value := round(dbms_random.value(0, 5), 0);
sup_value := round(dbms_random.value(inf_value, 5), 0);
insert into tbl_aux_stats_city
select idx as iteration,
idxm as iteration_type,
'Avg Cost' as metric_name,
b.city_name,
avg(a.val_trip_cost) as metric_value
from fac_trip a,
dim_city b
where a.city_fk = b.city_sk and
b.city_sk between inf_value and sup_value
group by b.city_sk,
b.city_name
union all
select idx as iteration,
idxm as iteration_type,
'Avg Duration' as metric_name,
b.city_name,
avg(a.val_trip_dur_hours) as metric_value
from fac_trip a,
dim_city b
where a.city_fk = b.city_sk and
b.city_sk between inf_value and sup_value
group by b.city_sk,
b.city_name;
insert into tbl_aux_stats_transport
select idx as iteration,
idxm as iteration_type,
'Avg Cost' as metric_name,
b.transport_name,
avg(a.val_trip_cost) as metric_value
from fac_trip a,
dim_transport b
where a.transport_fk = b.transport_sk and
b.transport_sk between inf_value and sup_value
group by b.transport_sk,
b.transport_name
union all
select idx as iteration,
idxm as iteration_type,
'Avg Duration' as metric_name,
b.transport_name,
avg(a.val_trip_dur_hours) as metric_value
from fac_trip a,
dim_transport b
where a.transport_fk = b.transport_sk and
b.transport_sk between inf_value and sup_value
group by b.transport_sk,
b.transport_name;
insert into tbl_aux_stats_time
values (idx, idxm, start_time, systimestamp);
commit;
end loop;
end loop;
end;
/
Once the script finishes (it may take some time running), you will obtain in table tbl_aux_stats_time the Start and End time for each iteration with and without using the materialized views (iteration type 1 does not use the materialized views while type 2 uses them). The query below will provide the time each iteration took in seconds and the related cumulative times per period (please consider that for the same period the script does not run the same query):
with tbl_aux as (select a.iteration,
a.iteration_type,
((a.end_time + 0) - (a.start_time + 0)) * 24 * 60 * 60 as elapsed_time_seconds
from migra_arf.tbl_aux_stats_time a),
tbl_aux_2 as (select a.iteration,
max(case when a.iteration_type = 1 then a.elapsed_time_seconds else null end) as elapsed_time_seconds_1,
max(case when a.iteration_type = 2 then a.elapsed_time_seconds else null end) as elapsed_time_seconds_2
from tbl_aux a
group by a.iteration)
select o.iteration,
o.elapsed_time_seconds_1,
sum(o.elapsed_time_seconds_1) over (order by o.iteration rows unbounded preceding) as elapsed_cum_time_seconds_1,
o.elapsed_time_seconds_2,
sum(o.elapsed_time_seconds_2) over (order by o.iteration rows unbounded preceding) as elapsed_cum_time_seconds_2
from tbl_aux_2 o
order by 1
The query result is presented below:

Putting it visually in charts, we can observe (with a linear scale) the difference between the two cumulative timings increasing. The gap between the two cumulative functions is expected to increase because on average, one should expect the time to run the query without Materialized View to be about three times higher than running it against the Materialized Views.
With logarithmic scale, the difference between individual period timings becomes more evident (although we are not comparing the same query for the same period). Queries executed against materialized views usually take much less time than queries against the main table.
It is easily understandable that the difference between the two cumulative metrics will tend to increase while the iteration increases. This seems like an empirical evidence regarding the advantages Materialized Views are capable of when one considers the long term perspective. The difference between both lines represents CPU cost, represents time users waited for data, represents time CEOs waited for important decision support reports or a possible fast investment decision on some financial product. That difference has associated costs so making use of these features makes sense as usually the time required to refresh the Materialized Views in the ETL process is negligible when compared to the gains if a lot of report requests are made against the database.
To help readers understand these advantages better, I present in the next pictures the queries’ explain plans without materialized view and with materialized view usage. If you pay attention to the steps sequence, you will notice (in the first picture) that Oracle makes a full table scan to table FAC_TRIP on steps 3 and 10 and after that, it needs to group and then sort pulled data.
These steps should not be required if the materialized views have the required pre computed data and can be used instead of the main table. Check the second picture please.
In the picture below, we can confirm that by enabling query rewrite for all materialized views, it is obvious we end up having a much simpler explain plan so the database will reply faster.
As a conclusion, it seems evident that there are advantages on using Materialized Views, at least in decision support systems and for ETL processes, so report response time can be reduced and tuned.
Once again, tests should be made and, depending on the size base data sets have, developers should evaluate very well the required time to refresh the existing Materialized Views. These are not dogmas, so feel free to question them and always look for the best solution for your problem.

