Introduction
Technical debt is bad - everyone knows that.
With every spaghetti you add to your code, the knots get tighter and the overview gets ever worse, until adding a simple button to your software ends up collapsing the far end of your software. The customer feature request is forgotten because there's no backlog, the logging doesn't work anymore, but you won't know until the next bug report arrives, because there are no tests implemented. Why document? YAGNI!
On the other hand, there are deadlines to catch.
You need to implement a little tool to just once parse some test data into a csv, but hey, that class in there could use an interface, so let's draw a UML diagram first. That interface could inherit that one of our internal library, let's just add another feature in there, so it covers that little parser too. And let's document it in our wiki. Oh, and what a great use case to try that other great new versioning tool everybody talks about... Oops. Missed the deadline.
Do you - like me - have colleagues of both extremes? Did you ever try to argue with them about their opinions?
I did, and didn't get far. While that Mr. Pragmatic tells you YAGNI, that Mr. Perfectionist tells you SOLID. The one clutters your internal library with code that "worked for me", while the other just won't get your sorely needed feature ready and push out the new release of that pretty same internal library. And both are trying to convince you, their way is the only way.
The conclusion I've drawn is, the right way depends. And because I didn't find a guideline to what it depends on, I decided to write it on my own.
So here comes the guideline how to prevent overengineering and underengineering as well.
Categorizing Software
First of all, software should be categorized somehow, ranging from "Just get it done" software, up to "can't be overengineered (nearly, at least)".
Working in metal industry, and building our own machines for our own production, I've made the experience that software can have a long life. There are machines still running that are seventy years old (well, those still with mechanical controllers, of course). There are software out there up and running on Windows versions published when I could scarcely walk. And when the customers - production departments of our company - need improvements in their production processes, it's maybe you, who has to add a button in that old C++-Code that no one ever cared to document - or even comment, using two-lettered variable names.
My conclusion is, the longer software lives, the more your successors will hate you for every YAGNI you've made.
Of course, that's not the only measure to take into account. If you have a one-liner you've been using every other day for the last twenty years, well, it's still a one-liner. One line should be pretty well readable in code, and you as a developer should be able to read it without having great explanations around.
As software shouldn't be measured in lines of code, I thought of measuring it by complexity (though the borders might be fluent), whilst complexity composes somewhat on lines of code, but on target group as well. If your users are other developers (e.g. you're writing an API), requirements will be pretty more challenging, the result pretty more complex than, say, some machine software only used on that single type of machine. Therefore, complexity also depends on how often people will call your method or function again.
So here's what I've come up with:
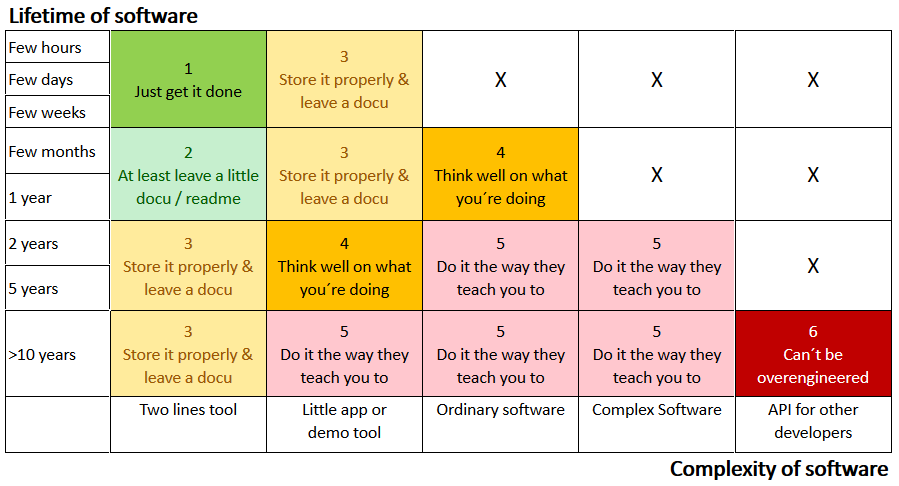
1. Category: Just Get It Done
"Software" of this category includes tools you will never ever use again. For example, you write a two-liner to download some example data from a server or a little parsing tool to convert some XML data into CSV format, and you only have to do it once.
Often, these little tools just help you to accomplish your real software development.
Therefore, just do it! Then throw it away. If you think "I'll keep it, who knows..." this is the wrong category.
2. Category: At Least Leave a Docu
Maybe you're doing simple tooling ten times a day. How will you find the one you used last month to parse that XML to CSV?
Well, if you think "I won't look for it, but simply redo it" then you're in the wrong category here. You shouldn't ever have stored it.
But if it in fact wasn't that easy to accomplish this little tool, you should at least have given it a descriptive name and have left some docu or readme on what your little tool does.
If you intend to extend your little tool, it will definitely live too long to be in this category...
3. Category Store It Properly & Leave a Docu
A tool that probably will be used every day, or not only by you, and for a pretty long time, should of course be properly version-controlled. It's quite probable you (or someone else) will adjust it one day to new conditions, and one day you could be happy to have a history on your changes.
The same handling should be used for little apps or demo tools that won't live that long, but are still likely to get some changes in their (short enough) lifetime.
As we're still talking about pretty little and easy software, SOLID principles should go pretty easy. If you're one of those loving Test Driven Development, this is a nice category to try using it.
4. Category: Think Well On What You're Doing
So now we're in a category where things grow interesting. Either it's a little, but long-living app, or a pretty normal-sized software that won't live longer than a year.
Fact is: your software will receive updates, therefore will need to be maintained. There will be support issues. You need to think well on where and how to store your code, so it won't go lost. Testing will be necessary, to make sure your update won't break things up. You should document the software itself, as well as who made changes and why.
This category is a great place if you're hyping TDD.
Though, it's not the end of the complexity ladder. For example, abstraction layers should only be introduced if really needed inside the software. You won't need interfaces for every little step you take, if it's improbable that other concrete implementations will ever come up.
5. Category: Do it the Way They Teach You To
Think back to your school / university / courses / conferences. There you did all those funny little "Hello World!" examples and made interfaces and abstraction layers. You made user stories and kept track of them. You've put it all into git and written a great documentation.
Well, in this category, you will need exactly all that stuff. Here, we're talking about rather complex and long-living software. It's pretty likely you won't be with that company or department anymore, when that software finally dies away - so do your successors a favor and leave that place like you'd like to find it.
6. Category: Can't Be Overengineered (Well, Nearly)
So if you come here thinking "why should APIs be the most complex thing in here?", maybe you should think first, why people put things into APIs. You don't need APIs for doing the simplest of things. You write them for things that are used most often inside other software, and therefore need to be most reliable and best tested. Or you write APIs for the most complex things, so others don't have to think of it anymore, which - well, again - needs to be most reliable and best tested.
Things need to be properly documented, example code must be provided. Experience tells me, if any of these is not available, devs won't use it, reinvent the wheel, use it wrong - or annoy you with their never-ending questions. Even you yourself won't remember the details of your implementation, so you're doing yourself a favor in caring for your work.
Such an API needs to be stored properly with backups, it needs be tracked to find the one who screwed things up.
Of course, there are always deadlines for APIs, too. Where I currently work, our internal library / API is done "alongside" our daily work, lacking tests, lacking documentation, lacking common best-practices. So I can tell you from my own experience, screwing up an API results in more (and pretty senseless) work than you'd like to ever have. If you're an API developer, your hardest task is to convince your boss of the necessity not only of code, but the environment around it, too.
X - This Category Does Not Exist
So what are those white spaces in that table? Well, these kinds of software simply don't exist. An API that only lives a few days? Then you already overengineered it.
As soon as an API or pretty complex software gets published, people will use it. Maybe you won't even know, but your once uploaded GitHub-Code might have been copied to a local repository and people in a company like where I work will use it - maybe for the next thirty years. Wouldn't you be ashamed not to have left any documentation for those users? Or worse: untested, maybe even malicious code?
The more complex your software or API is, the more careful you should be in handling it, as it will live long - possibly longer than you'd like to admit.
Concrete Conclusions
Based on those categories, let's go one step further and derive, how much engineering is really needed in which category:

How Much Documentation Do I Need
Whilst a descriptive name should always be given and be your good habit, you won't need to draw extensive UML diagrams for "Just get it done" tooling.
Code comments are always worth a discussion - I personally use Visual Studio and keep the "XML-File"-checkbox checked even for small software as to get compiler warnings for undocumented public features. Public means "can be used from elsewhere" - and whoever uses it should not have to open your code to find out what it does, especially if the name won't be sufficient to know. So if you think "why do I have to comment this?" think rather about "why did I make that member public?". By the way - I don't do inline commands, only such public member summaries. If someone needs to understand the logic inside, he has to read the code anyway.
Please note, that example code should always be available for APIs - and for complex software too, if it contains complex abstraction layers. Be sure to document how to maintain it, and how to extend it. Your successors will love you for it.
A wiki - as well for your users, as for maintainers - will keep your support calls in bay. Even if your error message tells the user "Can't save. No disk space available." - experience tells, they will call and ask what to do. Why, increase disk space or clean up! - which is exactly, what the wiki should tell them. Of course, you won't need that for tools that will be used only for a few hours.
Try to keep the documentation up to date - documenting complex software should be part of the development workflow.
Tests
The longer your software lives and the more often it will be maintained, changed or extended, the more important is it to have unit tests in place.
With Test Driven Development as hype (as of now already weakening again), people tend to exaggerate unit testing. No one will ever need unit tests in a two liner. The need for unit tests increases with the complexity of the software, so as not to break existing features. An API should always be unit tested.
Storage
To store software, be it big or small, simple or complex, you should always use a repository to be able to track and revert changes. Storing the repository itself in backed up place should be self-evident, too.
The only thing you won't need to store in a repository is a tool you need now - and only now.
Development Methods
Some principles - for example SOLID - should become your habit and therefore go easy for you. Of course, you won't need extensive Separation in different classes in a two-liner - but everything bigger should always be well-structured.
For real complex software or even APIs, you should plan a basic application architecture before you start to code. The use of interfaces and abstraction layers should be restricted in really multi-used features for simple software, whilst being the default for complex software or APIs. Especially in the latter everything, that could need additional implementations by other coders, should be prepared for such using interfaces.
Now for TDD again... You can see in the table I'm not one of the hypers. Whilst TDD can be a great approach for small and middle-size software, the over-all architecture is often overseen by hyping developers. Especially for high-complex APIs, it's Architecture First, not Test First, but neither Code First. Of course, TDD makes it easier to defend the effort needed to implement unit tests, as it's simply part of the development workflow. But if you need TDD to persuade your boss, testing is an important thing, you've got greater problems than just testing.
As well, unit tests, again, should never ever be needed for two-liners.
Software Environment
The last point is the world surrounding your software.
APIs nowadays should always be delivered via NuGet / npm, etc., even if they are only for internal use (then use a private managing system). Using your own API should not be harder or different for other coders than using those of the rest of the world.
The ALM topic as a whole should only concern you for software that really needs backtracking. Don't do that overhead for tools that will never ever get updated, because they're only used once, or small apps that won't have a long life. Looking into the repository commit comments should be sufficient to track down changes here. Same applies to an updating strategy.
Requirements / functional specifications are pretty much the same as ALM - nowadays often as not even replaced by it.
Proper software versioning should be always done if code goes out to your end users and will receive updates, so to be able to backtrack users' issues on specific versions.
Thoughts on this Guideline
I can already hear Mr. Perfectionist arguing with Mr. Pragmatic again on my article.
"Look", Mr. Pragmatic says, "we don't need to implement unit tests, the article says. I only use the tool once." Mr. Perfectionist answers: "But we really need an interface. Because, if we add functionality X, maybe one day we can use that tool for use case Y again, so it's a long-living thing..."
Of course, a healthy portion of self judging is needed to apply this guideline properly. I see this as one of those soft skills no one ever mentions, that are really crucial to project success and keeping deadlines: judging how to categorize a software, and therefore judging, how much engineering should be done.
Of course I'm mortal too, and there are lots of YAGNIs made because of deadlines, whilst some well-meant and well-documented tools of mine are rotting. Often as not, I don't cling to my own rules, be it because of having a boss who's never heard of "technical debt", but dreaming of unicorns, or be it because of lazyness (or fun) on something.
But writing down these thoughts of mine shall help me - and maybe you too - remember, that ovengineering is as bad as underengineering and it is one of our most important daily tasks to find the way between.
Personal Note
Finding categories of software wasn't as easy as it looks in hindsight. There are pretty well other measures I found, but finally discarded. For example, distribution range. Shouldn't a software, that's daily used by half the world, let's say, a clock app with half a million downloads, be unit tested? Well, if it's only two lines of code, truly, no - I think.
I would love to read your opinions on that. Do you see other measures that I should have taken into account? Do you find my opinions too restrictive / too open? Which type of dev are you? Pragmatic vs. Perfectionist? Try to judge yourself and tell me!
This is my very first article ever published, so please don't judge on me too hard. English is not my first language either.

