Introduction
We have a long way to go, thus, in order to quickly set the stage, we consider the following pseudo code we often encounter:
List<T> data = CreateData(...)
ProcessList(data)
As per the above example, we declare, "CreateData" as our Data-Producer (or simply Producer) and "ProcessList" as our Data-Consumer (or simply Consumer). Then we consider the following description of our goal:
Our Goal:
Given two (2) pieces of code, one generates data (thus, calling producer) and another performs data-procesing (thus, calling consumer) and assuming that each data instance can be processed independently; we are interested in designing a generic mechanism that leverages data-parallelism, enables concurrent data-processing, and at the same time hides associated thread-synchronization intricacies and offers a simplified API.
Now after the goal is announced, we need to decide on the approach and for that, when we look into the literature, we take inspiration from long known concept of producer-consumer (one can find information of its generic case in this Wikipedia article). We would like to adapt this concept, to distribute workload (received from producers) among consumers while letting all the entities (all producers/consumers) running CONCURRENTly. During our discussion, we will go through, step-by-step, a possible implementation of it, i.e., to have our producer(s) running independently, yet in harmony, of our consumer(s). We will see how to create such a concert (here onward, calling it Pipeline) while satisfying the following design requirements:
- Buffer Size:
- Chain characteristics:
- lossless (every item that is produced is consumed) versus lossy (produced items are discarded when buffer is full)
- uninterrupted (once started, pipeline continues until the last item is consumed) versus interruptible (ability to destroy the pipeline at anytime during its life-cycle)
- concordant (producer/consumer shares exactly same
datatype) versus discordant (produced items require some sort of possible data transformation to match consumable item's datatype) - attached (all producers are known at
compile-time and bound to the chain) versus detached (producers, perhaps ephemeral, appear, possibly in parallel, at run-time): We will discuss implementation of these two cases separately.
Although the original producer-consumer problem considered only the CONCORDANT case (third (3rd) point among above characteristics), thanks to GoF's famous Adapter design pattern (see GoF design patterns), we would like to extend the idea, while stretching the original philosophy of the design pattern, in order to create a data oriented adapter (here onwards, simply calling it adapter unless specified otherwise), in order to create such a pipeline among given discordant producer/consumers (given a condition, we identify an adapter). The point of interest in doing so is to maintain separation of concerns, and, thus, to achieve simplified pipeline with detached data transformation logic.
Why ".Pipe"? To understand it, for a moment, imagine the date-flow and think of a simplistic view of data originating at producer and absorbed by consumer. Think of, as if there are two persons (P and C) and P is handing over whatever he got to C. With this, I think of UNIX. As, with UNIX terminal when we want to create such a chain of actions (passing data between commands); it exactly lets us do that, thanks to famous "|" (a.k.a. pipe) syntax (see some examples here), and, so I thought of this name.
The Why?
When we talk about why we need such an implementation, we need to consider several factors:
- along with order of complexity (the big O notation), latency is also an important factor in production quality code
- parallel computing has become a norm in industry and in several scenarios can help reduce latencies
- with the advancement in technology, newer frameworks/libraries/packages provide better tools for concurrent programming such as better thread-pool management, lighter substitutes to threads (e.g., task, fiber, coroutines) to lower waste cycles due to thread context switching
Now, talking about our pipeline, let's consider a task at hand (perhaps trivial):
Assume, we need to parse a file, let's say CSV for simplicity sake, that contains some considerable number of records (i.e., rows). Further assume that we need to store these records to some database; without any additional computation on the data.
Here, we observe two (2) distinct and uncorrelated sub-tasks: read the file (producer) & save data in database (consumer). Now, consider two(2) classic (non-concurrent) implementation approaches:
- Read full file -> make objects' list -> push the list to db (let's call it
Approach1)
- the approach looks good but ignores the memory requirements to hold the list
- bigger the list size, higher the latency due to the fact that consumer will wait longer to receive the list
- total latency would be:
file_handling_time + db_transaction_time => assuming data transfer time between producer and consumer is negligible
- read single line -> push the object to db -> repeat until end of file (let's call it
Approach2)
- improves on memory but performs multiple db transaction that can push latency off the charts => normally, bulk inserts are cheaper
- at a given point in time, either producer is working or consumer is working
- total latency would be: n x (
single_record_handling_time + db_transaction_time) => where n is total number of records in file and assuming data transfer time between producer and consumer is negligible)
Most importantly, both approaches ignore the fact that both, file and database operations, are I/O operations, and, given even a single core processor, concurrency can be achieved through thread-interleaving thanks to non-blocking I/O. It is also possible to design yet another balance approach where instead of pushing single record to db, we will push some fixed-size (chunk) lists to database. However, as we describe about our pipeline approach next (below), one can see that it remains less attractive in term of performance.
Assuming that we have our .Pipe implementation available. We can design a producer method (reading the file) and consumer method (making db transaction), we can simply write the above code as: producer.Pipe(consumers) (let's call it Approach3).
- producer will create several lists (pre-defined size) while reading the file => several list of smaller size (i.e., chunks). Chunk size can be adjusted to have optimal bulk insert, let's say.
- consumer will take each list (chunk) and push it to DB => we can span many consumers as each push is independent
- our glue code of
.Pipe will facilitate the channeling of chunks (lists) from producer to consumers => assuming this data transfer time is negligible and buffer is unbounded - total latency would be:
file_handling_time + k x chunk_db_transaction_time => where k = 1/c x (total_chunk_count - chunk_pushed_during_file_operation) and c = total_consumer_count (assuming degradation in db performance due to parallel push is negligible)
With such an approach, we make the following significant observations:
- As a benefit of concurrency between producer and consumer: we are able to consume data (in this case, push it to db) while producer hasn't finished his work (in this case, reading file)
- As a benefit of concurrency among consumers: we are able to reduce the end-to-end latency (in this case, by a factor of
1/c where c is count of consumers) - Thus, speaking theoretically, we can add total of n (where
n ~ total_records / chunk_size) consumers in our pipeline to obtain minimal latency ~ file_handling_time + chunk_db_transaction_time.
In general, as total number of records increases, we would notice (left-most is lowest and right-most is highest): (lower the better)
- memory(
Approach2) < memory(Approach3) < memory(Approach1) - latency(
Approach3) < latency(Approach1) < latency(Approach2)
Thus, perhaps, it might be safe to say that our concurrent pipeline approach is a balanced approach. Thus, the why.
However, before we discuss implementation, we need to consider/make the following limitations/assumptions:
- Presence of more than 1 consumer is to achieve concurrency benefits. This assumption is important as our design is different that
broadcasting (see here). In our approach, each produced item will be consumed (accepted/treated/processed) by one and only one consumer among all available consumers. - Although producers can take a different approach to create an item (e.g., one producer fetching records from DB, another from file, yet another receiving web-requests, etc.); yet, those are obliged to produce item of same
datatype to be part of the pipeline. This assumption is very important as pipeline design must remain open to disparate producer channels as long as produced items are of same type. - Consumers cannot be added or removed from pipeline once it is constructed.
- Implementation must remain generic, i.e., it should not make any assumption about the behavior of producer/consumer.
- In both fixed-size and unbounded buffer case, pipeline should support infinite number of producers and consumers, theoretically.
- In interruptible mode, pipeline will be destroyed once interrupted, thus, all unprocessed data with it.
- In attached mode, producers cannot be added or removed from pipeline once it is constructed.
- In detached mode, pipeline should not make any assumption about the life-cycle or count of producers. It must be open to accept items (pre-defined type) from any producer (ephemeral or long-running) during its life-cycle.
- In discordant mode, given an adapter, pipeline construction must be possible.
About Implementation
The idea of producer-consumer is actually language neutral and can be developed in several programming languages. However, to achieve our goal, we opt to implement it in C# .NET Framework 4.6.1 while leveraging several TPL features (especially async-await) and inherent language capability to create extension methods. If you are interested in consuming this implementation, based on your choice of language, you may achieve different usage forms.
During our discussion, we have provided a lot of comments along with C# .NET code snippets and added some amusing images (showing conversation among entities). Even if you feel uncomfortable with .NET syntax, do NOT be worried, you would be able to get the essential while reading this article and would be able to implement it in the language of your choice.
There are No Dinosaurs!
During my college days, I always asked myself, every time I took the operating system book in my hand, why the dinosaurs? (unfortunately, I cannot find the original cover but this picture should do for the moment) And, I used to cajole myself that the book is not as terrifying as Jurassic Park of Steven Spielberg. I still wonder, sometimes, was it to symbolize operating system as gigantic/fascinating/stupefying as dinosaur or was it just to overwhelm a sophomore. Nonetheless, it is NEITHER the right time NOR the subject of our discussion, thus, whatever the case, during this discussion, there are no dinosaurs and we will try our best to keep things simple.
Creating Interfaces (Contracts)
To begin with, let's have a look at the following simple picture to understand a few of our design choices and more importantly, what we are actually trying to build:
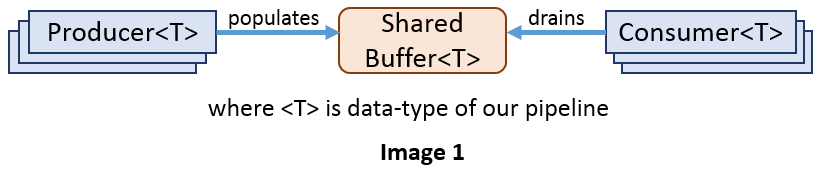
So based on the above picture, we want:
- to standardize the way producer will procure the buffer and add items in it, in ISOLATION, i.e., unaware of the presence of other producers or consumers.
- to standardize the way consumer can retrieve those populated items from the buffer and perform required processing, in ISOLATION, i.e., unaware of the presence of other consumers or producers.
- have a buffer that can handle those concurrent operations.
In order to design our solution, we would like to focus on the buffer as it is going to be the central piece of our solution; and, its implementation is going to be impacted by the producer side requirements as well as of consumer, plus we should not forget that we need to diffuse all the features to our design. Thus, in order NOT to complicate the discussion with everything explained in a single silo based proposed solution, we further sub-divide the discussion into several smaller pieces as follow:
1. Our Producer and Buffer
As our solution is producer agnostic, i.e., we do not know how exactly the producer would produce an item (i.e., the actual producer implementation). In this case, we can only define a generic signature of it and thus our producer can be defined as simple as the following delegate:
public delegate Task ProduceAsync<TP>
(IProducerBuffer<TP> buffer, CancellationToken token);
Based on the above delegate signature, we can create the following interface for our producer:
public interface IProducer<TP> : IDisposable
{
Task InitAsync();
Task ProduceAsync(IProducerBuffer<TP> buffer, CancellationToken token);
}
Now, the actual producer implementation can simply inherit IProducer<TP> interface. Though we have designed how to provide buffer access to our producer, however, we don't yet know how to populate the buffer. Thus, our first requirement at buffer side, i.e., to have some method for population. Let's look at it:
public interface IProducerBuffer<T>
{
void Add(T item, CancellationToken token);
bool TryAdd(T item, int millisecTimeout, CancellationToken token)
}
Thus, till now, we have producer and its buffer interfaces, and so, the means to add produced items to buffer. Now, let's look at the consumer side requirements next.
2. Our Consumer and Buffer
Similar to producer, our solution is also consumer agnostic (i.e., unaware of the actual consumer implementation), thus, in a similar way, we can define the following consumer interface:
public interface IConsumer<TC> : IDisposable
{
Task InitAsync();
Task ConsumeAsync(TC item, CancellationToken token);
}
while deciding about the consumer interface, especially the signature of ConsumeAsync, we had a choice to pass the buffer as method parameter as we did for producer. However, doing so, we noticed such design:
- burdened the consumer implementation with boiler-plate code
- required delicate implementation to loop over the buffered items
- added further complexity for our discordant pipeline feature (to be discussed later)
Thus, finally, we decided to hide such complexity within the API and obtained a callable consumer. In such a way, the concrete consumer implementation shall focus on the business logic.
Though, no apparent requirement visible at consumer side, yet we can infer from point (2) above that we need to loop over the items in order to drain the buffer. Thus, we need:
- a method to pop-out the item
- a boolean indicator to verify that all items are processed
So, we create our ConsumerBuffer interface:
public interface IConsumerBuffer<T>
{
bool Finished { get; }
bool TryGet(int millisecTimeout, CancellationToken token, out T data);
}
3. Keeping Both Shards
Until this point, we are trying to fulfill all the requirements, and following item list quickly covers those points:
- Buffer Size: We will control using a
Ctor parameter. - Losslessness: controlled based on
millisecondTimeout parameter of TryAdd method. (Note: Add method is similar to TryAdd(item, Timeout.Infinite)) - Interruptibility: controlled using
CancellationToken - Attachability: end-user controlled (we will see use-cases separately)
Now, the only remaining point is Concordance. In fact, the way we have defined our interfaces above, we have intentionally kept TP as producer type parameter and TC as consumer type parameter. Although, such different symbols (type placeholders) hardly matters in generics, nonetheless, it is to impose the idea that we will inject IDENTICAL <data-type> for both TP and TC during concordant pipeline construction and different <data-types> for discordant pipeline. Furthermore, for a rapid understanding of such a conflict, we offer the following illustration:

Now, we see that:
- producer can add item only when producer's
datatype <TP> is the same as buffer's datatype <T> - consumer can drain items only when consumer's
datatype <TC> is same as buffer's datatype <T> - only for a special case, that we call concordant pipeline, when all the three (3)
datatypes are the same, i.e., <TP> = <TC> = <T>, our current pipeline can work
Thus, the above design will not work in case of discordant pipeline. With this idea in mind, we keep both shards of our *Buffer interface, for the moment. Even from the point of view of "abstraction", we would be wise to NOT expose TryGet method to producer whose only interest is to fill the buffer.
4. Plugging Adapter
To fulfill our last requirement, we need to review our Image 2 as shown above; as having different datatypes will create conflict. But, before we talk about how to overcome this limitation using adapter, let's visualize what adapter must do logically based on the below picture:
Thus, if we consider provided adapter as a black box, we expect that by passing an object of type <TI>, it will output an object of type <TO>. As per our requirements, thus, if we pass produced items of type <TP> and convert those into consumer's type <TC>; our pipeline should work.
IMPORTANT: In order to remain generic, for the concordant case, when TC = TP = T (thus, TI = TO), we prepare a default IDENTITY adapter that does NOTHING, i.e., it returns us back the same item that we provided as input without making any change in it. The following C# .NET code snippet roughly represents this idea:
public static TI IdentityAdapter<TI>(TI input)
{
return input;
}
In order to plug such an adapter, we have the following choices:
- Inject adapter between Producer and Buffer: We design buffer with type
<TC> (shown in image 4):
- Inject adapter between two buffers: We introduce a second buffer and inject adapter between those, while first buffer has type
<TP> and second has type <TC> (shown in image 5):
- Inject adapter between buffer and Consumer: We design buffer with type
<TP> (shown in image 6):
Among the given implementation choices, we opt to choose the third (3rd) option, i.e., injecting adapter between buffer and consumer, because:
- by injecting adapter between producer and buffer, we complicate the producer implementation:
- by demanding producer to make adapter call
- by further increasing the risk of mal-implementation for delicate corner-case object transformations (we will see one example of such a transformation)
ProduceAsync method signature will be burdened with third (3rd) parameter (adapter instance)
- by injecting adapter between two buffers, we complicate our Pipeline implementation:
- we need to maintain two (2) buffers
- we need to synchronize two (2) buffer loops (buffer drainage)
By injecting adapter between buffer and consumer, we only need to maintain a single buffer (thus, single drainage loop), but also, we make a transparent call to adapter just at right time (before feeding data to consumer). And, by doing so, we hide all these intricated implementation details behind our .Pipe call and offer complete separation of concerns among producer, consumer and adapter so that all these three (3) pieces of code can evolve independently.
5. Vicious Cycle of Agnosticism
Up until now, we kept our design both producer and consumer agnostic, however, in order to keep the complexity out of our discussion, we assumed a naive approach to the Adapter. As shown above, we provided an object instance, of some given type, to our adapter and receive back an object instance of a well defined type. However, as we are close to finalizing our interface design, we would like to get rid of this give-n-take assumption about our adapter. In fact, we desire to finalize the design as Adapter agnostic too! And, this is the only way we are sure that we have provided full liberty to the end-user to achieve the desired end result from such pipeline without hacking/patching business logic. End-user can then focus on actual logic and associated data-model without worrying about mundane technical plumbing between producer, consumer, and adapter.
To achieve such Adapter agnostic design, we propose following interfacing:
public interface IDataAdapter<TP, TC>
{
bool TryGet(IConsumerBuffer<TP> buffer, CancellationToken token, out TC consumable);
}
Now as we have defined all the three (3) key parts of the pipeline, given any task and assuming that our pipeline can be implemented, we can achieve an optimal solution by thinking in terms of these sub-components as shown below:
The following itemized list summarizes the above idea:
- First, we work on optimal strategy to produce items
- Second, we finalize an optimal strategy to consume those produced items
- If an adapter is required, we separately write the adapter, otherwise we use
IDENTITY adapter - We plug all the three (3) pieces to the pipeline
Before Getting Crazy with Code!
Until this point, we tried to use a lot of drawings to convey our ideas, but, unfortunately, now we are obliged to introduce the code, and, thus, below you will see some long code snippets. But do NOT be worried, we will add some amusing drawings to illustrate the same idea in psuedo manner; nonetheless, you must memorize the pyramidical mind-map given below which is closely related to our concrete implementation:
Implementing Interfaces (Contract Completion)
As we are aware that our solution is producer/consumer/adapter agnostic, thus, their respective concrete implementation is not our concern; once we have exposed our interfaces, end-user will inherit those to use in the pipeline. However, it would be nice to implement some default Adapters in order to cover some mundane use cases. Thus, in this section, we will propose the following implementations:
- Adapters:
- Identity Adapter
- Awaitable List Adapter
- Buffer
- Attached pipeline
- Detached pipeline
1.a Identity Adapter
To start simple, we choose to implement identity adapter first and if we remember from above, it should just return the produced item as it is. We achieve this as follows:
public class IdentityAdapter<T> : IDataAdapter<T, T>
{
public bool TryGet(IConsumerBuffer<T> buffer, CancellationToken token,
out T consumable)
{
return buffer.TryGet(Timeout.Infinite, token, out consumable);
}
}
1.b Awaitable List Adapter
A Word before Implementation
Sometimes, we encounter a case when consuming single item leads to a suboptimal solution; and processing those in group (chunks) is technically cost-effective. A few of such examples are:
- Database bulk inserts are cheaper
- Batch processing
- Object array streaming ... so on and so forth...
In order to handle such use cases, we have decided to implement awaitable list adapter, so that end-user is relieved and use it out of the box. The idea is to recover List<TC> on each TryGet call on the adapter as shown below in image 7.
NOTE: Now onwards, we will use words "chunk" and "list" interchangeably, i.e., unless and until specified otherwise, list would mean a subset (a part of) of whole data.
As soon as we think about list, the following design related options come to mind related to TryGet method:
- Should we always return identically sized lists?
- Should we return variable size list, with some cap on size?
- Should we return list without any cap on size?
For the first (1st) option, given the fact that it might NOT be possible to generate identically sized list (consider if we have total of 103 items and we fixed the list size to be 10, then the last list will contain ONLY 3 items instead of 10); yet, we choose to implement it based on the belief that consumer logic is indifferent to the size of the chunk (and it should!) and the whole idea behind consuming chunks (instead of single instance) is to reduce associated technical latency.
The second (2nd) option is a generalized case of the first option, so we will implemented it but with some assumptions. These assumptions we will underline when we describe our implementation details.
We choose to opt out the third (3rd) option because it again questions the usefulness of spanning multiple consumers. Let's rethink that if we are able to supply unbounded lists to consumers, then perhaps we are able to supply available items to a single consumer alone irrespective of the fact whether consumer has a capacity to handle such a list or not; then why to span other consumers concurrently? Thus, we observe that our design is going astray (based on our pre-decided goal).
NOTE: Perhaps due to our myopic vision, we dropped implementing third (3rd) option. Still, not to forget that our pipeline is Adapter agnostic, thus, end-user can always construct their own version of Adapter and plug it in.
What's the BIG idea; ain't it simply List Adapter?
The short answer is: No. it isn't!
If you have followed us till now, perhaps you might got an impression that this adapter is all about creating a list, then why we call it "Awaitable" list adapter? Ain't it as simple as spanning a loop to produces list? If you have got similar thoughts, then we assure you that it's more than that; for the simplest fact that items we want to iterate might not be promptly awaitable. In fact, to elaborate further, let's consider below listed arguments:
- let's assume, the moment adapter's
TryGet method was called, the buffer was empty and producers were busy creating object instance, thus, soon there will be some items in the buffer but for the moment, we need to wait (sleep) - the actual questions are:
- how much should our thread sleep?
- what if after the wait buffer is still empty, i.e., producers not yet finished populating the buffer? Should we sleep again, then how much?
- let's say even if we came up with a very clever waiting algorithm, what about the case when producer populates the buffer just after we decided to sleep? (remember everything is running concurrently, so we have no control over the timings of those events!)
- should we also design thread wake-up mechanism?
- even if we decided not to wait and come out of the
TryGet call, we do NOT escape from this conundrum. And, all the above listed questions fall back at caller level (i.e., the code which called TryGet at the first place). - another question that comes to mind is what if the user does NOT want to wait too much before he can consume the chunk, i.e., what if user wants to consume available items without waiting for the future items to be accumulated (Perhaps his goals are time-sensitive, e.g., writing logs to files, pushing rows to DB, processing batch items etc.).
One thing is certain that if we want to reduce on latency (as a part of our goal), we need to have some kind of notification when the items arrive in the buffer, while our thread is asleep. Similar suggestion can also be found in the original producer-consumer problem. Now, of course, we do not want to build such a mechanism inside the adapter else it would fail the whole purpose (imagine, every time end-user/we write an adapter, we need to write a separate notification mechanism). Nonetheless, if we look into the literature of producer-consumer, we already know that producer is capable of providing such a signal (at the time of adding item in the buffer). Thus, considering both the perspectives, for the moment, we assume that the buffer is capable of such notification.
Based on the above discussion, we got following insights on buffer behaviour (we would use it during buffer's TryGet implementation):
- If buffer is empty, then within a given timeout period, if an element get populated, it shall come out of sleep as soon as possible (without waiting for the whole duration of sleep) and
out the element (with true as boolean return value) - If buffer has elements, then irrespective of timeout value, it should immediately
out an element (and true as boolean return value) - Buffer must be able to capture the
production_finished signal, and then, once all the buffered items are consumed, every subsequent TryGet call would result in false boolean return value (out as null/default of type).
For the moment, we can safely assume that if we pass INFINITE timeout to buffer.TryGet method, then buffer will return us an item as soon as it gets added. This resolves one of our concerns, but, we still need to work on both fixed-size list and variable-size list preparation.
Constraints/Assumptions
While implementing Awaitable List Adapter, we keep following important points in mind:
- We can ALWAYS wait on buffer with INFINITE timeout. If it has elements, it should promptly return one, else it should return one as soon as possible.
- No end-user is interested in consuming empty lists, i.e., list without any item in it. Thus, we only need to supply lists when it has AT LEAST one (1) element in it.
- End-user decides the size of the list as he is aware of system capabilities and his requirements.
- When end-user runs the pipeline to have FIXED size lists (as shown in Image 8):
- One is aware that we might need to wait longer to populate the list if some/every
buffer.TryGet ends up waiting for an item. Thus, one is INDIFFERENT to time taken to prepare such a list. - One is more interested in getting full sized list as it is advantageous based on his pipeline strategy.
- One is aware that the last chunk might be partial (as discussed above). But his consumer can handle it (
1 <= last_chunk_length <= length_of_full_size_list). - Thus, we can say he has infinite timeout but a preference for the size of the list.
- When end-user runs the pipeline to have Fixed duration lists (or variable sized) (as shown in Image 9):
- One prefers to consume something within a given time limit than to wait longer to have the list fully populated. Thus, one is time-bounded.
- One is aware that every chunk might be of different size and his consumer can handle it (
1 <= chunk_size <= max_length) - One is aware that he might need to wait longer to have the first (1st) item of the list if
buffer.TryGet ends up waiting for the first (1st) item - Thus, we can say he has preferences for timeout duration (once the first item is received) and for maximum size of the list.
NOTE: We discuss some possible use-cases of these adapters separately (below) in the article.
Implementation
Based on our constraints/assumptions, we have two parameters to deal with:
- List size and
- Timeout period
And we already know if timeout=Infinite, then we are outputting fixed-size list, else variable-sized list. Let's look at the code then:
public class AwaitableListAdapter<T> : IDataAdapter<T, List<T>>
{
private read only int _millisecTimeout;
private readonly int _maxListSize;
public AwaitableListAdapter(int maxListSize, int millisecTimeout)
{
_millisecTimeout = millisecTimeout;
_maxListSize = maxListSize;
}
public bool TryGet(IConsumerBuffer<T> buffer, CancellationToken token,
out List<T> consumable)
{
consumable = default(List<T>);
if (!buffer.TryGet(Timeout.Infinite, token, out var value)) return false;
consumable = new List<T>(_maxListSize) {value};
return _millisecTimeout == Timeout.Infinite
? TryFillFixedSize(buffer, token, consumable)
: TryFillFixedDurationChunk(buffer, token, consumable);
}
private bool TryFillFixedSize(IConsumerBuffer<T> buffer, CancellationToken token,
List<T> consumable)
{
while (consumable.Count < _maxListSize)
{
if (buffer.TryGet(Timeout.Infinite, token, out var value))
{
consumable.Add(value);
}
else return true;
}
return true;
}
private bool TryFillFixedDurationChunk(IConsumerBuffer<T> buffer,
CancellationToken token,
List<T> consumable)
{
var timeRemains = _millisecTimeout;
var sw = Stopwatch.StartNew();
while (consumable.Count < _maxListSize)
{
if (buffer.TryGet(timeRemains, token, out var value))
{
consumable.Add(value);
if (timeRemains != 0)
{
timeRemains =
(int) Math.Max(0, _millisecTimeout - sw.ElapsedMilliseconds);
}
}
else return true;
}
return true;
}
}
2. Implementing Buffer
At this point, we already have buffer interface and behavior based implementation requirements. Using the below code written snippet, we achieve these requirements:
public class PpcBuffer<T> : IProducerBuffer<T>, IConsumerBuffer<T>
{
private readonly CancellationToken _token;
private BlockingCollection<T> _collection;
public PpcBuffer(int bufferSize, CancellationToken token)
{
_collection = bufferSize.Equals(0) ? new BlockingCollection<T>()
: new BlockingCollection<T>(bufferSize);
_token = token;
}
public void Add(T item, CancellationToken token)
{
TryAdd(item, Timeout.Infinite, token);
}
public bool TryAdd(T item, int millisecTimeout, CancellationToken token)
{
using (var mergeToken =
CancellationTokenSource.CreateLinkedTokenSource(token, _token))
{
return _collection.TryAdd(item, millisecTimeout, mergeToken.Token);
}
}
public bool TryGet(int millisecTimeout, CancellationToken token, out T data)
{
return _collection.TryTake(out data, millisecTimeout, token);
}
public bool Finished => _collection.IsCompleted;
public void CloseForAdding()
{
_collection.CompleteAdding();
}
}
With such an implementation, we are able to cover all the requirements as discussed above. Now, all that remains is the plumbing of these individual artifacts. And, so we do separately for both attached and detached pipeline below.
3. Attached Pipeline
As we have discussed, attached pipeline mode has the following characteristics:
- Consumers cannot be added or removed from pipeline once it is constructed.
- Producers cannot be added or removed from pipeline once it is constructed.
- Pipeline can be formed in both way: Concordant and Discordant
Raw Implementation
As our interest is to create the form producers.Pipe(consumers), we first need to device a raw implementation as fabricating final form would be just a matter of creating an extension method. We will create this method separately. Approach of our raw implementation would revolve around the following idea:
- Run all producers independently as async methods
- Run all consumers independently as async methods
- Feed Adapter transformed items to consumers
- Observer producers as they completes production
- Signal buffer once all producers are done
- Dispose producers as they finish their work
- Let consumers consume finish all remaining items
- Dispose consumers
NOTE: We have used one of home-made extension methods to span and await on tasks (for both producers/consumers) :
- Signature:
static Task WhenAll(this Func<int, CancellationToken, Task> func, int repeatCount, CancellationToken token = default(CancellationToken)) - Implementation details: Please see here.
The following approach implements all the above listed steps:
internal static class PipeImpl<TP, TC>
{
public static Task Execute(CancellationToken token,
int bufferSize,
IDataAdapter<TP, TC> adapter,
IReadOnlyList<IProducer<TP>> producers,
IReadOnlyList<IConsumer<TC>> consumers)
{
return Task.Run(async () =>
{
using (var localCts = new CancellationTokenSource())
{
using (var combinedCts = CancellationTokenSource
.CreateLinkedTokenSource(token, localCts.Token))
{
using (var ppcBuffer = new PpcBuffer<TP>(bufferSize,
combinedCts.Token))
{
var rc = RunConsumers(consumers, ppcBuffer, adapter,
combinedCts.Token, localCts);
var rp = RunProducers(producers, ppcBuffer,
combinedCts.Token, localCts);
await Task.WhenAll(rc, rp).ConfigureAwait(false);
}
}
}
});
}
internal static Task RunConsumers(IReadOnlyList<IConsumer<TC>> consumers,
IConsumerBuffer<TP> feed, IDataAdapter<TP, TC> adapter,
CancellationToken token, CancellationTokenSource tokenSrc)
{
RunConsumer method) in the list
return new Func<int, CancellationToken, Task>(async (i, t) =>
await RunConsumer(consumers[i], feed, adapter, t, tokenSrc)
.ConfigureAwait(false))
.WhenAll(consumers.Count, token);
}
private static async Task RunConsumer(IConsumer<TC> parallelConsumer,
IConsumerBuffer<TP> feed, IDataAdapter<TP, TC> adapter,
CancellationToken token, CancellationTokenSource tokenSrc)
{
try
{
using (parallelConsumer)
{
await parallelConsumer.InitAsync().ConfigureAwait(false);
token.ThrowIfCancellationRequested();
while (adapter.TryGet(feed, token, out var consumable))
{
await parallelConsumer.ConsumeAsync(consumable, token)
.ConfigureAwait(false);
}
}
}
catch
{
if (!token.IsCancellationRequested) tokenSrc.Cancel();
throw;
}
}
private static Task RunProducers(IReadOnlyList<IProducer<TP>> producers,
PpcBuffer<TP> buffer, CancellationToken token,
CancellationTokenSource tokenSrc)
{
return Task.Run(async () =>
{
try
{
RunProducer method) in the list
await new Func<int, CancellationToken, Task>(async (i, t) =>
await RunProducer(producers[i], buffer, t, tokenSrc)
.ConfigureAwait(false))
.WhenAll(producers.Count, token).ConfigureAwait(false);
}
finally
{
buffer.CloseForAdding();
}
});
}
private static async Task RunProducer(IProducer<TP> parallelProducer,
IProducerBuffer<TP> feed, CancellationToken token,
CancellationTokenSource tokenSrc)
{
try
{
using (parallelProducer)
{
await parallelProducer.InitAsync().ConfigureAwait(false);
token.ThrowIfCancellationRequested();
await parallelProducer.ProduceAsync(feed, token)
.ConfigureAwait(false);
}
}
catch
{
if (!token.IsCancellationRequested) tokenSrc.Cancel();
throw;
}
}
}
Achieving .Pipe Usage Form (Syntactic Sugar)
We have all the ingredients to cook our extension methods and we propose following four such methods to achieve different pipelines as we had discussed above:
- Concordant Pipeline: Producer type matches consumer type (i.e.,
<TP> = <TC>). Normally end-user needs to inject IDENTITY adapter to it, but we can implicitly do it inside our method as shown below:
public static Task Pipe<T>(this IReadOnlyList<IProducer<T>> producers,
IReadOnlyList<IConsumer<T>> consumers,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return PipeImpl<T, T>.Execute(token, bufferSize,
new IdentityAdapter<T>(),
producers, consumers);
}
- Discordent Pipeline with FIXED SIZE chunk: If Producer type is
<T>, then consumer type is List<T> and end-user seek fixed sized chunks. Normally, one needs to inject Awaitable List adapter to it, but we can implicitly do it inside our method as shown below:
public static Task Pipe<T>(this IReadOnlyList<IProducer<T>> producers,
IReadOnlyList<IConsumer<List<T>>> consumers,
int listSize,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return PipeImpl<T, List<T>>.Execute(token, bufferSize,
new AwaitableListAdapter<T>
(listSize, Timeout.Infinite),
producers, consumers);
}
- Discordent Pipeline with FIXED DURATION chunk: If Producer type is
<T>, then consumer type is List<T> and end-user seeks variable sized chunks created using fixed duration. Normally, one needs to inject Awaitable List adapter to it, but we can implicitly do it inside our method as shown below:
public static Task Pipe<T>(this IReadOnlyList<IProducer<T>> producers,
IReadOnlyList<IConsumer<List<T>>> consumers,
int listMaxSize,
int millisecondTimeout,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return PipeImpl<T, List<T>>.Execute(token, bufferSize,
new AwaitableListAdapter<T>
(listMaxSize, millisecondTimeout),
producers, consumers);
}
- Generic Pipeline: Producer type is
<TP> and consumer type is <TC> and IDataAdapter<TP, TC> implementation is available to end-user.
public static Task Pipe<TP, TC>(this IReadOnlyList<IProducer<TP>> producers,
IReadOnlyList<IConsumer<TC>> consumers,
IDataAdapter<TP, TC> adapter,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return PipeImpl<TP, TC>.Execute(token, bufferSize,
adapter,
producers, consumers);
}
4. Detached Pipeline
Detached pipeline differs a bit as we do not have producers instances available to us at pipeline construction time (i.e., while calling PipeImpl<TP,TC>.Execute) as we do have for attached mode. Due to the absence of these producers, we do not have any mechanism to populate our buffer. Also, we had discussed during our initial discussion, producers for such a pipeline may appear sporadically. Thus, unfortunately, we will NOT be able to achieve our desired producers.Pipe(consumers) usage form, however, we attempt to achieve a similar simplified usage form based on the following information:
- Actual producers are unknown and may appear sporadically to inject items in the pipeline
- Consumers cannot be added or removed from pipeline once it is constructed
- Pipeline can be formed in both way: Concordant and Discordant
Raw Implementation
As we do NOT have any single point in code to await on, we need to fabricate a way to keep our pipeline alive for the whole duration so that all produced items (by ephemeral sporadically appearing producers or long-running producers) can be added in it. For all pragmatic reasons, we measure such duration as: "The time duration starting from the moment when such a pipeline is constructed until the moment when the call to CloseForAdding method is made."
With these assumptions made and intentions declared, we proceed with detached Pipeline interfacing as follow:
public interface IPipeline<T> : IProducerBuffer<T>, IDisposable
{
}
Now, with IPipeline, we will be able to mimic all the producer related operations as we have done before (in RunProducers method of PipeImpl<TP, TC> static class). Let's look at the implementation:
internal sealed class PipelineImpl<TP,TC> : IPipeline<TP>
{
private readonly CancellationTokenSource _mergedCts;
private readonly PpcBuffer<TP> _feed;
private readonly Task _consumerTask;
private CancellationTokenSource _localCts;
public Pipeline(IReadOnlyList<IConsumer<TC>> consumers,
IDataAdapter<TP, TC> adapter,
CancellationToken token,
int bufferSize)
{
_localCts = new CancellationTokenSource();
_mergedCts = CancellationTokenSource.CreateLinkedTokenSource(token,
_localCts.Token);
_feed = new PpcBuffer<TP>(bufferSize, _mergedCts.Token);
_consumerTask = PipeImpl<TP, TC>.RunConsumers(consumers, _feed,
adapter, token, _localCts);
}
public void Add(TP item, CancellationToken token)
{
TryAdd(item, Timeout.Infinite, token);
}
public bool TryAdd(TP item, int millisecTimeout, CancellationToken token)
{
return _feed.TryAdd(item, millisecTimeout, token);
}
public void Dispose()
{
if (_localCts == null) return;
try
{
using (_localCts)
{
using (_mergedCts)
{
using (_feed)
{
_localCts.Cancel();
_feed.CloseForAdding();
_consumerTask.Wait();
}
}
}
}
finally
{
_localCts = null;
}
}
}
Instance Management
Contrary to attached pipeline, where we had a single place in code to await on the whole pipeline workflow, in detached mode we do NOT have such a luxury. Thus, end-users need to maintain the instance of IPipeline<TP> somewhere after the construction and explicitly call the Dispose on it. This, of course, requires some attentions, however, before rejecting the usage of this implementation, we need to meditate over following thoughts:
- Detached pipeline:
- does not demand the complete knowledge of all possible producers at construction time
- accepts items from both sporadic ephemeral producers and long-running producers
- offers loose coupling between consumers and producers
- facilitate concurrency
- offers thread-safety
- Detached pipeline, by its nature:
- useful in cases, where, consumers outlives producers by large (in most of the cases consumers might live for application life-time), examples:
- Web based (
WCF based, ApiController based etc) data processing - Background file processing
- Background Database operations
- Event based processing
- Timer based processing
- Async batch processing, so on and so forth...
- demands management of single instance that too can be conveniently maintained as:
- Singleton inside Dependency Injector container
- Static field/property etc...
- can be disposed as needed: when application shuts-down, after closing Network interface, etc.
Achieving .Pipeline usage form (Syntactic Sugar)
Above, we have already created .Pipe extension methods. In a similar manner, we can obtain the following .Pipeline methods:
- Concordant Pipeline: Producer type matches consumer type (i.e.
<TP> = <TC>). Normally, end-user needs to inject IDENTITY adapter to it, but we can implicitly do it inside our method as shown below:
public static IPipeline<T> Pipeline<T>(this IReadOnlyList<IConsumer<T>> consumers,
CancellationToken token = default(CancellationToken),
int bufferSize = 256)
{
return new PipelineImpl<T, T>(consumers,
new IdentityAdapter<T>(),
token, bufferSize);
}
- Discordent Pipeline with FIXED SIZE chunk: If Producer type is
<T>, then consumer type is List<T> and end-user seeks fixed sized chunks. Normally, one needs to inject Awaitable List adapter to it, but we can implicitly do it inside our method as shown below (IMPORTANT: As producers are sporadic, one might like to avoid this adapter completely as unnecessary consumer side delays will be observed if no producer appears for long time... in detached mode, FIXED DURATION chunk is preferred):
public static IPipeline<T> Pipeline<T>(this IReadOnlyList<IConsumer<T>> consumers,
int listSize,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return new PipelineImpl<T, T>(consumers,
new AwaitableListAdapter<T>
(listSize, Timeout.Infinite),
token, bufferSize);
}
- Discordent Pipeline with FIXED DURATION chunk: If Producer type is
<T>, then consumer type is List<T> and end-user seeks variable sized chunks created using fixed duration. Normally, one needs to inject Awaitable List adapter to it, but we can implicitly do it inside our method as shown below:
public static IPipeline<T> Pipeline<T>(this IReadOnlyList<IConsumer<T>> consumers,
int listMaxSize,
int millisecondTimeout,
CancellationToken token =
default(CancellationToken),
int bufferSize = 256)
{
return new PipelineImpl<T, T>(consumers,
new AwaitableListAdapter<T>
(listMaxSize, millisecondTimeout),
token, bufferSize);
}
- Generic Pipeline: Producer type is
<TP> and consumer type is <TC> and IDataAdapter<TP, TC> implementation is available to end-user.
public static IPipeline<TP> Pipeline<TP, TC>
(this IReadOnlyList<IConsumer<TC>> consumers,
IDataAdapter<TP, TC> adapter,
CancellationToken token = default(CancellationToken),
int bufferSize = 256)
{
return new PipelineImpl<TP, TC>(consumers,
adapter,
token, bufferSize);
}
Commentary
Feature Implementation
So far, we have implemented all the initially set requirements. Before we close this discussion, we would like to wrap our features:
| Feature Implementation |
| Feature | Implementation |
| Buffer Size | Through method parameter (bufferSize); 0 is unbounded |
| Losslessness | using millisecond Timeout during Add/TryAdd, Timeout.Infinite represents no-loss |
| Interruptibility | Using CancelationToken |
| Concordance | Use of Adapters |
| Attachability | Attached mode implementation using .Pipe extension methods
Detached mode implementation using .Pipeline extension methods
|
We have also noticed:
- Attached mode can make use of both
FIXED SIZE and FIXED DURATION chunk adapters - Detached mode should avoid
FIXED SIZE chunk adapter to avoid unintentional latencies
Original Work (C# .NET) and Nuget Package
NOTE: You can omit this section completely, if you are not interested in consuming C# .NET library of ours.
In our original work (Source Code Link, NuGet Package Link), we have further elaborated our implementation as explained below:
- Adapter interfaces are implemented as
abstract classes, so that <TP> to <TC> data transformation can be done solely based on business logic without worrying about calls to buffer.TryGet (see AwaitableAdapter and AwaitableListAdapter)
Thus, it would be simple to inherit from either AwaitableAdapter<TP, TC> abstract class (if consuming single instances at a time) or AwaitableListAdapter<TP, TC> abstract class (if consuming data in chunks) instead of implementing IDataAdapter<TP, TC> interface. Such abstract class based inheritance would remain business-oriented as we purely write the data transformation logic inside Adapt method without worrying about buffer handling, and thus, further reducing boiler-plate code.
.Pipe and .Pipeline extension methods are also available on Action (synchronous delegates) and Func (task returning asynchronous delegates). Thus, avoiding the need to inherit IProducer and IConsumer interfaces when Init/Dispose methods are not warranted. (see PipeExts and PipelineExts)- Our current implementation is NOT capable of method chaining as we find in UNIX where we can chain multiple pipes as shown in following example:
ls -l | grep key | less (3 operations with 2 pipes)
- Our current implementation supports only
void consumers, i.e., consumers cannot have return values.
Usage
IMPORTANT: We suggest you to use v1.4.0 or higher; as it contains some breaking changes compared to previous versions. This library also contains some other interesting extension methods which we might cover in future articles on code-project itself. However, if you are interested in usage of those methods, you can find information here.
- If one wants to use
.Pipe implementation, instead of thinking about whole sln in a go, one must organise one's thoughts as follows:
- Create Producer(s) (in isolation):
- either implement
IProducer<TP> interface to populate the buffer IF Init/Dispose methods are required - or construct a lambda:
- Synchronous lambda signature:
Action<IProducerBuffer<TP>, CancellationToken> - Async lambda signature:
Func<IProducerBuffer<TP>, CancellationToken, Task>
- Create Consumer(s) (in Isolation):
- either implement
IConsumer<TC> interface to populate the buffer IF Init/Dispose methods are required - or construct a lambda:
- Synchronous lambda signature:
Action<TC, CancellationToken> - Async lambda signature:
Func<TC, CancellationToken, Task>
- Create Adapter (if an existing adapter does not fit the requirement):
- Either inherit from
AwaitableAdapter<TP, TC> or AwaitableListAdapter<TP, TC> if requirements fits and implement abstract method: abstract TC Adapt(TP produced, CancellationToken token) - Or implement
IAdapter<TP, TC> interface
- Choose one of the exiting
producers.Pipe(consumers) extension method and inject values as necessary.
- If one wants to use
.Pipeline implementation, one must organise one's thoughts as follows:
- Create Consumer(s) and Adapter as explained above for
.Pipe usage - Maintain
IPipeline<TP> instance as deemed fit:
- Inside Dependency Injector as Singleton
- As static field/property, etc.
- Call
Dispose on the instance as deemed fit:
- Inside App shutdown method
- After closing network connection
- After unregistering event handler so and so forth...
- Use the
IPipeline<TP> instance as required:
- Inside
ApiController - Inside
WCF endpoints - Inside
EventHandler - In batch method calls
- Inside
Timer based callbacks... so on and so forth
History
- 4th July, 2018: v1 of the present idea

