Contents
Introduction
This article explains how recommendation systems work in theory, demonstrates four different types of recommendation systems, and then provides an example using Code Project's challenge data.
While gathering research for this article, I noticed that most of the information out there either focuses entirely on the underlying math, is written in Python, or makes no attempt to test the system on real data. My goal in writing this article is to explain recommendation systems using as little linear algebra as possible, build the entire system in C#, and give you honest details about my results.
Foundation
Representation
A recommendation system is an algorithm that can be trained to make future recommendations based on a list of users, a list of items, and a list of ratings given to items by users.
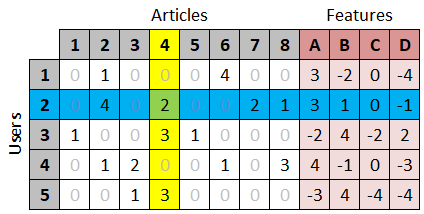
To make this data easier to visualize, we will represent it as a table where each row is a user, each column is an item, and each cell contains a rating.

For example, given our example table of 5 users and 5 items, we can see that user 3 (the blue row) gave a rating of 1 (the green cell) to item 2 (the yellow column).
The goal of our recommendation system will be to fill in the missing cells. To accomplish this, we will examine four types of recommendation engines.
User-Based Collaborative Filtering
The first recommender on our list is the user-based colloborative filter. This form of recommender is based on the assumption that users who have agreed in the past are likely to agree again in the future.
With our user-article table, we first need to find a list of users similar to the target user. We do this by comparing the item ratings of the target user to the item ratings of every other user in the table.
For example, since users 1 and 4 have both rated items 2 and 5, we can compute a similarity score between the 2 users based on those 4 ratings. Note that we are not comparing the entire user row; we are only comparing items which both users have rated.
There are several ways to compute the similarity scores between users, and all of them take two user rows as input and give a single numeric value representing the similarity as output. Algorithms commonly used for this include Cosine Similarity and Pearson Correlation, both of which are implemented in this project.
Once we compute a similarity score between the target user and every other user in the table, we can sort these similar users (or neighbors) and keep just the most similar (or nearest) ones. This algorithm is appropriately called the K-Nearest Neighbors (KNN) algorithm.
Now that we have a list of the users most similar to the target user (for which we are getting a recommendation), we can grab items read by these neighbors and recommend them to the target user.
For example, let us find a recommendation for user 1. First we search for his nearest neighbor, which turns out to be user 4 (based on similarities between items 2 and 5). From the table we can see that our closest neighbor (user 4) likes item 3, so we can recommend item 3 to user 1 who has not yet reviewed that item.
Item-Based Collaborative Filtering
Item-based systems work very similarily to user-based systems. When trying to find a suggestion for a given user, they find items similar to items the user has already seen.
The primary difference is that instead of finding the nearest users, we find the nearest items. For example, since user 4 liked item 2, we can find items similar to item 2 (such as item 5) and suggest it to user 4.
Model-Based Recommendation System
Model-based systems work differently than collaborative systems. Instead of attempting to make suggestions by finding similar users or items, they build a mathematical model to make predictions.
There are many different model-based algorithms to choose from. One of the more common approaches is called Singular-Value Decomposition (SVD), and works by factoring a user-item matrix into smaller matrices that can then be used to fill in missing ratings.
Actually, the pure math form of SVD does not work too well when you have missing values, so we will need to use a variation called SVD++ that is optimized for matrices with missing data. We will discuss this in detail later.
Hybrid Recommendation System
Hybrid systems simply combine multiple recommendation engines and utilize one of many algorithms to aggregate the individual results into a single recommendation.
Challenge Data
Now that we have a basic understanding of how recommendation systems work, we will walk through an example of putting one together. For this we will use the user behavior data from the Code Project challenge.
The data file we will be processing is divided into four sections: tags, articles, users, and user actions. Here is a small snippet of the file.
# Tags
Tag 1, Tag 2, Tag 3, Tag 4, Tag 5...
...
# Articles
# Article ID, Article Name
1,Article 1, Tag 1, Tag 5, Tag 23
2,Article 2, Tag 4, Tag 9, Tag 1, Tag 6, Tag 8
3,Article 3, Tag 9, Tag 7, Tag 19
...
# Users
# User ID, User Name
1,User 1
2,User 2
3,User 3
4,User 4
...
# User actions
# Day, Action, UserID, UserName, ArticleID, ArticleName
1,View,1,User 1,305,Article 305
1,View,2,User 2,7,Article 7
1,DownVote,2,User 2,7,Article 7
This set of data contains 30 tags, 3,000 articles, 3,000 users, and 105,873 user actions. When we parse this data into a user-item table (or matrix) in the next section, there will be 9,000,000 cells (3,000 users times 3,000 articles).
One of the problems that plagues recommender systems is the sparsity (lack of values) of the matrix. Our table may be able to hold 9 million ratings if every user rated every article, but in reality our matrix is 99.17% empty. That is a lot of missing data.
Before working with a new set of data, I feel it is helpful to spend time understanding it. I created several visualizations to help with this. First of all, it appears that the majority of users have interacted with somewhere between 20 and 29 articles across the data set.
When looked at from a different angle, we see that the number of articles that have been read by exactly N users is fairly uniform.
Another thing I did was generate a 3,000 by 3,000 pixel image to represent every user rating on every item. A black pixel means that the user in that row rated the article in that column. In the resized version of this image below, you can clearly see that there are three darker boxes.
For whatever reason, our data implies that the first 1,000 users typically prefer the first 1,000 articles, the second thousand users read the second thousand articles, and so on for the third. This is likely due to the way this data set was generated.
Our data will be split into two sets before we begin. The first set will contain the first 27 days worth of data and be used for training. The second set will contain the remaining 3 days and be used for validation after training finishes.
We split our data like this because we can not use the same data for testing as we do for training. To get a true measure of the accuracy of our recommender, we need data that was not used during training.
Development
Our requirement is to be able to get a list of suggestions for any given user, and to be able to predict a specific user's rating on a specific article.
To this end, we will develop several different recommenders in an attempt to create meaningful recommendations. Each recommender will implement the following interface which exposes a way to train a model, get suggestions for a user, predict a rating on an article, and save and load the trained model.
public interface IRecommender
{
void Train(UserBehaviorDatabase db);
List<Suggestion> GetSuggestions(int userId, int numSuggestions);
double GetRating(int userId, int articleId);
void Save(string file);
void Load(string file);
}
There are a few abstractions and common objects that we will be using throughout this project. We will look at these first, and then explain how they are implemented differently for each recommender.
The first object is the UserBehaviorDatabase class, which is what will hold the data we parse out of the training data file.
public class UserBehaviorDatabase
{
public List<Tag> Tags { get; set; }
public List<Article> Articles { get; set; }
public List<User> Users { get; set; }
public List<UserAction> UserActions { get; set; }
}
The next important item is the UserArticleRatingsTable class. This is what converts our list of user actions into a table of user-article ratings.
public UserArticleRatingsTable GetUserArticleRatingsTable(IRater rater)
{
UserArticleRatingsTable table = new UserArticleRatingsTable();
table.UserIndexToID = db.Users.OrderBy(x => x.UserID)
.Select(x => x.UserID).Distinct().ToList();
table.ArticleIndexToID = db.Articles.OrderBy(x => x.ArticleID)
.Select(x => x.ArticleID).Distinct().ToList();
foreach (int userId in table.UserIndexToID)
{
table.Users.Add(new UserArticleRatings(userId, table.ArticleIndexToID.Count));
}
var userArticleRatingGroup = db.UserActions
.GroupBy(x => new { x.UserID, x.ArticleID })
.Select(g => new { g.Key.UserID, g.Key.ArticleID, Rating = rater.GetRating(g.ToList()) })
.ToList();
foreach (var userAction in userArticleRatingGroup)
{
int userIndex = table.UserIndexToID.IndexOf(userAction.UserID);
int articleIndex = table.ArticleIndexToID.IndexOf(userAction.ArticleID);
table.Users[userIndex].ArticleRatings[articleIndex] = userAction.Rating;
}
return table;
}
In the middle of that method you can see that we are grouping by unique user-article pairs and then calling rater.GetRating() on the rows being aggregated into the group. This is because each unique user-article pair may have several actions in the data set. For example, this is what it would look like if user 84 performed 3 different actions on article 305.
1,View,1,User 84,305,Article 305
1,Upvote,1,User 84,305,Article 305
1,Download,1,User 84,305,Article 305
This list of actions for a given user-article pair needs to be turned into a single number that represents one user's rating for one article.
Since the user did not explicitly provide a rating, we need to generate an implicit one on his behalf. For now we just need to know that the IRater interface provides a way to turn a group of user-article actions in a single rating. Later we will find a way to optimize our method of calculating this rating.
public interface IRater
{
double GetRating(List<UserAction> actions);
}
One final interface to call out is the IComparer, which takes two vectors (either two users or two articles) and returns a single value indicating how similar or different they are. As previously stated, this project contains implementations of the Root Mean Square Error (RMSE), Cosine Similarity, and Pearson Correlation comparison algorithms.
public interface IComparer
{
double CompareVectors(double[] userFeaturesOne, double[] userFeaturesTwo);
}
With this information we can jump into designing some recommenders.
User-Based Collaborative Filtering
The first recommender we will train is a user-based collaborative filter. If you will remember from before, this type of system makes recommendations based on what similar users have liked. Here is what the training step looks like.
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
}
Pretty simple, right? All we are doing is generating a table of user-article pairs. The computationally complex part of a user-based k-nearest neighbor system is finding neighbors.
Here is where we finally get to generate a list of recommendations for a user. We start by calling GetNearestNeighbors(), which will loop through every user in the user-article matrix, calculate the similarity to the target user for each one, and then return the closest matches.
var neighbors = GetNearestNeighbors(user, neighborCount);
private List<UserArticleRatings> GetNearestNeighbors(UserArticleRatings user, int numUsers)
{
List<UserArticleRatings> neighbors = new List<UserArticleRatings>();
for (int i = 0; i < ratings.Users.Count; i++)
{
if (ratings.Users[i].UserID == user.UserID)
{
ratings.Users[i].Score = double.NegativeInfinity;
}
else
{
ratings.Users[i].Score =
comparer.CompareVectors(ratings.Users[i].ArticleRatings, user.ArticleRatings);
}
}
var similarUsers = ratings.Users.OrderByDescending(x => x.Score);
return similarUsers.Take(numUsers).ToList();
}
Once we have a list of the target user's most similar neighbors, we can loop through every possible article and get our closest neighbors' opinion on each one. If our neighbors' ratings for a given article are high enough, we will suggest it to the target user.
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
if (user.ArticleRatings[articleIndex] == 0)
{
double score = 0.0;
int count = 0;
for (int u = 0; u < neighbors.Count; u++)
{
if (neighbors[u].ArticleRatings[articleIndex] != 0)
{
score += neighbors[u].ArticleRatings[articleIndex];
count++;
}
}
if (count > 0)
{
score /= count;
}
suggestions.Add(new Suggestion(userId, ratings.ArticleIndexToID[articleIndex], score));
}
}
Once we have our neighbors' opinion on every article, we can sort our suggestions list by rating and return a few of the top rated ones.
var similarUsers = ratings.Users.OrderByDescending(x => x.Score);
If instead we want to predict whether a given user will enjoy a given article, we can use the GetRating() method.
public double GetRating(int userId, int articleId)
{
UserArticleRatings user = ratings.Users.FirstOrDefault(x => x.UserID == userId);
List<UserArticleRatings> neighbors = GetNearestNeighbors(user, neighborCount);
return GetRating(user, neighbors, articleId);
}
private double GetRating(UserArticleRatings user, List<UserArticleRatings> neighbors, int articleId)
{
int articleIndex = ratings.ArticleIndexToID.IndexOf(articleId);
var nonZero = user.ArticleRatings.Where(x => x != 0);
double avgUserRating = nonZero.Count() > 0 ? nonZero.Average() : 0.0;
double score = 0.0;
int count = 0;
for (int u = 0; u < neighbors.Count; u++)
{
var nonZeroRatings = neighbors[u].ArticleRatings.Where(x => x != 0);
double avgRating = nonZeroRatings.Count() > 0 ? nonZeroRatings.Average() : 0.0;
if (neighbors[u].ArticleRatings[articleIndex] != 0)
{
score += neighbors[u].ArticleRatings[articleIndex] - avgRating;
count++;
}
}
if (count > 0)
{
score /= count;
score += avgUserRating;
}
return score;
}
Once again, we will find all of the target user's neighbors and calculate their average rating on the given article. To account for the fact that each user behaves differently, we are normalizing the averages by subtracting the average rating from each individual neighbor and then adding the target user's average. This will help keep the predicted rating more in line with the target user's history instead of his neighbor's history.
Item-Based Collaborative Filtering
The next recommender we will explore is the item-based collaborative filter. This system works similarily to the user-based one, but instead of finding neighboring users, we will find neighboring items.
Before we get started, I wanted to point out that for this recommender we will also be including the article tag data. Each article has several tags, so we will append rows to our user-item table that will either be 1 (the article has the given tag) or 0 (it does not have the tag).
This will give us a little extra information to match on when looking for similar articles.
Just as before, we will create a giant table of user-article pairs. Notice that we are also appending extra article tag information.
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
List<ArticleTagCounts> articleTags = ubt.GetArticleTagCounts();
ratings.AppendArticleFeatures(articleTags);
FillTransposedRatings();
}
Before we find neighboring items, we need to figure out which items we are finding neighbors for. After all, we are looking for suggestions to give to a user, not another item. To do this, we will first find all the articles which the target user has rated.
List<int> articles = GetHighestRatedArticlesForUser(userIndex).Take(5).ToList();
private List<int> GetHighestRatedArticlesForUser(int userIndex)
{
List<Tuple<int, double>> items = new List<Tuple<int, double>>();
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
if (ratings.Users[userIndex].ArticleRatings[articleIndex] != 0)
{
items.Add(new Tuple<int, double>(articleIndex,
ratings.Users[userIndex].ArticleRatings[articleIndex]));
}
}
items.Sort((c, n) => n.Item2.CompareTo(c.Item2));
return items.Select(x => x.Item1).ToList();
}
Once we have this list of all the articles the target user has already read, we will find a few neighbors for each of those items, sort them, and then return them as our suggestion.
foreach (int articleIndex in articles)
{
int articleId = ratings.ArticleIndexToID[articleIndex];
List<ArticleRating> neighboringArticles = GetNearestNeighbors(articleId, neighborCount);
foreach (ArticleRating neighbor in neighboringArticles)
{
int neighborArticleIndex = ratings.ArticleIndexToID.IndexOf(neighbor.ArticleID);
var nonZeroRatings = transposedRatings[neighborArticleIndex].Where(x => x != 0);
double averageArticleRating = nonZeroRatings.Count() > 0 ? nonZeroRatings.Average() : 0;
suggestions.Add(new Suggestion(userId, neighbor.ArticleID, averageArticleRating));
}
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
To make it easier and faster to compute similarities between columns, I transposed the user-article matrix so that all user rows became columns and all article columns became rows. The resulting article-user matrix lets us easily compare articles using an IComparer.
for (int a = 0; a < ratings.ArticleIndexToID.Count; a++)
{
transposedRatings[a] = new double[features];
for (int f = 0; f < features; f++)
{
transposedRatings[a][f] = ratings.Users[f].ArticleRatings[a];
}
}
Due to the fact that we are finding neighbors for more than one item, this item-based recommender is a bit slower than the user-based recommender.
Model-Based Recommendation System
Next we will be performing a matrix factorization to extract features from our user-article matrix. This is one area where I will not be able to completely avoid discussing the underlying linear algebra that makes this work.
Matrix factorization, just like regular numeric factorization (e.g., 21 = 3 x 7), is a process of finding separate matrices that when multiplied together result in the original matrix. The theory is that if we can find two smaller matrixes that accurately approximate our user-article matrix, then we can hopefully also approximate the missing values.
When we factor our matrix, we can choose the number of features we want to use. This feature count ends up becoming one of the two dimensions of each matrix. For example, our user-feature matrix will have a the same number of rows as the user-article matrix, but will have a number of columns equal to the number of chosen features.
Picking the number of features is a bit of an art. If you have too few, you will not be able to learn the existing data. If you have too many, you may memorize (or overfit) the data instead.
These feature matrices contain all the information we need to approximate any value in the original matrix. We just need to compute the dot product between the appropriate user-features matrix column and the article-feature matrix row.
The dot product is defined as the sum of the inner product, so in the example below we can calculate user 2's rating for article 4 like this: (1 x 1) + (3 x 2) + (2 x -1) = 1 + 6 - 2 = 5
The cool thing here is that once you generate these feature matrices, you can use them to calculate the original values as well as fill in the missing values. This is how we will generate suggestions and predict ratings.
The only problem is that we can not use the pure math form of matrix factorization or we will learn to predict zeroes for missing data. We need a different way to find these matrices so that we only train on the non-zero values.
To find the optimal matrices, we are going to randomly try different values, see how well they perform, make small adjustments, and then try again. We will repeat this process untill our feature matrices can accurately predict the known values.
The algorithm we will be using is called Stochastic Gradient Descent, which is just a fancy way of saying we are going to iteratively adjust our input parameters until we get an output we like. Once again, we will start by looking at our training method. This time we will actually be training.
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
SingularValueDecomposition factorizer =
new SingularValueDecomposition(numFeatures, learningIterations);
svd = factorizer.FactorizeMatrix(ratings);
}
And here is where the actual work is done. This method will go through each user-article rating, compute the dot product for that rating using the feature matrices, and then figure out how much it was off by (the error). Using our gradient descent algorithm and the computed error, we can slowly adjust the values of our feature matrices so that we incrementally get closer to the correct result.
averageGlobalRating = GetAverageRating(ratings);
for (int i = 0; i < learningIterations; i++)
{
squaredError = 0.0;
count = 0;
for (int userIndex = 0; userIndex < numUsers; userIndex++)
{
for (int articleIndex = 0; articleIndex < numArticles; articleIndex++)
{
if (ratings.Users[userIndex].ArticleRatings[articleIndex] != 0)
{
double estimatedRating = averageGlobalRating +
userBiases[userIndex] + articleBiases[articleIndex] +
Matrix.GetDotProduct(userFeatures[userIndex], articleFeatures[articleIndex]);
double error = ratings.Users[userIndex].ArticleRatings[articleIndex] - estimatedRating;
squaredError += Math.Pow(error, 2);
count++;
averageGlobalRating += learningRate *
(error - regularizationTerm * averageGlobalRating);
userBiases[userIndex] += learningRate *
(error - regularizationTerm * userBiases[userIndex]);
articleBiases[articleIndex] += learningRate *
(error - regularizationTerm * articleBiases[articleIndex]);
for (int featureIndex = 0; featureIndex < numFeatures; featureIndex++)
{
userFeatures[userIndex][featureIndex] += learningRate *
(error * articleFeatures[articleIndex][featureIndex] -
regularizationTerm * userFeatures[userIndex][featureIndex]);
articleFeatures[articleIndex][featureIndex] += learningRate *
(error * userFeatures[userIndex][featureIndex] -
regularizationTerm * articleFeatures[articleIndex][featureIndex]);
}
}
}
}
squaredError = Math.Sqrt(squaredError / count);
rmseAll.Add(squaredError);
learningRate *= learningDescent;
}
Here is a step-by-step explaination of what that big block of code is actually doing. When we first start training, the values in our feature matrices are random. For now let us just look at one cell and its corresponding user and item features.
All we know at this point is that user 2 gave article 4 a rating of 5. We start by computing the dot product for this rating using our initially random feature matrices.
Our estimate came back as 9, which is incorrect. To figure out just how wrong we were, we will subtract the correct value from the estimated value and see we were off by 4.
Then we plug this into our gradient descent algorithm, which adjusts the values in our original feature matrices towards the correct values. The 0.02 value is the training speed, and the 0.01 is a value that helps prevent over-adjusting during training.
With these new features, we can once again calculate the value of this cell. This time our estimate is a lot closer.
You may notice that in the code there is a global average rating as well as biases for each user and each article. This helps us remove any variability between users or articles in case some users tend to rate higher than others. This way all ratings are on the same level.
We can track the overall accuracy of our model by calculating the root mean square error after each iteration. The RMSE is calculated by subtracting the expected result from the actual result for every user-article pair, squaring it, adding it to a running total, and then taking the square root.
Our goal is to minimize the RMSE during training; however, we will eventually reach a point where it does not make sense to train any longer. If we try to squeeze out every last bit of error, we risk overfitting our model (where it memorizes a few past samples instead of learning a general rule).
Now we are ready to make suggestions based on our trained model. We will do this by first calculating a rating for each article the target user has not yet read. Then we will sort the list by rating and suggest the highest rated ones.
public List<Suggestion> GetSuggestions(int userId, int numSuggestions)
{
int userIndex = ratings.UserIndexToID.IndexOf(userId);
UserArticleRatings user = ratings.Users[userIndex];
List<Suggestion> suggestions = new List<Suggestion>();
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
if (user.ArticleRatings[articleIndex] == 0)
{
double rating = GetRatingForIndex(userIndex, articleIndex);
suggestions.Add(new Suggestion(userId, ratings.ArticleIndexToID[articleIndex], rating));
}
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
return suggestions.Take(numSuggestions).ToList();
}
Calculating a rating for a given user and article is extremely simple and fast. We just need to compute the dot product from the feature matrices and add in the biases.
public double GetRating(int userId, int articleId)
{
int userIndex = ratings.UserIndexToID.IndexOf(userId);
int articleIndex = ratings.ArticleIndexToID.IndexOf(articleId);
return GetRatingForIndex(userIndex, articleIndex);
}
private double GetRatingForIndex(int userIndex, int articleIndex)
{
return svd.AverageGlobalRating +
svd.UserBiases[userIndex] + svd.ArticleBiases[articleIndex] +
Matrix.GetDotProduct(svd.UserFeatures[userIndex], svd.ArticleFeatures[articleIndex]);
}
Hybrid Recommendation System
Our final recommender is not really a recommender itself, but a grouping of multiple recommenders. This system will take the outputs of multiple other recommenders and aggregate them into what is hopefully a better suggestion than each of its component recommenders. Training is very straightforward.
public void Train(UserBehaviorDatabase db)
{
foreach (IRecommender classifier in classifiers)
{
classifier.Train(db);
}
}
There are many ways that hybrid systems aggregate results from component recommenders, but for our purposes we will simply return an equal number of suggestions from each system. This will hopefully allow one system to catch an article that another system did not find.
public List<Suggestion> GetSuggestions(int userId, int numSuggestions)
{
List<Suggestion> suggestions = new List<Suggestion>();
int numSuggestionsEach = (int)Math.Ceiling((double)numSuggestions / classifiers.Count);
foreach (IRecommender classifier in classifiers)
{
suggestions.AddRange(classifier.GetSuggestions(userId, numSuggestionsEach));
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
return suggestions.Take(numSuggestions).ToList();
}
Optimization
With the framework in place, we can now start to fine tune some of the settings. Since we are implicitly assigning ratings to articles based on viewing history, we should take some time to figure out what contributes most to a user's rating.
The data contains 4 distinct actions: UpVote, DownVote, View, and Download. Each user can perform any number of these actions on a single article, so we need to find a way to condense that history into a single rating. For this we will define a simple linear regression that multiplies each action by a weight.
public double GetRating(List<UserAction> actions)
{
int up = actions.Count(x => x.Action == "UpVote");
int down = actions.Count(x => x.Action == "DownVote");
int view = actions.Count(x => x.Action == "View");
int dl = actions.Count(x => x.Action == "Download");
double rating = up * upVoteWeight + down * downVoteWeight +
view * viewWeight + dl * downloadWeight;
return Math.Min(maxWeight, Math.Max(minWeight, rating));
}
All we need to do now is find the weights that result in the most accurate recommender. To be honest, I had great plans for optimizing this equation with a genetic algorithm, but in the end I got lazy and just brute forced all the parameters using an Amazon AWS machine with 36 vCPUs.
Parallel.ForEach(options, set =>
{
var rate = new LinearRater(set.down, set.up, set.view, set.dl);
var mfr = new MatrixFactorizationRecommender(set.features, rate);
mfr.Train(sp.TrainingDB);
var score = mfr.Score(sp.TestingDB, rate);
var results = mfr.Test(sp.TestingDB, 100);
using (StreamWriter w = new StreamWriter("rater-weights.csv", true))
{
w.WriteLine(set.down + "," + set.up + "," + set.view + "," +
set.dl + "," + set.features + "," + score.RootMeanSquareDifference + "," +
results.UsersSolved + "," + results.TotalUsers);
}
});
After this process completes, we see that our best performing weights look like this.
downVote upVote view download
-4 2 3 1
It makes sense that we would subtract points for downvoting and add points for upvoting, viewing, and downloading. These were discovered when the range for ratings was set to [0.1, 5.0], so you can get the maximum possible rating with just one view and one upvote.
Usage
Using the recommendation system is straightforward. We need to create an IRater to calculate implicit ratings from user actions using our previously discovered weights. Then we need to pick an IComparer algorithm to compare users with each other. And finally we can pick our preferred IRecommender recommendation engine.
IRater rate = new LinearRater(-4, 2, 3, 1);
IComparer compare = new CorrelationUserComparer();
IRecommender recommender = new UserCollaborativeFilterRecommender(compare, rate, 50);
Then we can load our training data, train, and optionally save our trained model.
UserBehaviorDatabaseParser parser = new UserBehaviorDatabaseParser();
UserBehaviorDatabase db = parser.LoadUserBehaviorDatabase("UserBehavior.txt");
recommender.Train(db);
recommender.Save(savedModel);
And finally we can get some recommendations.
List<Suggestion> suggestions = recommender.GetSuggestions(userId, ratingsToGet);
If you run the included example project, all of this is done for you.
Results
My overall results we not spectacular. In fact, they were borderline abysmal.
There are two common ways to measure the success of a recommendation system. One is precision, and the other is recall. I also included the percentage of users who were recommended at least one article that they ended up reading.
Precision is the perentage of our suggestions that are relevant (i.e., that the user will end up reading). Basically, if we asked for 10 recommendations and only 3 of them were correct, then we would have a precision score of 30%. Note that a correct recommendation is defined as any suggested article that also happens to be in the testing data set.
Recall is the percentage of correct solutions that we were able to recommend. For instance, if the test data contained 10 articles that user 2 will end up reading but we only found 4 of them, then our recall score would be 40%.
Here are the raw results when getting 30 suggestions at a time.
model precision recall users
UCF 0.29% 1.88% 8.60%
ICF 0.26% 1.70% 7.03%
SVD 0.13% 0.92% 3.90%
HR 0.22% 1.55% 6.36%
The best performing model was able to correctly recommend at least one relevant article 8.6% of the time.
Summary
We learned how to use collaborative filtering and matrix factorization to suggest articles to users and predict ratings. Additionally, we figured out how to derive ratings from individual user actions and utilize article tag data to improve our ratings.
Going into this project, I admittedly knew very little about recommendation systems. Forcing myself to understand a topic well enough to explain it to others turned out to be extremely rewarding.
Thanks for your time!
History
- 3/3/18 - Initial release
- 3/17/18 - Fixed formatting
- 3/22/18 - Fixed sorting bug

