In this article, we will train a classifier in Azure that will get us 100% accuracy in detecting whether a message is spam or not. We will also explore a more direct word frequency approach which will get us a surprisingly high accuracy.
Contents
Introduction
In this article, we will walk through creating a spam classifier in Microsoft's Azure Machine Learning Studio. We will then expose our trained classifier as a web service and consume it from a C# application.
Before we get started, you will need to sign up for a free Azure ML Studio account, copy my Azure training experiment and web service experiment, and clone my GitHub repo.
Data Preprocessing
Formatting the File
The data we are going to be using contains 2,000 labeled messages for training and 100 labeled messages for testing. Every message is labeled either spam or ham (not spam).
# Spam training data
Spam,<p>But could then once pomp to nor that glee glorious of deigned. The vexed...
Spam,<p>His honeyed and land vile are so and native from ah to ah it like flash...
Spam,<p>Tear womans his was by had tis her eremites the present from of his dear...
...
# Ham training data
Ham,<p>Nights chamber with off it nearly i and thing entrance name. Into no sorrow...
Ham,<p>Chamber bust me. Above the lenore and stern by on. Have shall ah tempest...
Ham,<p>I usby chamber not soul horror that spoken for the of. I yore smiling chamber...
...
# Test data
Ham,<p>Bust by this expressing at stepped and. My my dreary a and. Shaven we spoken...
Ham,<p>Again on quaff nothing. It explore stood usby raven ancient sat melancholy...
Ham,<p>Tell floor perched. Doubting curious of only blessed ominous he implore...
...
To make this data a bit easier to work with, we will divide it into two CSV files and add headers. The resulting train.csv and test.csv files will look like this:
classification,message
Spam,<p>But could then once pomp to nor...
Spam,<p>His honeyed and land vile are...
Spam,<p>Tear womans his was by had tis...
...
Uploading the Data
Now we need to get this data into Azure so we can play around with it. Log in to ML Studio and click +New in the lower left part of the page. This will bring up a menu from which you can add a new data file.

From here, we can follow the wizard and upload our train.csv and test.csv files as datasets in ML Studio.
Now for the fun part! Click on +New once again, only this time go to the Experiment menu and select Blank Experiment. This is where we will visually design an algorithm for cleaning up our data and training our model.
From the panel on the left, open up Saved Datasets > My Datasets and drag the train.csv dataset onto the workspace.
You can take a peek at the data by right clicking on the item and going to Dataset > Visualize.
Normalizing the Data
Notice that the message data contains some HTML tags, mixed casing, and punctuation. We will want to clean this up a bit by stripping out special characters and converting everything to lowercase. To do this, search for the Preprocess Text step in the sidebar and drag it on to the workspace. Connect the output of the training dataset to the input of the Preprocess Text step by dragging a line using the mouse.
We can configure the Preprocess Text step by clicking on it and adjusting the settings that appear on the right side of the screen. Click on Launch column selector and select the message column, as this is the column we will be running the cleanup tasks on. Uncheck everything else except for the options to remove numbers and special characters and convert everything to lowercase.
You can now run your project using the Run button at the bottom of the screen. When it completes, you can right click on the Preprocess Text step and visualize the data after the cleanup step just like you did for the input dataset. Notice that this step added a new Preprocessed message column with a much cleaner list of words to work with.
At this point, we have a dataset with three columns. Since we only care about the Preprocessed message column, we will remove the message column. Drag a Select Columns in Dataset step from the list on the left and connect it to the output of the Preprocess Text step.
Use the Launch column selector on the properties panel to the right to choose the classification and Preprocessed message columns. If you run the project and visualize the output after this step, you will see that the message column is no longer present.
Although it is not strictly necessary to do so, I opted to rename the Preprocessed message column back to message. This can be done by adding an Edit Metadata step, selecting the column you wish to rename, and specifying a new name.
Running the project and visualizing the results shows that we have indeed renamed the column.
Extracting Features
So now, we have nice clean input data, but how do we transform it into something that can actually be used to train a classifier? By using the Vowpal Wabbit algorithm of course! Add a Feature Hashing step to the workspace, select the message column, and set the Hashing bitsize to 8.
This step will do three important things:
- First, it will extract all pairs of sequential words (called bigrams) from our message column. For example, the sentence
"hello, I am Scott" would contain three bigrams: "hello i", "i am", and "am scott". - Next, it will compute an 8 bit hash for each bigram. Note that there is a chance that multiple bigrams could result in the same hash (a collision), so we need to choose a large enough hash size to prevent collisions but a small enough hash size so we do not exhaust system resources. This step allows us to reduce an input space as complex as a sentence into a more manageable list of numbers.
- Last, it will create a new column in the output dataset for each hash. With an 8 bit hash, we will get exactly 256 (28) columns. Each of these feature columns will contain a count of how many bigrams in the message have the same hash.
This is how we convert a single, massive string of words into table of numbers that can be fed to a model. By visualizing the output dataset from this step, we can see we do indeed have a lot of feature columns.
Of course, not every one of those 256 feature columns are useful. While some of them may be extremely useful in predicting the classification of a message, others may be zero for nearly all messages and therefore have no predictive power at all. We can compute which features are most valuable using the Filter Based Feature Selection step and specifying that we want to keep only the top 100 most useful features.
Visualizing the output of this step reveals we have drastically reduced the number of feature columns in our dataset. In the visualization window, you can select individual columns to see a graph representing the distribution of values in that column.
Model Training
Picking a Classifier
We now have our data in a format that is perfect for training models. For this type of data, we will use a Two-Class Logistic Regression classifier since our data only has two possible classifications: spam or ham. This classifier uses supervised learning, which means we feed the algorithm sets of correctly labeled sample data during training so it can learn to classify unlabeled data later.
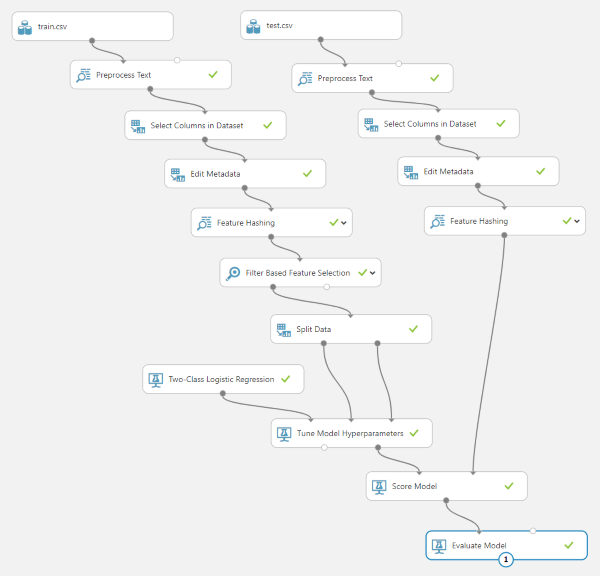
To train our classifier, we need to pull in a Two-Class Logistic Regression step, a Split Data step, and a Tune Model Hyperparameters step and connect them as shown below:
The Two-Class Logistic Regression classifier is actually already a working model; it just has not been trained yet. The Tune Model Hyperparameters step will take an existing model and adjust the parameters until it is able to correctly classify a set of input data.
You probably noticed that we have a Split Data step in there. This will split the data into two sets with 90% of the data going into the training data input of the Tune Model Hyperparameters step, and 10% going into the validation input. During training, the validation data will be used to test the accuracy of the model.
Scoring the Classifier
Now that we have a trained model, we need to gauge its effectiveness. For this, we will use the test.csv dataset and run it through all the exact same preprocessing steps we ran train.csv through. Just copy and paste the steps we already have in place for the training set.
Note that we are not copying the Filter Based Feature Selection step over to the testing set steps. Although the Feature Hashing step is guaranteed to always output the same columns, the Filter Based Feature Selection step is not. Every time it runs on a new dataset, it will pass a different set of useful columns through to the next step. If we end up selecting the wrong columns, we will get an error in the Score Model step which expects the input dataset to have all the same columns the model was trained on.
By keeping all 256 columns, we guarantee that all features will be present for our trained model to pick and choose what it was trained to use. It does not hurt to have extra columns, but it does hurt to have missing columns.
It is also important to note that we need to evaluate our model accuracy using data that was not used during training since the real test of a predictive model is how well it predicts data we did not train on. It is also possible to overtrain (or overfit) a model so that it memorizes data instead of developing a generalized algorithm to make predictions based on the data.
The final two steps we need to add are the Score Model step and the Evaluate Model step (which do exactly what they say they do). Here is what the final project looks like all wired up. Score Model will take our trained classifier, run it against the test dataset, and append a column that represents its best guess on the classification of the message. Evaluate Model will calculate the prediction accuracy based on the known and the predicted classifications.
Run the project! After everything finishes running, right click on the Evaluate Model step and visualize the validation results. What you should hopefully see is that the model has a high accuracy (the closer to 1.0 the better). Since our data is really simple, we managed to get a perfect 100% accuracy!
This classifier turned out really good, so we will go ahead and save it. Right click on the Tune Model Hyperparameters step and save the trained best model.
Web Service Creation
Setting It Up in Azure
With our working model saved, we can now set up a web service so we can use the model from anywhere. First of all, duplicate the Experiment in Azure by clicking Save As and naming it something that sounds like a web service.
The primary difference between training data and real data is that the training data has a classification column and the real data does not. Obviously, the data sent to us through the web service will not arrive already classified, so we need to make some changes to handle this.
Start off by by adding a Select Columns in Dataset step between the existing train.csv and Preprocess Text steps, and setting it up to only select the message column. This will strip out the classification column so we can test our project as if the data was coming from a web service request.
The existing Select Columns in Dataset step after the Preprocess Text step will need to be modified to only select the Preprocessed message column. Previously, it selected the classification column too, but we do not need that here.
Next, you can take out all the steps between Feature Hashing and Score Model, and then connect Feature Hashing directly to the dataset input of Score Model. Drag our saved model from Trained Models in the left side menu and connect it to the model input of Score Model (where the untrained model used to be connected).
The output dataset of Score Model contains the entire input dataset (all 256 columns) with the addition of a model score column, so we need to slim that down if we intend to return it from a web service call. Add another Select Columns in Dataset after Score Model and remove the Evaluate Model that used to be there. Configure it to select only the Scored Labels column (the one added by the scoring step).
Finally, we can drag in a Web service input step and connect it to the Preprocess Text step, and a Web service output step and connect it to the final Select Columns in Dataset step. Set the web input parameter name in the settings to message and the output parameter to classification.
Everything is now in place for us to create a web service! Run the project to make sure it works and then click the Deploy Web Service button at the bottom of the page. On the subsequent screen, take note of your secret API key as you will need this to access the web service later. Also, click on the Request/Response link to get your service endpoint and some useful API documentation.
Calling It from an Application
If you have not done so already, clone or download the code associated with this project and run it. The first time you run the program, you will get a popup asking for your API key. Paste your APIC key from Azure into this box and click OK. Also make sure you update the AzureEndpoint setting to your web service endpoint in the App.config.
When you get the app up and running, paste any message into the form and click Classify to run your model. If all works as expected, you will get the classification from the web service.
The second tab lets you send off an entire file of labeled data to the web service for classification and then validates the responses. After running this model on the entire data set (training and testing combined), we managed to get 100% accuracy!
Alternate Solution
I was curious to see how much more accurate the Azure model was than just doing a simple word frequency analysis myself, so I created the WordSearchClassifier which does just that. It works by dividing up each message into bigrams (sequential groupings of two words) and counting their frequency throughout the entire training set.
public void Train(string trainingFile)
{
bigrams = new Dictionary<string, int>();
hamCutover = 0;
string[] trainingData = File.ReadAllLines(trainingFile);
List<LabeledMessage> messages = new List<LabeledMessage>();
foreach (string line in trainingData)
{
if (line.StartsWith("Ham") || line.StartsWith("Spam"))
{
string[] data = line.Split(new char[] { ',' }, 2);
messages.Add(new LabeledMessage(data[0], data[1]));
}
}
foreach (LabeledMessage message in messages)
{
string[] words = ParseBigrams(CleanMessage(message.Message));
foreach (string word in words)
{
if (bigrams.ContainsKey(word))
{
bigrams[word] += message.RealClassification == "Ham" ? 1 : -1;
}
else
{
bigrams.Add(word, message.RealClassification == "Ham" ? 1 : -1);
}
}
}
hamCutover = messages.Select(x => GetScore(x.Message)).Average();
}
Once our model is trained, we will have a dictionary of bigrams and their associated tendency to be in Ham or Spam messages. We will then score each of the messages in our training set and find the value that generally divides the Ham from the Spam. For this training data, that cutover point is approximately 10.88 based on our scoring method.
Yes, I know an average is not technically the correct way to divide the scores. This only appears to work because we have the same number of ham and spam messages, and because all of the messages are roughly the same length. Here is a cool graph to make up for my laziness.
All we have to do to classify a message once we finish training is calculate the score and see if it falls above or below this threshold.
private string RunModel(string message)
{
return GetScore(message) > hamCutover ? "Ham" : "Spam";
}
private double GetScore(string message)
{
double score = 0;
string[] messageBigrams = ParseBigrams(CleanMessage(message));
foreach (string word in messageBigrams)
{
if (bigrams.ContainsKey(word))
{
score += bigrams[word];
}
}
return score / messageBigrams.Length;
}
This method actually ended up being able to classify 1,986 out of the 2,000 training patterns, and 100 out of the 100 unseen testing patterns for an overall accuracy of 99.33%. That is actually pretty cool, and it runs through all 2,100 messages in just 420ms.
Summary
We managed to train a classifier in Azure that got us 100% accuracy in detecting whether a message was spam or not. We also explored a more direct word frequency approach which got us a surprising 99.33% accuracy.
Fun fact! My first model used a 16 bit hash (for 65,536 features) and selected the top 1,000 best features. After writing the entire article to reference these numbers, I played around with the settings a bit more and realized that I did not drop below 100% accuracy until I lowered that to a 6 bit hash (for 64 features).
This was my first time using Azure ML, and I learned a lot while putting this article together. My background in data science is fairly short, but does include a few graduate courses in data mining (where we used Weka) and an ongoing fascination with solving CAPTCHAs.
Thank you!
History
- 11th February, 2018: Initial release
- 12th February, 2018: Added links to Azure experiments

