A prototype that explores how data can be associated with its context, a requirement for contextual computing which ...is now expected to grow 30 percent annually and reach a market size of a whopping $125 billion by 2023, largely due to widespread use in consumer mobile devices and smart agents.
The full quote from ZDNet: http://www.zdnet.com/article/the-enterprise-technologies-to-watch-in-2017/
Contextual computing. The increasing desire to augment productivity and collaboration by supplying information on-demand, usually just as it's needed and before it's explicitly asked for, has already become big business. Established industry players such as Apple, Intel, and Nokia are working on and/or offering context-aware APIs already, while a raft of startups is competing to make the early market. Contextual computing is now expected to grow 30 percent annually and reach a market size of a whopping $125 billion by 2023, largely due to widespread use in consumer mobile devices and smart agents.
tl;dr
Object oriented programming and relational databases create a certain mental model regarding how we think about data and its context--they both are oriented around the idea that context has data. In OOP, a class has fields, thus we think of the class as the context for the data. In an RDBMS, a table has columns and again our thinking is oriented to the idea that the table is the context for the data, the columns. Whether working with fields or record columns, these entities get reduced to native types -- strings, integers, date-time structures, etc. At that point, the data has lost all concept as to what context it belongs! Furthermore, thinking about context having data, while technically accurate, can actually be quite the opposite of how we, as human beings, think about data. To us, data is pretty much meaningless without some context in which to understand the data. Strangely, we've ignored that important point when creating programming languages and databases -- instead, classes and tables, though they might be named for some context, are really nothing more than containers.
Contextual data restores the data's knowledge of its own context by preserving the information that defines the context. This creates a bidirectional relationship between context and data. The context knows what data it contains and the data knows to what context it belongs. In this article, I explore one approach to creating this bidirectional relationship -- a declarative strongly typed relational contextual system using C#. Various points of interest such as data types and context relationships ("has a", "is a", "related to") are explored. Issues with such a system, such as referencing sub-contexts in different physical root-level contexts, are also discussed.
Contents
This is a concept piece that resulted from another article that I'm still writing on context and meaning. The fundamental idea is to preserve the context to which data is associated. In this article, I'll describe an approach that is highly declarative and demonstrates creating, managing, and searching contextual data. The goal here is to investigate how to work with contextual data and to look at some of the pros and cons of this concept. To my surprise, my small research efforts into finding implementations for working with contextual data yielded essentially nothing except for some articles indicating how important context is when analyzing data and working with "big data." What I did find (see Further Reading at the end) indicates that this field is very much still in an academic realm.
A brief but worthwhile video (even if it is rather abstract): https://www.youtube.com/watch?v=A68qFLmkA24
A really fun video to watch: https://www.youtube.com/watch?v=rWDIkfpbTmQ
In the discussion that follows, each example is implemented in its own namespace and can be rendered through the indicatedURL, for example: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example8.EmployeeContext. These are, of course, localhost URLs, so you'll have to build run the application in order to play around with the examples. You can find the examples in the "Examples" folder (isn't that amazing.) Each example, in order to provide isolation from the other examples, is in its own namespace. Because context values are associated with the class types qualified by their namespace, values that you enter in one example are not available in another example!
The code base utilizes my own web server architecture based on semantic publisher/subscriber, which you can read in my series of articles, The Clifton Method. Unfortunately, that series of articles does not discuss the actual web server implementation, which is essentially a set of micro-services again implemented with the semantic publisher/subscriber. Because I'm leveraging a lot of my core library, the source code is not included here, only the DLLs. You can obtain my core library yourself though from https://github.com/cliftonm/clifton.
The source code for this article can also be found on GitHub at https://github.com/cliftonm/ContextualComputing.
Since the demo implements a mini-server, you'll probably need to start Visual Studio with "Run as administrator."
Also, from the home page of the demo, you can link directly to the examples discussed in this article as well as view the context-value dictionary:

We start with some Google search results:
Contextual data is used to provide more information and context about pieces of data in order to better analyze them.1
Big Data has limited value if not paired with its younger and more intelligent sibling, Context. When looking at unstructured data, for instance, we may encounter the number �31� and have no idea what that number means, whether it is the number of days in the month, the amount of dollars a stock increased over the past week, or the number of items sold today. Naked number �31� could mean anything, without the layers of context that explain who stated the data, what type of data is it, when and where it was stated, what else was going on in the world when this data was stated, and so forth. Clearly, data and knowledge are not the same thing.2
The above example is interesting because it points out that the value "31" has no context. I want to take this a step further and state that, in many cases, the container (whether a native type or a class) also has no context. This, to me, is an important consideration for the simple fact that if the container has no context, how can the value held by the container have any context? Granted, with languages that support reflection, the context can possibly be gleaned by inspecting the type system, but with this approach, the context is at the mercy of the object model rather than an explicitly declared contextual type system.
When we talk about contextual data, we're really dealing with three distinct concepts: "value", "the value's container", and "container's context."
Here is an example where the container and the value in the container has absolutely no context:
string foo;
Here is an example of two containers that have an implied context because they are wrapped by an outer container:
class PersonName
{
public string FirstName {get; set;}
public string LastName {get; set;}
}
This is "weak" context because when we do this:
Person person = new Person() {FirstName="Marc", LastName="Clifton"};
string firstName = person.FirstName;
the assignment of the "container" firstName completely loses the context in which it exists -- that it is part of a PersonName.
If we want to preserve the context in the above example, we could create a Domain Specific Language (DSL) to express declaratively the above class model. Because the DSL is expressed in C# syntax, one implementation would look like this:
class FirstName : IValueEntity { }
class LastName : IValueEntity { }
public class PersonNameContext : Context
{
public PersonNameContext()
{
Declare<FirstName>().OneAndOnlyOne();
Declare<LastName>().OneAndOnlyOne();
}
}
Notice a few things:
- The fields for first and last name are declared as empty classes to establish a strongly named type. The actual underlying data type is not even provided!
- We use an empty interface
IValueEntity to express the idea that the type is a value type. - The concrete context
PersonName is derived from a common Context class. We do this so that the constructor can call the Declare method in the Context base class. - We can also specify the cardinality of an entity within a context. Here, first and last name can only occur once. Other cardinalities include:
OneOrMoreZeroOrOneZeroOrMoreExactlyMinMax
- Because the DSL does not use Attribute metadata, the declaration must be instantiated in order to be parsed. There are pros and cons to this approach. It isn't a true syntax but is also doesn't require the use of reflection to build the context-graph. Instead, concrete contexts are instantiated that maintain their own context-graph. This (perhaps) helps to simplify the parser implementation. The point here is not to get overly hung up on implementation but just look at this as one possible approach.
Parsing a context involves taking contexts and their fields and grouping them into logic groups. I'll explain this more later, but for now, let's look at the resulting output of the parser:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example1.PersonNameContext
Here the parser determines that there is a single context group "PersonName" that does not have any relationships to other context (more on that shortly.) The group has the fields "FirstName" and "LastName".
We also know enough about the context that we can render it in a browser:
We can even add a title to the edit box that lets us view the context of the field:
This is a useful way of visually inspecting complicated contexts.
The context HTML is created programmatically and I put together a prototype implementation. There are a lot of options when auto-rendering contexts that in the following code are not explored. Regardless, the code provides an early peek at what the parser is doing, how the contexts, fields, and cardinality is managed, and how HTML class and id attributes are created, as well as custom attributes, for persisting value changes. There are also many extension methods tacked on to StringBuilder to facilitate a fluent style for creating the HTML. This is pure Javascript -- no jQuery, Bootstrap, or MVVM framenwork is used. Some comments are off topic but may be amusing.
protected string CreatePage(Parser parser)
{
StringBuilder sb = new StringBuilder();
sb.StartHtml();
sb.StartHead().Script("/js/wireUpValueChangeNotifier.js").EndHead();
sb.StartBody();
foreach(var group in parser.Groups)
{
if (group.ContextPath.Count() == 0)
{
sb.StartDiv();
}
else
{
sb.StartInlineDiv();
}
if (group.Relationship.GetType() != typeof(NullRelationship))
{
if (group.Relationship.Maximum < 5)
{
for (int i = 0; i<group.Relationship.Maximum; i++)
{
sb.StartDiv();
CreateFieldset(sb, group, i);
sb.EndDiv();
}
}
else
{
CreateFieldset(sb, group);
}
}
else
{
CreateFieldset(sb, group);
}
sb.EndDiv();
sb.Append("\r\n");
}
sb.StartScript().Javascript("(function() {wireUpValueChangeNotifier();})();").EndScript();
sb.EndBody().EndHtml();
return sb.ToString();
}
protected void CreateFieldset(StringBuilder sb, Group group, int recNum = 0)
{
sb.StartFieldSet().Legend(group.Name);
sb.StartTable();
foreach (var field in group.Fields)
{
field.CreateInstance();
sb.StartRow();
sb.StartColumn().
AppendLabel(field.Label + ":").
NextColumn().
AppendTextInput().
Class("contextualValue").
ID(String.Join(".", field.ContextPath.Select(p => p.InstanceId))).
CustomAttribute("contextPath", String.Join("|",
field.ContextPath.Select(p=>p.Type.AssemblyQualifiedName))).
CustomAttribute("recordNumber", recNum.ToString()).
CustomAttribute("title", String.Join("
",
field.ContextPath.Select(p => p.Type.Name))).
field.ContextPath.Select(p => p.InstanceId))).
EndColumn();
sb.EndRow();
}
sb.EndTable();
sb.EndFieldSet();
sb.Append("\r\n");
}
The supporting JavaScript POST's any change to the field value when the field loses focus:
function wireUpValueChangeNotifier() {
var docInputs = document.getElementsByClassName("contextualValue");
for (var i = 0; i < docInputs.length; i++) {
var id = docInputs[i].id;
(function closure(id) {
var docInput = document.getElementById(id);
docInput.onchange = function () {
updateField(id);
};
})(id);
}
}
function updateField(id) {
var docInput = document.getElementById(id);
var val = docInput.value;
var contextPath = docInput.getAttribute("contextPath");
var recordNumber = docInput.getAttribute("recordNumber");
console.log(val + " " + contextPath + "[" + recordNumber + "]");
post("/updateField",
{value: val, id: id, typePath : contextPath, recordNumber : recordNumber})
}
function post(url, data) {
return fetch(url, { method: "POST", body: JSON.stringify(data) });
}
Like object oriented programming (OOP), contexts can have containment relationships (the "has a" example above) and abstractions. Unlike some OOP languages like C#, multiple abstractions (as in, multiple inheritance) can be supported. Furthermore, context can have one-to-many and many-to-many relationships for which OOP does not provide a native syntactical expression but which we can easily express with our declarative DSL.
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example2.PersonContext
One of the fundamental concept of contexts is that they are hierarchical -- a context can contain a context. For example, a "Person" context contains (has a) "PersonName" context:
public class PersonContext : Context
{
public PersonContext()
{
Declare<PersonNameContext>().OneAndOnlyOne();
}
}
Notice how the context graph changes:
Previous:
Now:
Notice also that the rendering of the "Person" context doesn't visually look much different. However, the context graph for the fields now consists of three levels:
- Root context (
PersonContext) - Sub-context (
PersonNameContext) - The field context (
FirstName and LastName)
Abstractions are a slippery slope -- too often an abstraction is used as a convenient way to create common properties and behaviors between a set of sub-classes. These "logic" abstractions, created for the convenience of the programmer, are quite useful in OOP. However, contextual abstraction needs to be much more "pure" - it must represent an actual meaningful abstraction, not just a convenient abstraction. An OOP abstraction is too loosey-goosey: the sub-class can choose what properties and methods are of value, what methods get overridden, even what methods are no longer appropriate and if called result in an exception! A contextual abstraction must be very carefully thought out. First, we must realize that contextual abstraction results in the inheriting of attributes (or qualities) of the context, not behaviors.
Until robots become employees, we can say that an employee inherits all the attributes of a person -- an employee is a kind of person. We can express this in our DSL like this:
class EmployeeContext : Context
{
public EmployeeContext()
{
AddAbstraction<EmployeeContext, PersonContext>("Employee Name");
}
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example3.EmployeeContext
Notice how this rendered:
Let's add an employee ID to the parent context so we can explore this a bit further:
class EmployeeId : IValueEntity { }
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
AddAbstraction<EmployeeContext, PersonContext>("Employee Name");
}
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example4.EmployeeContext
Here's what the parser is doing:
It's creating two groupings, one for the root context "EmployeeContext" and one for the abstraction "PersonContext." There are times when we want this behavior (particularly if the abstractions have the same fields) and times when we would rather coalesce the abstraction into the group of fields in the sub-class. We can specify the coalescing like this:
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
AddAbstraction<EmployeeContext, PersonContext>("Employee Name").Coalesce();
}
}
Note the additional method call Coalesce.
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example5.EmployeeContext
The result is now more what we probably want:
What's important to note here is that the contextual path is still the same, regardless of the fact that the abstraction has been coalesced into the same group:
Behind the scenes, the way an abstraction is drilled into is changed slightly when an abstraction is coalesced:
protected void DrillIntoAbstraction(Stack<ContextPath> contextPath,
IContext context, Group group, AbstractionDeclaration abstraction)
{
LogEntityType(abstraction.SuperType);
LogRelationship(abstraction.SubType, abstraction.SuperType);
if (abstraction.SuperType.HasBaseClass<Context>())
{
Log?.Invoke("Abstraction: Drilling into " + abstraction.SuperType.Name);
IContext superContext = (IContext)Activator.CreateInstance(abstraction.SuperType);
var rootEntities = superContext.RootEntities;
if (rootEntities.Count() > 0)
{
Group group2 = group;
if (!abstraction.ShouldCoalesceAbstraction)
{
group2 = CreateGroup(abstraction.SuperType,
RelationshipDeclaration.NullRelationship, contextPath, abstraction.Label);
groups.Add(group2);
}
foreach (var root in rootEntities)
{
contextPath.Push(new ContextPath
(ContextPath.ContextPathType.Abstraction, abstraction.SuperType));
CreateFields(contextPath, superContext, group2);
PopulateGroupFields(contextPath, superContext, group2, root);
contextPath.Pop();
}
}
}
}
Abstraction is generic relationship that minimally conveys the meaning that the sub-context is a more specialized version of the super-context. Sometimes, we want an explicit relationship between two contexts. In this example, the relationship between the "Employee" context and the "Person" context is declared as an explicit relationship rather than an abstraction:
class PersonNameRelationship : IRelationship { }
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
Declare<PersonNameRelationship, EmployeeContext,
PersonContext>("Person Name").Exactly(1).Coalesce();
}
}
Notice the declaration of a type that implements IRelationship. There is no content, this is just a type declaration (this would be more natural in a Functional Programming language.)
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example6.EmployeeContext
Physically, the result is the same:
Notice however how the context path has changed:
Before:
Now:
Taking the "Employee" example above, let's instead create a relationship with an "emergency contact", requiring that at least one but at most two emergency contacts are provided:
class EmergencyContactRelationship : IRelationship { }
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
AddAbstraction<EmployeeContext, PersonContext>("Employee Name").Coalesce();
Declare<EmergencyContactRelationship, EmployeeContext, PersonContext>
("Emergency Contact").Min(1).Max(2);
}
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example7.EmployeeContext
Notice here that we are declaring a relationship of type EmergencyContactRelationship between the EmployeeContext and a PersonContext. We're not explicitly creating an "EmergencyContextPerson" container -- it is "understood" that these people are emergency contacts because of the contextual relationship. When rendered (let's have a little fun with denoting required fields):
Notice when we hover over the Last Name field, we see that the field value is associated with an emergency contact via the relationship. Alternatively, you could do this:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example8.EmployeeContext
class EmergencyContactContext : Context
{
public EmergencyContactContext()
{
AddAbstraction<EmergencyContactContext, PersonContext>("Contact Name").Coalesce();
}
}
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
AddAbstraction<EmployeeContext, PersonContext>("Employee Name").Coalesce();
Declare<EmergencyContactRelationship, EmployeeContext,
EmergencyContactContext>("Emergency Contact").Min(1).Max(2);
}
}
Note how we now have a concrete context for the emergency contact. Visually, the fields are rendered the same, except we now have an additional path entry in the context:
Each context manages its own abstractions and relationships. Even if a context does not itself declare an abstraction or a relationship, the containing (super-) context can do so. In this example, the EmergencyContactContext has been renamed to EmergencyContact because it is no longer a context and it is declared as a simple entity rather than a context. The containing EmployeeContext declares the abstraction on the entity:
class EmergencyContact : IEntity { }
class EmployeeContext : Context
{
public EmployeeContext()
{
Declare<EmployeeId>().OneAndOnlyOne();
Declare<EmergencyContactRelationship,
EmployeeContext, EmergencyContact>("Emergency Contact").Min(1).Max(2);
AddAbstraction<EmployeeContext, PersonContext>("Employee Name").Coalesce();
AddAbstraction<EmergencyContact, PersonContext>("Contact Name").Coalesce();
}
}
While the resulting rendering looks identical to the user, the contextual path is similar to the first example:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example9.EmployeeContext
What's important here is that by itself, EmergencyContext does not declare any abstractions or relationships -- the super-context EmployeeContext adds additional contexts to the entity (which can also be another context.) Therefore, while you can extend a sub-context in the declaration of a super-context, one should only do this if there is additional contextual meaning required by the super-context. Otherwise, the sub-context should have declared the relationship/abstraction. So, this illustrates what you should not do.
We can chain contexts in a relationship together with Or and And fluent methods. These operators are applied to the left operand, meaning that:
a or b or c and d and e
evaluates as:
(a or b) or (a or c) and (a and d and e)
which might be better expressed as:
- a, d and e are required.
- b and c are optional and non-exclusive.
OK, shoot me now for coming up with this crazy scheme. It is definitely something ripe for refactoring to have a proper expression evaluation implemented, but this suits my purposes now for a prototype.
For example, the life insurance policy that the employer carries for the employee might list a person or a non-profit business or both as beneficiaries:
Declare<Beneficiary, EmployeeContext, PersonContext>("Beneficiary").Or<BusinessContext>();
These declarations:
class BusinessName : IValueEntity { }
public class BusinessContext : Context
{
public BusinessContext()
{
Declare<BusinessName>().OneAndOnlyOne();
}
}
public class EmployeeContractContext : Context
{
public EmployeeContractContext()
{
Label = "Employee Contract";
Declare<EmployeeContext>("Employee").OneAndOnlyOne();
Declare<EmergencyContactRelationship,
EmployeeContext, PersonContext>("Emergency Contact").Min(1).Max(2);
Declare<Beneficiary, EmployeeContext, PersonContext>("Beneficiary").Or<BusinessContext>();
}
}
renders like this:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example10.EmployeeContractContext
The relationships (including the abstractions) can be validated. For example, this context declares abstractions for entities that are not part of its context:
public class EmployeeContractContext : Context
{
public EmployeeContractContext()
{
Label = "Employee Contract";
Declare<EmployeeContext>("Employee").OneAndOnlyOne();
AddAbstraction<Spouse, PersonContext>("Spouse Name");
AddAbstraction<Child, PersonContext>("Child Name");
}
}
Here, the context declares abstractions (PersonContext) for two contexts, Spouse and Child, that are never declared as entities or relationships to the EmployeeContractContext. The browser displays this error:
Note to the reader -- this section becomes a bit more interactive as I show the code changes that I am making to support the additional behaviors.
One of the features of contextual data is that the context is easily extended, particularly at runtime, without breaking existing behaviors. Adding a relationship or abstraction to your version of a context doesn't break how another person is using the context. Because of the dynamic nature of a contexts, a relational database is not appropriate as the schema would have to be constantly modified. Granted, a relational database can be used as a "meta-base" for contextual data, but certainly concrete context structure cannot be encoded into a relational database's schema. A NoSQL database may be more appropriate as it is usually schema-less. Ultimately though, contextual data is actually very flat. While it is useful to represent a context as a hierarchy, the actual context data is essentially a flat key-value pair relationship:
unique context path : value
A "unique context path" is determined by assigning a GUID to each entity in the path. The tree structure is formed when entities (sub-contexts and field-level entities) are duplicated according to the cardinality of the entity, where each branch gets a unique ID.
The key-value pair is managed by the ContextValue class:
public class ContextValue
{
public Guid InstanceId { get; protected set; }
public string Value { get; protected set; }
public int RecordNumber { get; protected set; }
public IReadOnlyList<Guid> InstancePath { get { return instancePath; } }
public IReadOnlyList<Type> TypePath { get { return typePath; } }
protected List<Guid> instancePath = new List<Guid>();
protected List<Type> typePath = new List<Type>();
public ContextValue(string value, List<Guid> instancePath,
List<Type> typePath, int recordNumber = 0)
{
InstanceId = instancePath.Last();
Value = value;
RecordNumber = recordNumber;
this.instancePath = instancePath;
this.typePath = typePath;
}
}
Notice that we're keeping track of the "record number." For contexts with cardinality > 1 with multiple child entities, we need the record number to ensure that sub-entities maintain their cohesion in the context path.
A ContextValue can be created either directly from the parser (from a unit test):
var cvFirstName = searchParser.CreateValue<PersonNameContext, FirstName>("Marc");
var cvLastName = searchParser.CreateValue<PersonNameContext, LastName>("Clifton");
or created and persisted in the ContextValueDictionary (also from a unit test):
ContextValueDictionary cvd = new ContextValueDictionary();
cvd.CreateValue<EmployeeName, PersonNameContext, FirstName>(parser1, "Marc");
cvd.CreateValue<EmployeeName, PersonNameContext, LastName>(parser1, "Clifton");
When persisted in the dictionary, the context tree is walked by instance ID and missing branches are added as we go:
public void AddOrUpdate(ContextValue cv)
{
Assert.That(cv.TypePath.Count == cv.InstancePath.Count,
"type path and instance path should have the same number of entries.");
ContextNode node = tree;
for (int i = 0; i < cv.TypePath.Count; i++)
{
var (id, type) = (cv.InstancePath[i], cv.TypePath[i]);
if (node.TryGetValue(id, out ContextNode childNode))
{
node = childNode;
}
else
{
childNode = new ContextNode(id, type);
node.AddChild(childNode);
node = childNode;
if (!flatView.TryGetValue(type, out List<ContextNode> nodes))
{
flatView[type] = new List<ContextNode>();
}
flatView[type].Add(childNode);
}
}
node.ContextValue = cv;
}
For each node that is created, an entry mapping the entity type to the node is created (this is a one-to-many relationship) which is used to quickly identify the all the nodes that implement a particular entity type. This helps to optimize searching -- rather than walking the entire tree to find all matching entity types at different levels of the tree, a quick lookup of the entity type gives us all the nodes in the tree for that type. We'll see this used later on in searches.
The unit test code fragments above demonstrate how to persist a value in a particular context using a known path. Let's look at the more interesting example of persisting values in a contextual instance as entered from the browser. If we inspect the input boxes in a simple context:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example5.EmployeeContext
we see that there are some attributes that are provided when the HTML is created -- here's the one for the EmployeeID input box:
<input type="text" class='contextualValue'
id='acec08ef-0bd3-47de-8bc6-c2281fa291ee.
490895ca-c62e-4654-9d3e-41efe482e437'
contextPath='MeaningExplorer.EmployeeContext, MeaningExplorer,
Version=1.0.0.0, Culture=neutral, PublicKeyToken=null|
MeaningExplorer.EmployeeId, MeaningExplorer,
Version=1.0.0.0, Culture=neutral, PublicKeyToken=null'
recordNumber='0'
title='EmployeeContext
EmployeeId'>
Notice the dot "." character that separates the GUID's and the pipe "|" character that separates the context path types.
When a value is entered, the input element's onchange triggers a POST that is routed to (refer to The Clifton Method, Part IV for a discussion on semantic processing, membranes, etc.):
public void Process(ISemanticProcessor proc, IMembrane membrane, UpdateField msg)
{
ContextValueDictionary cvd = CreateOrGetContextValueDictionary(proc, msg.Context);
var instancePath = msg.ID.Split(".").Select(Guid.Parse).ToList();
var typePath = msg.TypePath.Split("|").ToList();
var cv = new ContextValue(msg.Value, instancePath, typePath.Select
(t=>Type.GetType(t)).ToList(), msg.RecordNumber);
cvd.AddOrUpdate(cv);
JsonResponse(proc, msg, new OKResponse());
}
We'll modify the post-back to perform a GET that returns the HTML for rendering the dictionary as a tree and the flat "entity type : context node list" collection:
function updateField(id) {
var docInput = document.getElementById(id);
var val = docInput.value;
var contextPath = docInput.getAttribute("contextPath");
var recordNumber = docInput.getAttribute("recordNumber");
console.log(val + " " + contextPath + "[" + recordNumber + "]");
post("/updateField", { value: val, id: id, typePath: contextPath,
recordNumber: recordNumber }, getDictionaryHtml);
}
function getDictionaryHtml() {
get("/dictionaryTreeHtml", onDictionaryTreeHtml);
get("/dictionaryNodesHtml", onDictionaryNodesHtml);
}
function onDictionaryTreeHtml(json) {
updateHtml("dictionary", json.html);
}
function onDictionaryNodesHtml(json) {
updateHtml("nodes", json.html);
}
function updateHtml(tag, b64html) {
var html = atob(b64html);
var el = document.getElementById(tag);
el.innerHTML = html;
}
function get(url, callback) {
return fetch(url, { method: "GET" }).then(function (response) {
return response.json();
}).then(function (jsonData) {
callback(jsonData);
});
}
function post(url, data, callback) {
return fetch(url, { method: "POST",
body: JSON.stringify(data) }).then(function (response) {
return response.json();
}).then(function (jsonData) {
callback(jsonData);
});
}
If you're curious, I added the following to the page rendering logic:
sb.StartParagraph().Append("<b>Dictionary:</b>").EndParagraph();
sb.StartParagraph().StartDiv().ID("dictionary").EndDiv().EndParagraph();
sb.StartParagraph().Append("<b>Type Nodes:</b>").EndParagraph();
sb.StartParagraph().StartDiv().ID("nodes").EndDiv().EndParagraph();
Now let's see what happens when we fill in the form with some data. First, I'll add an ID:
Then my first name:
And finally my last name:
If I change a value for this context, we see that the existing context value is updated:
All this rendering (very basic it is) is created by two route handlers and some helper methods:
public void Process(ISemanticProcessor proc, IMembrane membrane, GetDictionaryTreeHtml msg)
{
ContextValueDictionary cvd = CreateOrGetContextValueDictionary(proc, msg.Context);
StringBuilder sb = new StringBuilder();
NavigateChildren(sb, cvd.Root.Children, 0);
JsonResponse(proc, msg, new { Status = "OK", html = sb.ToString().ToBase64String() });
}
public void Process(ISemanticProcessor proc, IMembrane membrane, GetDictionaryNodesHtml msg)
{
ContextValueDictionary cvd = CreateOrGetContextValueDictionary(proc, msg.Context);
StringBuilder sb = new StringBuilder();
foreach (var kvp in cvd.FlatView)
{
sb.Append(kvp.Key.Name + " : <br>");
foreach (var node in kvp.Value)
{
sb.Append("  ");
RenderNodeValue(sb, node);
sb.Append("<br>");
}
}
JsonResponse(proc, msg, new { Status = "OK", html = sb.ToString().ToBase64String() });
}
protected void NavigateChildren(StringBuilder sb, IReadOnlyList<ContextNode> nodes, int level)
{
foreach (var node in nodes)
{
sb.Append(String.Concat(Enumerable.Repeat(" ", level * 2)));
RenderNodeType(sb, node);
RenderNodeValue(sb, node);
sb.Append("<br>");
NavigateChildren(sb, node.Children, level + 1);
}
}
protected void RenderNodeType(StringBuilder sb, ContextNode node)
{
sb.Append(node.Type.Name);
}
protected void RenderNodeValue(StringBuilder sb, ContextNode node)
{
if (node.ContextValue != null)
{
sb.Append(" = " + node.ContextValue.Value);
}
}
It would be useful to add a "New" button to create a new context. We'll render it before the dictionary output:
sb.StartButton().ID("newContext").Class("margintop10").Append("New Context").EndButton();
The interesting (or strange) thing about this is that we don't need to tell the server we've created a new context. Instead, the JavaScript can handle clearing the input text boxes and assigning new GUIDs to the instance paths. As a side note, this does not trigger the onchange event (really bad name for that event) because onchange is triggered only when the user tabs off the control. A minor change is that I needed to add a separate "context value ID" attribute cvid to keep the element ID separate from the context value ID so that the event handler uses the latest context value ID. This required a change in the server-side rendering:
CustomAttribute("cvid", String.Join(".", field.ContextPath.Select(p => p.InstanceId))).
and a tweak to the updateField JavaScript function:
function updateField(id) {
var docInput = document.getElementById(id);
var val = docInput.value;
var contextPath = docInput.getAttribute("contextPath");
var recordNumber = docInput.getAttribute("recordNumber");
var cvid = docInput.getAttribute("cvid");
console.log(val + " " + contextPath + "[" + recordNumber + "]");
post("/updateField", { value: val, id: cvid,
typePath: contextPath, recordNumber: recordNumber }, getDictionaryHtml);
}
There's an added complexity to this. Any common base context path such as the PersonContext which contains value entities for FirstName and LastName needs to have the same base ID. If we don't do this, each value entity within a sub-context gets an entirely new context path which results in multiple root-level contexts being created. This is not what we want. To solve this, we need to get a collection of all the unique ID's, map them to replacement ID's, and update each ID in the path according to their original value with the new mapped GUID. It sounds more complicated than it actually is. I sure miss C#'s LINQ in these cases.
Here's the JavaScript that handles the field clearing and new context value ID assignments:
function wireUpEvents() {
document.getElementById("newContext").onclick = function () { newContext(); };
}
function newContext() {
clearInputs();
createNewGuids();
}
function clearInputs() {
forEachContextualValue(function (id) { document.getElementById(id).value = ""; });
}
function createNewGuids() {
var uniqueIds = getUniqueIds();
var idMap = mapToNewIds(uniqueIds);
assignNewIds(idMap);
}
function getUniqueIds() {
var uniqueIds = [];
forEachContextualValue(function (id) {
var ids = id.split(".");
for (var i = 0; i < ids.length; i++) {
var id = ids[i];
if (!uniqueIds.includes(id)) {
uniqueIds.push(id);
}
}
});
return uniqueIds;
}
function mapToNewIds(uniqueIds) {
var idMap = {};
for (var i = 0; i < uniqueIds.length; i++) {
idMap[uniqueIds[i]] = uuidv4();
}
return idMap;
}
function assignNewIds(idMap) {
forEachContextualValue(function (id) {
var oldIds = id.split(".");
var newIds=[];
for (var i = 0; i < oldIds.length; i++) {
newIds.push(idMap[oldIds[i]]);
}
newId = newIds.join(".");
document.getElementById(id).setAttribute("cvid", newId);
});
}
Now we let's create a couple contexts for two different "employees" (0001/Marc/Clifton and 0002/Ian/Clifton). When done, this is what the context value dictionary and flattened type node collections look like:
Here, we see that we have two root level EmployeeContext instances and the context value types have different instances for the different contexts.
Now here's the fun part and where working with contextual data really shines: searching! A profound difference in searching is the search result provides the context for the results. This means that you are effectively searching the entire database for a particular contextual pattern whose values match a given instance. The result are the different contexts in which the specific sub-context data values match. The reason this is so nifty is that you can perform a search within a sub-context and get the matches across all contexts, even contexts of different root types. To illustrate this, I'm going to declare an AddressBookContext that we'll use with the existing EmployeeContext to show how a search of a person's name finds the context instances in both EmployeeContext and AddressBookContext. Along the way, we'll also add the ability to display an existing context's values so that we can see the search results.
We can use these two URLs for testing:
The address book context re-uses the PersonContext. I also added a very simple ContactContext that can be extended to be more functional later on, but for now, the AddressBookContext is declared like this:
class PhoneNumber : IValueEntity { }
class EmailAddress : IValueEntity { }
public class PhoneContext : Context
{
public PhoneContext()
{
Declare<PhoneNumber>("Phone");
}
}
public class EmailContext : Context
{
public EmailContext()
{
Declare<EmailAddress>("Email");
}
}
public class ContactContext : Context
{
public ContactContext()
{
Declare<PhoneContext>();
Declare<EmailContext>();
}
}
public class AddressBookContext : Context
{
public AddressBookContext()
{
Label = "Address Book";
Declare<PersonContext>();
Declare<ContactContext>();
}
}
This renders as:
We've been using a route for rendering contexts, let's look briefly at the route handler:
public void Process(ISemanticProcessor proc, IMembrane membrane, RenderContext msg)
{
try
{
Type t = Type.GetType(msg.ContextName);
Clifton.Meaning.IContext context = (Clifton.Meaning.IContext)Activator.CreateInstance(t);
Parser parser = new Parser();
parser.Log = logMsg => Console.WriteLine(logMsg);
parser.Parse(context);
string html;
if (parser.AreDeclarationsValid)
{
ShowGroups(parser.Groups);
html = Renderer.CreatePage(parser, msg.IsSearch ?
Renderer.Mode.Search : Renderer.Mode.NewRecord);
}
else
{
html = "<p>Context declarations are not valid. Missing entities:</p>" +
String.Join("<br>", parser.MissingDeclarations.Select(pt => pt.Name));
}
proc.ProcessInstance<WebServerMembrane, HtmlResponse>(r =>
{
r.Context = msg.Context;
r.Html = html;
});
}
catch (Exception ex)
{
proc.ProcessInstance<WebServerMembrane, HtmlResponse>(r =>
{
r.Context = msg.Context;
r.Html = ex.Message + "<br>" + ex.StackTrace.Replace("\r\n", "<br>");
});
}
}
While rudimentary, it works. Here are a couple of examples:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example12.PersonContext
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example12.ContactContext
Notice in these examples we're rendering sub-contexts, which is exactly what we want to do for searches. The only different for searches is that we don't want user inputs to create entries in the context dictionary. For searching, we'll pass in the parameter isSearch=true. When we use this option, notice that the dictionary does not get updated and we have a "Search Context" button instead of a "New Context" button:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example12.PersonContext?&isSearch=true
When the Search button is clicked, this JavaScript executes:
function searchContext() {
var searchList = [];
forEachContextualValue("contextualValueSearch", function (id) {
var docInput = document.getElementById(id);
var val = docInput.value;
if (val != "") {
var contextPath = docInput.getAttribute("contextPath");
var cvid = docInput.getAttribute("cvid");
searchList.push({ value: val, id: cvid, typePath: contextPath });
}
});
if (searchList.length > 0) {
post("/searchContext", { searchFields: searchList }, onShowResults);
}}
}
The data is deserialized into this server-side structure:
public class SearchField
{
public string Value { get; set; }
public string ID { get; set; }
public string TypePath { get; set; }
}
public class SearchContext : SemanticRoute
{
public List<SearchField> SearchFields { get; set; }
}
and processed by this route handler:
public void Process(ISemanticProcessor proc, IMembrane membrane, SearchContext msg)
{
List<ContextValue> cvSearch = new List<ContextValue>();
foreach (var search in msg.SearchFields)
{
var instancePath = search.ID.Split(".").Select(Guid.Parse).ToList();
var typePath = search.TypePath.Split("|").ToList();
var cv = new ContextValue(search.Value, instancePath,
typePath.Select(t => Type.GetType(t)).ToList());
cvSearch.Add(cv);
}
ContextValueDictionary cvd = CreateOrGetContextValueDictionary(proc, msg.Context);
List<ContextNode> matches = cvd.Search(cvSearch);
var results = GetMatchPaths(matches);
var html = Render(results);
JsonResponse(proc, msg, new { Status = "OK", html = html.ToString().ToBase64String() });
}
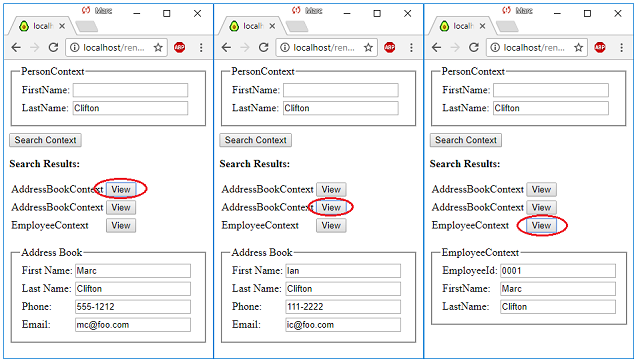
This route hander constructs ContextValue instances from the filled in data and executes the dictionary's Search method. Again, we'll have the server render the actual HTML. To illustrate the search results, I'll create an entry in the employee context and the address book context that have the same name (Marc Clifton) and then search for "Marc". The result, as expected (since I wrote the unit test for this first) is:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example12.AddressBookContext&isSearch=true
We see that both contexts in which the first name matches have been returned. I could have provided "Marc" and "Clifton" for first and last name respectively as well, as the search algorithm matches all fields in the context that contains the fields. As an aside, this implementation is only preliminary and does not handle searches than span contexts. If we look at the context dictionary, you can see what I actually entered in the different contexts:
You would be correct in assuming that if I entered the last name of "Clifton", we should get three search results back, and indeed we do:
The search algorithm identifies the common parent type (as mentioned, this prototype algorithm only handles a single common parent type) and then matches all field values of that context with the search values, returning all context paths that match:
public List<ContextNode> Search(List<ContextValue> contextValuesToSearch)
{
Assert.That(contextValuesToSearch.Count > 0,
"At least one ContextValue instance must be passed in to Search.");
int pathItems = contextValuesToSearch[0].InstancePath.Count;
Assert.That(contextValuesToSearch.All(cv => cv.InstancePath.Count == pathItems),
"Context values must have the same path length for now.");
var parentTypes = contextValuesToSearch.Select(cv => cv.TypePath.Reverse().Skip(1).
Take(1).First()).DistinctBy(cv=>cv.AssemblyQualifiedName);
Assert.That(parentTypes.Count() == 1,
"Expected all context values to have the same field-parent.");
Type parentType = parentTypes.Single();
List<ContextNode> matches = new List<ContextNode>();
if (flatView.TryGetValue(parentType, out List<ContextNode> nodesOfParentType))
{
foreach (var parentNode in nodesOfParentType)
{
bool match = true;
foreach (var cv in contextValuesToSearch)
{
var childMatch = parentNode.Children.SingleOrDefault
(c => c.Type == cv.TypePath.Last());
if (childMatch != null)
{
Assert.That(childMatch.ContextValue != null,
"Expected a ContextValue assigned to the last path entry.");
match = childMatch.ContextValue.Value == cv.Value;
}
if (!match)
{
break;
}
}
if (match)
{
matches.Add(parentNode);
}
}
}
return matches;
}
The search result provides a GUID context instance path to the level of the matching context. Any child contexts are part of the match, as well as any fields in the parent contexts. We'll add a button to each search result to view the resulting full context with a handler that calls a POST method with the search result GUID path:
protected StringBuilder Render(IEnumerable<ContextNodePath> results)
{
StringBuilder sb = new StringBuilder();
sb.StartTable();
foreach (var result in results)
{
sb.StartRow().
StartColumn().
Append(result.Path.First().Type.Name).
EndColumn().
StartColumn().Append("\r\n").
StartButton().
CustomAttribute("onclick", "post(\"/viewContext\",
{instancePath : \"" + String.Join(".", result.Path.Select(p => p.InstanceId)) + "\"},
onShowSelectedSearchItem)").
Append("View").
EndButton().Append("\r\n").
EndColumn().
EndRow();
}
sb.EndTable();
return sb;
}
When we click on the View button, the following route handler gets executed:
public void Process(ISemanticProcessor proc, IMembrane membrane, ViewContext msg)
{
var instancePath = msg.InstancePath.Split(".").Select(s=>Guid.Parse(s)).ToList();
ContextValueDictionary cvd = CreateOrGetContextValueDictionary(proc, msg.Context);
var (parser, context) = cvd.CreateContext(instancePath);
string html = Renderer.CreatePage(parser, Renderer.Mode.View);
JsonResponse(proc, msg, new { Status = "OK", html = html.ToString().ToBase64String() });
}
Here are examples of what the browser looks like clicking on the different View buttons:
This should really drive home how contextual data differs from a relational database. To reiterate, contextual data retains the relationship hierarchy of the data. This allows us to easily display all the contexts in which a sub-context exists and letting the user pick the context they desire. In a traditional relational database, the context is incorporated in the schema, requiring separate queries to find all the contexts for a single sub-context instance. Typically, the user would have to first decide, "I want to look up a name in an address book" or "I want to look up a name in the employee database." Contextual data flips this model around, letting the user pick the contextual frame last. It can be quite useful (or not) to show the user all the contexts in which a subset of the data exists.
Interestingly (at least to me), building the context instance is quite simple, requiring only that the instance IDs of the matching context be set in the logical context path that the parser creates (we will see next that there is a flaw in this approach.) At the moment, this code is prototype but functional, as the todo's point out more work needs to be done:
public (Parser, Context) CreateContext(List<Guid> instancePath)
{
ContextNode dictNode = tree.Children.Single(c => c.InstanceId == instancePath[0]);
Type rootType = dictNode.Type;
Parser parser = new Parser();
var context = (Context)Activator.CreateInstance(rootType);
parser.Parse(context);
foreach (FieldContextPath fieldContextPath in parser.FieldContextPaths.Where
(p => p.Path[0].Type == rootType))
{
ContextNode workingDictNode = dictNode;
fieldContextPath.Field.ContextPath[0].UpdateInstanceId(workingDictNode.InstanceId);
Process(fieldContextPath, 1, workingDictNode);
}
return (parser, context);
}
protected void Process
(FieldContextPath fieldContextPath, int level, ContextNode workingDictNode)
{
foreach (ContextNode childDictNode in workingDictNode.Children)
{
if (childDictNode.Type == fieldContextPath.Field.ContextPath[level].Type)
{
fieldContextPath.Field.ContextPath[level].UpdateInstanceId(childDictNode.InstanceId);
fieldContextPath.Field.ContextValue = childDictNode.ContextValue;
Process(fieldContextPath, level + 1, childDictNode);
}
}
}
This can then be handed to the renderer which sets the field value when rendering for "view" mode:
CustomAttribute("value", mode==Mode.View ? (field.ContextValue?.Value ?? "") : "").
An important point here is that the instance IDs are set to match context instance in the context tree -- this means that we can edit the values and have the appropriate instance update rather than creating a new context instance.
http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example14.ChildContext&isSearch=true
Search for "Elisabeth" and you get the "mother context", because what's actually being searched is the PersonNameContext sub-context of ChildContext. We need to qualify the search by the containing a direct path (upwards) to the context being searched?
All the examples so far are of single row contexts. Realistically, we need to address a context that can handle multi-row data. A simple example of this is a parent-child relationship, declared this way:
public class ParentChildRelationship : IRelationship { }
public class ChildContext : Context
{
public ChildContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
public class ParentContext : Context
{
public ParentContext()
{
Declare<PersonContext>().OneAndOnlyOne();
Declare<ParentChildRelationship, ParentContext, ChildContext>().Max(5).AsGrid();
}
}
Note how I use AsGrid as guidance to the renderer that I want a grid. The Max limit is strictly for demo purposes to prevent creating too large of an input area.
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example13.ParentContext
In the previous section, I mentioned a problem with setting the physical instance IDs in the logical context path. This works for single records just fine, but a more general solution requires that the instance ID for the rendered field must come from the physical context value dictionary. A minor tweak to the rendering algorithm handles this regardless of whether we're working with single record or multi-record contexts, as shown in this code fragment that is part of the renderer:
if (cvd.TryGetContext(field, recNum, out ContextNode cn))
{
instanceIdList = instanceIdList.Take(instanceIdList.Count - 1).ToList();
instanceIdList.Add(cn.InstanceId);
fieldValue = cn.ContextValue.Value;
}
else
{
fieldValue = "";
}
This ensures that the multiple recordsets of the context display their correct values, as demonstrated here after searching for some pre-populated data:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example13.ParentContext&isSearch=true
The flaw, at least in my implementation of contextual relationships, is that each value instance has a unique context. This means that context-values that are intended to be common across contexts are actually disassociated. Let's explore some disassociations.
A good example of a top-down contextual relationship is where we have father and mother contexts that have a relationship to one or more children. We can declare separate father and mother contexts and for simplicity, let's work with a limit of just one child:
public class ParentChildRelationship : IRelationship { }
public class ChildContext : Context
{
public ChildContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
public class FatherContext : Context
{
public FatherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
Declare<ParentChildRelationship, FatherContext, ChildContext>().OneAndOnlyOne();
}
}
public class MotherContext : Context
{
public MotherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
Declare<ParentChildRelationship, MotherContext, ChildContext>().OneAndOnlyOne();
}
}
After creating values in the father/mother contexts for my parents:
I can search on my name with the following result:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example14.PersonContext&isSearch=true
This seems reasonable as we can view the mother and father contexts. This works well even when searching on my last name:
This might be unexpected because the dictionary contains four separate contexts paths for the last name of "Clifton":
When rendering the results, there's a bit of "magic" that occurs -- filtering results by unique root context IDs:
List<ContextNode> matches = cvd.Search(cvSearch).DistinctBy(cn => cn.InstanceId).ToList();
However, the overall problem still exists -- each parent has a separate instance of the child, even though the child is the same child. When we search for "Clifton", the algorithm finds four occurrences:
- father's context (same last name)
- mother's context (same last name)
- father's child context with the same last name
- mother's child context with the same last name
and filters out 3 and 4 because they have the same context root ID as 1 and 2. None-the-less, we have two child instances for the same child and therefore we have disassociated sub-contexts for the common father and mother base context.
We could solve this problem with a bottom-up declaration. This form of declaration is not necessarily as intuitive in the UI and still results in the same problem of disassociated sub-contexts:
public class ChildParentRelationship : IRelationship { }
public class ChildContext : Context
{
public ChildContext()
{
Declare<PersonContext>().OneAndOnlyOne();
Declare<ChildParentRelationship, ChildContext, FatherContext>().OneAndOnlyOne();
Declare<ChildParentRelationship, ChildContext, MotherContext>().OneAndOnlyOne();
}
}
public class FatherContext : Context
{
public FatherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
public class MotherContext : Context
{
public MotherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example15.ChildContext
At first glance, this looks right:
And indeed, when we perform a search, we get the expected single context (we could fill):
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example15.PersonContext&isSearch=true
Remember that because we are only displaying the result for distinct root level contexts, only one search result is returned! And because contexts are bidirectional, we can populate the context from the root instance to reveal all the data in the context when it is viewed:
While it looks accurate, in the bottom-up declaration, we have disassociated the father and mother records from other contexts that should reference the same record. For example, if the father has a child with a different mother, there is no way to associate that the father is the same instance in both cases. This is actually the same issue as the top-down disassociation discussed previously, but it is potentially more hidden because of the bottom-up nature of the context graph.
Recursive contexts are another problem. Let's say we declare a person has having a relationship with a mother and a father. But of course, moms and dads are people too::
public class PersonContext : Context
{
public PersonContext()
{
Declare<PersonNameContext>().OneAndOnlyOne();
Declare<PersonFatherRelationship, PersonContext, FatherContext>().OneAndOnlyOne();
Declare<PersonMotherRelationship, PersonContext, MotherContext>().OneAndOnlyOne();
}
}
public class FatherContext : Context
{
public FatherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
public class MotherContext : Context
{
public MotherContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}}
}
I would have expected this to create a stack overflow, but it does not. Why? Because the relationship of father-person and mother-person are declared in the PersonContext not in the FatherContext or the MotherContext so these sub-contexts do not recurse. We can see this in the trace log:
However, if we exactly declare that a person has a relationship with a father and mother, and that the father and mother have a relationship with a person context, we get infinite recursion:
public class PersonFatherRelationship : IRelationship { }
public class PersonMotherRelationship : IRelationship { }
public class FatherPersonRelationship : IRelationship { }
public class MotherPersonRelationship : IRelationship { }
public class PersonContext : Context
{
public PersonContext()
{
Declare<PersonNameContext>().OneAndOnlyOne();
Declare<PersonFatherRelationship, PersonContext, FatherContext>().OneAndOnlyOne();
Declare<PersonMotherRelationship, PersonContext, MotherContext>().OneAndOnlyOne();
}
}
public class FatherContext : Context
{
public FatherContext()
{
Declare<FatherPersonRelationship, FatherContext, PersonContext>().OneAndOnlyOne();
}
}
public class MotherContext : Context
{
public MotherContext()
{
Declare<MotherPersonRelationship, MotherContext, PersonContext>().OneAndOnlyOne();
}
}
Of course, this is overkill--we could have simply stated that a father context as a relationship with a father context, or more generally expressed in this unit test:
public class RecursiveRelationship : IRelationship { }
public class RecursiveContext : Context
{
public RecursiveContext()
{
Declare<RecursiveRelationship, RecursiveContext, RecursiveContext>();
}
}
[TestMethod, ExpectedException(typeof(ContextException))]
public void RecursiveContextTest()
{
parser.Parse(new RecursiveContext());
}
As the unit test illustrates, we'd like the parser to detect this situation, which can be done easily enough by checking whether we've already encountered the exact same context in one of the super-contexts:
protected Group GenerateMasterGroups(Stack<ContextPath> contextPath,
List<Group> groups, Group group, IContext context, RelationshipDeclaration relationship)
{
if (contextPath.Any(c => c.Type == context.GetType()))
{
throw new ContextException("Context " + context.GetType().Name + " is recursive.");
}
...
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example16.PersonContext
In a traditional relational model, we don't encounter this problem for two reasons:
- A relational model is not bidirectional.
- A relational model associates related items through a unique key.
Let's explore this further.
Unlike relational models, contexts are bidirectional -- given the root context, one can determine all the sub-contexts associated with the root context. Conversely, given a sub-context, one can navigate the hierarchy to determine all the super-contexts, up to and including the root context, in which the sub-context is associated. With a relational model, it is the join statement that glues together disassociated contexts.
In a relational model, a top-down model tends to be counter-intuitive and requires going through a many-to-many relationship. This entity relationship model is rather atypical:
Technically, though it does express, via the FatherChildRelationship table, that the concept that a child has a father and a father has a child. The above model has many flaws though due to the requirement for a many-to-many separate relationship table:
- Fathers can exist without children.
- Children can exist without fathers.
- Children can have more than one father.
A more traditional relationship model would be bottom-up:
Here, while a Father record can exist without a Child record, a Child record requires a Father record and the each unique Child record can have only one Father record. We notice though that the "Father" table (a context) actually has no idea that it is referenced in another context (the "Child" table) at least not without inspecting the foreign key constraints in the entity relation diagram. This was, of course true as well in my top-down child context declaration:
public class ChildContext : Context
{
public ChildContext()
{
Declare<PersonContext>().OneAndOnlyOne();
}
}
The key word here is "declaration." In summary, the difference between a context instance and an entity model record instance is:
- A context can be navigated from top to bottom or bottom to top.
- If I query for a Father instance in a context, I get all the related sub-contexts. If I query the Father table in a relational model, I get only the Father records unless I explicitly join with the Child table.
- If I query for a Child instance in context, again I get all the related, but this time, super-contexts. If I query the Child table in a relational model, I get only the Child records unless I explicitly join with the Father table.
So far, the context examples that I've provided are lacking a unique key (or "unique identifier" if you prefer.) A unique key effectively states that the content of a record (or more traditionally stated, "the record instance") is the same among all entities that refer to that record by it's unique key. The problem is that the user must often be the one to determine whether the record content is unique or not. In fact, our user interfaces are tailored specifically so that we can assume that the user is working within a single context! For example, when entering a parent's children, the user interface assumes (and the user does as well) that we are in the context of the children of the indicated parents. If we're entering children and we want to also add their parents, the user interface (and the user) assume that we are in the context of a particular child and therefore the parents that we enter are specific to that child. So you can see how, via the user interface, we artificially create the context for a relational model that does not contain sufficient information to describe the context by itself.
To solve the disassociated context problem, we need a mechanism for declaring that, instead of creating a distinct context instance at some level in the hierarchy, we want to reference an existing context instance. Internally, we need the ability to associate this reference to an existing context graph. This is typically exposed in the UI by providing the user a means of looking up existing records and identifying which record is to be used as the reference. For example, showing the first part of the instance ID GUID paths dot-delimited:
URL: http://localhost/dictionary?showInstanceIds=true
We want the instance IDs of both ChildContexts to reference the same ChildContext. We should not need to create a separate ChildContext (though we could) -- instead, we should be able to look up all the child contexts so the user can select the correct one. Of course, this has its own drawbacks, as one would typically filter the child context by another context, such that the filter parameters might be "children of the father "Thomas Clifton." We have to revisit filtering to accomplish that, but for now, let's keep it simple for now, as implementing context references is complicated enough!
In the above screenshot, let's assume the father-child context was created first. The common part of the child context is f01d375b. In the mother-child context, we want to be able to use this ID, so instead of the mother-child context ID being a05e17ed.e4d8e9ca, we would like it instead to be a05e17ed.f01d375b, as well as all subsequent ID's at the second level of the ChildContext sub-contexts. Got that?
From the user interface perspective, we need two things:
- A way to define what should be displayed in each row of the lookup
- A way to look up existing context
If we want to stay with our declarative approach, let's try something fairly simple, which is declaring how a lookup should be rendered--again, we're going for minimal usefulness right now. We declare how a lookup should be rendered in the context for which we want to expose a lookup, in this case ChildContext:
public class ChildContext : Context
{
public ChildContext()
{
Declare<PersonContext>().OneAndOnlyOne();
Lookup<FirstName>().And(" ").And<LastName>();
}
}
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example17.FatherContext
Assuming some instances of ChildContext exist, this is what gets rendered on the page for any context that references ChildContext:
To reiterate, this is a very simplistic lookup -- there is no filtering, so all ChildContext instances are listed. For those interested in the behind-the-scenes implementation of populating the lookup, here's how it's done (read the comments!):
private static List<LookupItem> RenderOptionalLookup
(StringBuilder sb, Parser parser, Group group, ContextValueDictionary cvd)
{
List<LookupItem> lookupItems = new List<LookupItem>();
var groupContextType = group.ContextType;
int lookupId = 0;
if (cvd != null && parser.HasLookup(groupContextType))
{
Lookup lookup = parser.GetLookup(groupContextType);
IReadOnlyList<ContextNode> contextNodes = cvd.GetContextNodes(groupContextType);
if (contextNodes.Count > 0)
{
List<(string, int)> lookups = new List<(string, int)>();
foreach (var cn in contextNodes)
{
IReadOnlyList<ContextValue> contextValues = cvd.GetContextValues(cn);
var recnums = contextValues.Select(cv => cv.RecordNumber).Distinct();
foreach (var recnum in recnums)
{
string record = lookup.Render(cn, cvd, recnum, contextValues);
lookups.Add((record, lookupId));
var lookupEntities = lookup.GetLookupEntities();
foreach (var lookupEntity in lookupEntities)
{
var contextValue = contextValues.SingleOrDefault
(cv => cv.Type == lookupEntity.ValueEntity && cv.RecordNumber == recnum);
if (contextValue != null)
{
lookupItems.Add(new LookupItem(contextValue, groupContextType, lookupId));
}
}
}
}
sb.Append("Lookup: ");
sb.StartSelect().OnChange("populateFromLookup(this)");
sb.Option("Choose item:");
lookups.ForEach(lk => sb.Option(lk.Item1, lk.Item2.ToString()));
sb.EndSelect();
}
}
return lookupItems;
}
There is also a bit of magic that has to occur during rendering: the final wire-up of the context instance path for the lookup itself, which, if used, replaces the instance ID path for an input control whenever we are creating a new context. Given that we're not viewing an existing context:
if (mode != Mode.View)
{
instanceIdList = parser.CreateInstancePath(field.ContextPath.Select(cp => cp.Type));
LookupItemLateBinding(field, lookupItems, instanceIdList);
}
private static void LookupItemLateBinding(Field field, List<LookupItem> lookupItems,
List<Guid> instanceIdList)
{
foreach (var lookupItem in lookupItems.Where
(li => li.ContextValue.Type == field.ContextPath.Last().Type))
{
int idx = field.ContextPath.IndexOf(cp => cp.Type == lookupItem.ContextType);
lookupItem.NewContextInstancePath.AddRange(instanceIdList.Take(idx));
lookupItem.NewContextInstancePath.AddRange
(lookupItem.OriginalContextInstancePath.Skip(idx));
}
}
The comments should be adequate to explain the idea that the super-context IDs are preserved but the sub-context IDs are replaced to match the lookup item's context value instance path for the matching context value type. (That was a fun sentence to write!)
Next, in order for the selection event in the browser to know what to do, we have to provide the JavaScript with a way of handling the selection event:
- Here's the lookup we selected.
- Here's the fields that were used to render the lookup.
- Here's the input controls that the rendered fields map to.
- Now:
- Update "
cvid" string for that input control. - Set the input control's value.
- Notify the server of the value change.
Easy-peasy, right?
Let's make sure we have all the pieces. First, the lookup dictionary is set up in Javascript at the end of the UI rendering (CRLFs and JSON indented formatting added for readability when inspecting the source in the browser):
sb.EndDiv();
string jsonLookupDict = JsonConvert.SerializeObject(lookupDictionary, Formatting.Indented);
sb.Append(CRLF);
sb.StartScript().Append(CRLF).
Javascript("(function() {wireUpValueChangeNotifier(); wireUpEvents();})();").
Append(CRLF).
Javascript("lookupDictionary = " + jsonLookupDict + ";").
Append(CRLF).
EndScript().
Append(CRLF);
sb.EndBody().EndHtml();
After entering a single father-child relationship, we see this:
lookupDictionary = [
{
"OriginalContextInstancePath": [
"f9b77125-d1d9-45ae-b157-3ac95603d5c0",
"daf84e46-3389-46d2-a3b9-3c3cd992022f",
"cb9d73ae-18e2-4383-9667-da3885dfd777",
"6cc6d70a-cba1-4a75-8802-a389df2327d3",
"7ce2dc9c-1aa3-4b07-8551-11e7eafa73f1"
],
"NewContextInstancePath": [
"f9b77125-d1d9-45ae-b157-3ac95603d5c0",
"89638c69-0f38-4a5e-b95a-d171958a37be",
"118a4256-bd4b-48ba-9545-16d53888a374",
"08307f5e-f194-4b6a-9d70-0c0fdc7f8657",
"0abe703b-b79a-4d70-87c5-619042bdfef7"
],
"Value": "Marc",
"LookupId": 0
},
{
"OriginalContextInstancePath": [
"f9b77125-d1d9-45ae-b157-3ac95603d5c0",
"daf84e46-3389-46d2-a3b9-3c3cd992022f",
"cb9d73ae-18e2-4383-9667-da3885dfd777",
"6cc6d70a-cba1-4a75-8802-a389df2327d3",
"60c0815d-e9e7-43d1-aaf5-e8f4a1dfc7a5"
],
"NewContextInstancePath": [
"f9b77125-d1d9-45ae-b157-3ac95603d5c0",
"89638c69-0f38-4a5e-b95a-d171958a37be",
"118a4256-bd4b-48ba-9545-16d53888a374",
"08307f5e-f194-4b6a-9d70-0c0fdc7f8657",
"5c5e4d8b-25be-4d66-b525-b3b5a981d916"
],
"Value": "Clifton",
"LookupId": 0
}
];
Next, we observe how the dropdown list is rendered:
The option value is the LookupId in the JSON. We also note that the OriginalContextInstancePath is the instance ID path to the existing record (GUIDs are shortened to just the first segment):
Lastly, for the ChildContext first name input control, note the ID, which matches the NewContextInstancePath (new because it was created as a new context):
<input type="text" class="contextualValue requiredValue"
id="f9b77125-d1d9-45ae-b157-3ac95603d5c0.daf84e46-3389-46d2-a3b9-3c3cd992022f.
cb9d73ae-18e2-4383-9667-da3885dfd777.6cc6d70a-cba1-4a75-8802-a389df2327d3.
7ce2dc9c-1aa3-4b07-8551-11e7eafa73f1"
...
>
We can now correlate the ID set up for the new context: f9b77125..., daf84e46..., etc. with the OriginalContextPath for LookupID 0 and determine two things:
- The new context path--note how the super-context ID path (one super-context in this case)
f9b77125... is preserved--but the rest of the context path refers to the existing instance. - The value to set in the input control.
We now have all the pieces to implement the JavaScript that updates the cvid value and the input control's value:
function populateFromLookup(lookup) {
if (lookup.selectedIndex != 0) {
var lookupId = lookup[lookup.selectedIndex].value;
var records = findLookupRecords(lookupId);
updateInputControls(records);
sendFieldChanges(records);
}
}
function findLookupRecords(lookupId) {
var lookupRecords = [];
for (var idx = 0; idx < lookupDictionary.length; idx++) {
record = lookupDictionary[idx];
if (record.LookupId == lookupId) {
lookupRecords.push(record);
}
}
return lookupRecords;
}
function updateInputControls(records) {
for (var idx = 0; idx < records.length; idx++) {
var record = records[idx];
var originalId = record.OriginalContextInstancePath.join(".");
var docInput = document.getElementById(originalId);
docInput.value = record.Value;
docInput.setAttribute("cvid", record.NewContextInstancePath.join("."));
}
}
function sendFieldChanges(records) {
for (var idx = 0; idx < records.length; idx++) {
var record = records[idx];
var originalId = record.OriginalContextInstancePath.join(".");
sendFieldChange(originalId, "/updateField");
}
}
So far, in the ContextValueDictionary, we've been assuming that any "add" operation is for a completely new context graph. This is no longer the case, as we are now referencing an existing sub-context. This requires a tweak to the AddOrUpdate method. Also note that I discovered that this operation must be synchronous -- it worked before when the user inputs values into the browser's controls because the user types slowly. But when the browser updates all the associated values in a lookup context, these occur asynchronously.
public void AddOrUpdate(ContextValue cv)
{
lock (this)
{
Assert.That(cv.TypePath.Count == cv.InstancePath.Count,
"type path and instance path should have the same number of entries.");
ContextNode node = tree;
for (int i = 0; i < cv.TypePath.Count; i++)
{
var (id, type) = (cv.InstancePath[i], cv.TypePath[i]);
if (node.Children.TryGetSingle(c => c.InstanceId == id, out ContextNode childNode))
{
node = childNode;
}
else
{
if (flatView.TryGetValue(type, out List<ContextNode> nodes))
{
bool foundExistingSubContext = false;
foreach (var fvnode in nodes)
{
foreach (var fvnodepath in fvnode.InstancePaths())
{
if (cv.InstancePath.Skip(i).SequenceEqual(fvnodepath))
{
node.AddChild(fvnode);
node = fvnode;
foundExistingSubContext = true;
break;
}
}
if (foundExistingSubContext)
{
break;
}
}
if (!foundExistingSubContext)
{
node = CreateNode(i, id, cv, node, type);
}
}
else
{
node = CreateNode(i, id, cv, node, type);
}
}
}
node.ContextValue = cv;
}
}
After selecting an existing child for the "mother" context:
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example17.MotherContext
We note that the dictionary now references the child created in the "father" context:
As an aside, it's important to note that a root-level context cannot have a lookup. So, "father" and "mother", as root contexts, can never be referenced by other "father" or "mother" contexts. To achieve this, these two contexts would have to be wrapped in a super-context.
Searching has now been broken because it doesn't yet know about a context that references a sub-context from a different super-context. Again, a context path was expected to be unique. With a shared sub-context, we need to find all the other root contexts that share this sub-context. We add this call to the end of the Search method:
MatchWithContextsReferencingSubContext(matches);
Implementation:
protected void MatchWithContextsReferencingSubContext(List<ContextNode> matches)
{
foreach (ContextNode match in matches.ToList())
{
List<Guid> matchParentPath = match.GetParentInstancePath();
foreach (var nodes in flatView.Values.Where
(n=>n.Last().Parent.InstanceId == Guid.Empty))
{
ContextNode lastNode = nodes.Last();
foreach (var childNodeIdPath in lastNode.ChildInstancePaths())
{
if (childNodeIdPath.Any(id => id == match.InstanceId))
{
if (!matches.Any(m => m.GetParentInstancePath().First() == nodes.First().InstanceId))
{
matches.Add(lastNode);
}
}
}
}
}
}
And we get the expected result (both mother and father root contexts are found when searching on a shared sub-context):
URL: http://localhost/renderContext?ContextName=MeaningExplorer.Examples.Example17.PersonContext&isSearch=true
Putting this prototype together was considerably more difficult than I expected. This is partly because the concept itself is rather alien -- we think of context as having data rather than the opposite, data having context. There were a variety of rabbit holes that I went down and lots of code got deleted that turned out to be a dead end. Part of the complexity probably derives from the architecture itself -- using imperative code to define contexts declaratively as well as the particular approach that I took with the concept, that is, contexts can have "has a" relationships, one-to-many relationships, and abstractions. Also putting together a demo UI in the web browser meant pulling in my code base for my web server and working with Javascript. That said, there's a lot of flexibility that is achieved by rendering the UI in the browser rather than manipulating WinForm controls. Even with all the work that went into this, this prototype is still incomplete!
Also, a number of the links one can find regarding "contextual computing" refer to the context of data in "big data", particularly for the use of mining the data for sentiment analysis and real-time feedback (such as "what restaurants are near me that offer food based on other restaurants I've visited?" Determining context is also important in semantic analysis. If I say "I'm going to by an apple" does this mean I'm going to the grocery store or the Apple computer store? Contextual computing is definitely applicable to other emerging technologies, such as (of course) artificial intelligence. However, context is also critical in agent-based computing--a bunch of data doesn't have any particular meaning unless the agent knows the context of the data. So, in a very real sense, contextual computing is moving the field of data management forward such that data is no longer a static collection of facts and figures but is more "alive" -- data can now trigger concrete activities as determined by its context.
In a distributed computing environment, each node will have a different collection of data and most likely different context for that data. When one node asks the entire system to search for a particular contextual value match, the various distributed nodes might return hits for contexts that the requesting node knows nothing about. And while it can then query that node for its context definition, the salient point is that the context is included as part of the data values so that the requester can determine what to do with new contexts. This is the foundation, as the link at the beginning of article described, for the younger and more intelligent sibling of Big Data.
Not much!
https://github.com/levand/contextual
This library provides contextual data structures for maps and vectors that track their own context, from some arbitrary root.
- Hierarchical context searches -- fixing this:
Assert.That(contextValuesToSearch.All(cv => cv.InstancePath.Count == pathItems),
"Context values must have the same path length for now.");
in the ContextValueDictionary's Search method.
- Context lookup filtering:
If groups should only be allowed to coalesce if they have different sub-contexts (and hopefully different field labels.) Certainly, coalesced groups that have the same subgroups (like father group and mother group) would blow the lookup ID re-mapping out of the water because there would not be a way to distinguish father and mother groups. I think.
- Ability to update result contexts, particularly of note regarding context references.
- A real application use case with a real application UI!
- Solving the recursive context problem.
- Performance tests.
- Determining a reasonable data storage mechanism contextual data.
- Other, perhaps less complicated, implementations.
So far, there are 48 unit tests that are fairly comprehensive.
- https://www.techopedia.com/definition/31778/contextual-data
- https://www.wired.com/insights/2013/04/with-big-data-context-is-a-big-issue/
- 1st March, 2018: Initial version

