Introduction
So you are going to do some web scraping!? Maybe you will build up a database of competitive intelligence, create the next hot search engine, or seed your app with useful data... Here is a tool that makes the job fun: A Nuget Package called XHtmlKit. Let's get started:
Step 1: Create a Project
First, create a new Project in Visual Studio. For this sample, we will use a Classic Desktop, Console App:
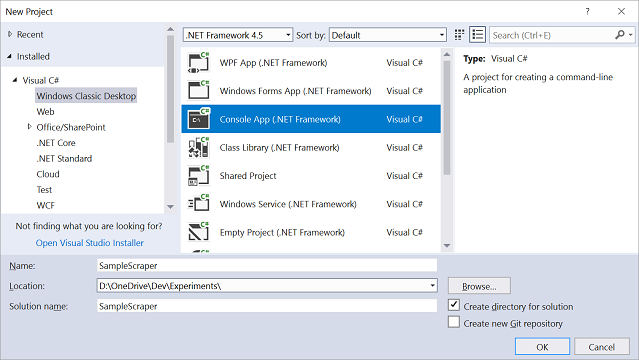
Step 2: Add a Reference to XHtmlKit
Next, within the Solution Explorer, right click on References, and select Manage Nuget Packages:

Then, with the Browse tab selected, type: XHtmlKit and hit Enter. Select XHtmlKit from the list, and click Install.
You will now see XHtmlKit in your project's references:
Step 3: Write a Scraper
First, create a POCO class to hold the results of your scraping. In this case, call it Article.cs:
namespace SampleScraper
{
public class Article
{
public string Category;
public string Title;
public string Rating;
public string Date;
public string Author;
public string Description;
public string Tags;
}
}
Then, create a class to do the scraping. In this case: MyScraper.cs.
using System.Collections.Generic;
using System.Xml;
using XHtmlKit;
using System.Text;
using System.Threading.Tasks;
namespace SampleScraper
{
public static class MyScraper
{
public static async Task<Article[]> GetCodeProjectArticlesAsync(int pageNum = 1)
{
List<Article> results = new List<Article>();
string url =
"https://www.codeproject.com/script/Articles/Latest.aspx?pgnum=" + pageNum;
XmlDocument page = await XHtmlLoader.LoadWebPageAsync(url);
var articles = page.SelectNodes
("//table[contains(@class,'article-list')]/tr[@valign]");
foreach (XmlNode a in articles)
{
var category = a.SelectSingleNode("./td[1]//a/text()");
var title = a.SelectSingleNode(".//div[@class='title']/a/text()");
var date = a.SelectSingleNode
(".//div[contains(@class,'modified')]/text()");
var rating = a.SelectSingleNode
(".//div[contains(@class,'rating-stars')]/@title");
var desc = a.SelectSingleNode(".//div[@class='description']/text()");
var author = a.SelectSingleNode
(".//div[contains(@class,'author')]/text()");
XmlNodeList tagNodes = a.SelectNodes(".//div[@class='t']/a/text()");
StringBuilder tags = new StringBuilder();
foreach (XmlNode tagNode in tagNodes)
tags.Append((tags.Length > 0 ? "," : "") + tagNode.Value);
Article article = new Article
{
Category = category != null ? category.Value : string.Empty,
Title = title != null ? title.Value : string.Empty,
Author = author != null ? author.Value : string.Empty,
Description = desc != null ? desc.Value : string.Empty,
Rating = rating != null ? rating.Value : string.Empty,
Date = date != null ? date.Value : string.Empty,
Tags = tags.ToString()
};
results.Add(article);
}
return results.ToArray();
}
}
}
Then, use the MyScraper class to fetch some data:
using System;
namespace SampleScraper
{
class Program
{
static void Main(string[] args)
{
Article[] articles = MyScraper.GetCodeProjectArticlesAsync().Result;
foreach (Article a in articles)
{
Console.WriteLine(a.Date + ", " + a.Title + ", " + a.Rating);
}
}
}
}
Now, hit F5, and watch the results come in!
Points of Interest
There are a few key elements to this sample: Firstly, the line:
XmlDocument page = await XHtmlLoader.LoadWebPageAsync(url);
is where the magic happens. Under the hood, XHtmlKit fetches the given web page using HttpClient, and parses the raw stream into an XmlDocument. Once loaded into an XmlDocument, getting the data you want is made straightforward with XPath. Note that LoadWebPageAsync() is an asynchronous method, so your method will be async as well!
Our anchoring XPath statement fetches all tr rows with a valign attribute, that fall directly below the table node with a class attribute containing the term 'article-list':
var articles = page.SelectNodes("//table[contains(@class,'article-list')]/tr[@valign]");
This is a relatively robust XPath statement, since the term 'article-list' is clearly semantic in nature. Although the web-page's underlying CSS formatting may change, it is not likely that the articles will move to a different markup home without a major page re-design.
Finally, all that is left to do, is loop over the article nodes, and extract the individual article elements from each XHtml blob. Here, we use XPath statements that are prefixed with './'. This tells the XPath evaluator to find nodes relative to the current context node, which is highly efficient. We need to be aware of the fact that the given SelectSingleNode() statements may, or may not return data:
var category = a.SelectSingleNode("./td[1]//a/text()");
var title = a.SelectSingleNode(".//div[@class='title']/a/text()");
var date = a.SelectSingleNode(".//div[contains(@class,'modified')]/text()");
var rating = a.SelectSingleNode(".//div[contains(@class,'rating-stars')]/@title");
var desc = a.SelectSingleNode(".//div[@class='description']/text()");
var author = a.SelectSingleNode(".//div[contains(@class,'author')]/text()");
Also note that the individual field selections use XPath statements that are semantic in nature wherever possible, such as 'title', 'rating-stars', and 'author'!
That's it. Happy scraping!
Revision History
- 20th February, 2018: Added project sample download, fixed image links

