Introduction
A lot of the code used here to determine the programming language of a string of text has already been presented and discussed quite thoroughly in my previous article here: Create Your First Machine Learning Model to Filter Spam. In that article, we build a number of functions that are highly reusable in your machine learning pipeline.
In this article, we will focus mainly on those items that are unique to this problem.
Importing the Necessary Libraries
The norman Python import statements:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.utils import shuffle
from sklearn.metrics import precision_score, classification_report, accuracy_score
from sklearn.pipeline import FeatureUnion
from sklearn.preprocessing import LabelEncoder
import re
import time
Retrieving and Parsing Data
Most of my time for this challenge was spent figuring out how to effectively parse the data to extract the name of the language from the text and then remove that information from the text so that it doesn't taint our training and test datasets.
Here is an example of two of the text strings/segments (which span multiple lines and contain carriage returns):
<pre lang="Swift">
@objc func handleTap(sender: UITapGestureRecognizer) {
if let tappedSceneView = sender.view as? ARSCNView {
let tapLocationInView = sender.location(in: tappedSceneView)
let planeHitTest = tappedSceneView.hitTest(tapLocationInView,
types: .existingPlaneUsingExtent)
if !planeHitTest.isEmpty {
addFurniture(hitTest: planeHitTest)
}
}
}</pre>
<pre lang="JavaScript">
var my_dataset = [
{
id: "1",
text: "Chairman & CEO",
title: "Henry Bennett"
},
{
id: "2",
text: "Manager",
title: "Mildred Kim"
},
{
id: "3",
text: "Technical Director",
title: "Jerry Wagner"
},
{ id: "1-2", from: "1", to: "2", type: "line" },
{ id: "1-3", from: "1", to: "3", type: "line" }
];</pre>
The tricky part was getting the regular expression to return the data within the "<pre lang...><pre>" tags, then creating another regular expression to just return the "lang" portion of the "pre" tag.
It's not pretty and I am sure that it can be optimized, but it works:
def get_data():
file_name = './LanguageSamples.txt'
rawdata = open(file_name, 'r')
lines = rawdata.readlines()
return lines
def clean_data(input_lines):
all_found = re.findall(r'<pre[\s\S]*?<\/pre>', input_lines, re.MULTILINE)
clean_string = lambda x: x.replace('<', '<').replace('>', '>').replace
('</pre>', '').replace('\n', '')
all_found = [clean_string(item) for item in all_found]
get_language = lambda x: re.findall(r'<pre lang="(.*?)">', x, re.MULTILINE)[0]
lang_items = [get_language(item) for item in all_found]
remove_lang = lambda x: re.sub(r'<pre lang="(.*?)">', "", x)
all_found = [remove_lang(item) for item in all_found]
return (all_found, lang_items)
Create the Pandas DataFrame
Here we get the data, create a DataFrame and populate it with data.
all_samples = ''.join(get_data())
cleaned_data, languages = clean_data(all_samples)
df = pd.DataFrame()
df['lang_text'] = languages
df['data'] = cleaned_data
Here is what our DataFrame looks like:
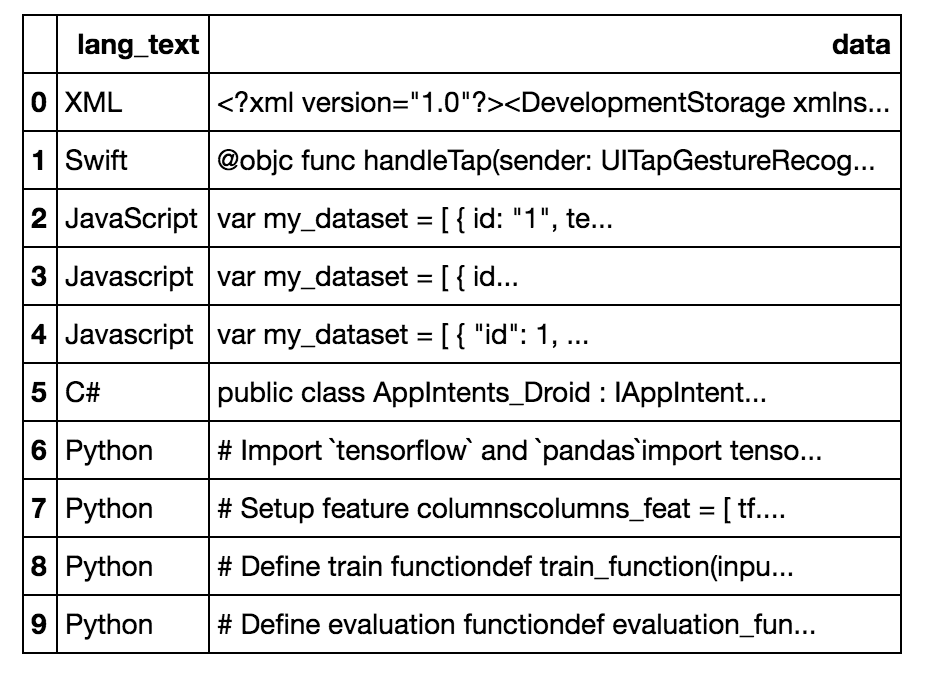
Creating a Categorical Column
The next thing we need to do it to turn our "lang_text" column into a numeric column as this is what many machine learning models are expecting for the "Y" or output that it is attempting to determine. To do this, we will use the LabelEncoder and use it to transform our "lang_text" column to a categorical column.
lb_enc = LabelEncoder()
df['language'] = lb_enc.fit_transform(df['lang_text'])
Now our DataFrame looks like this:
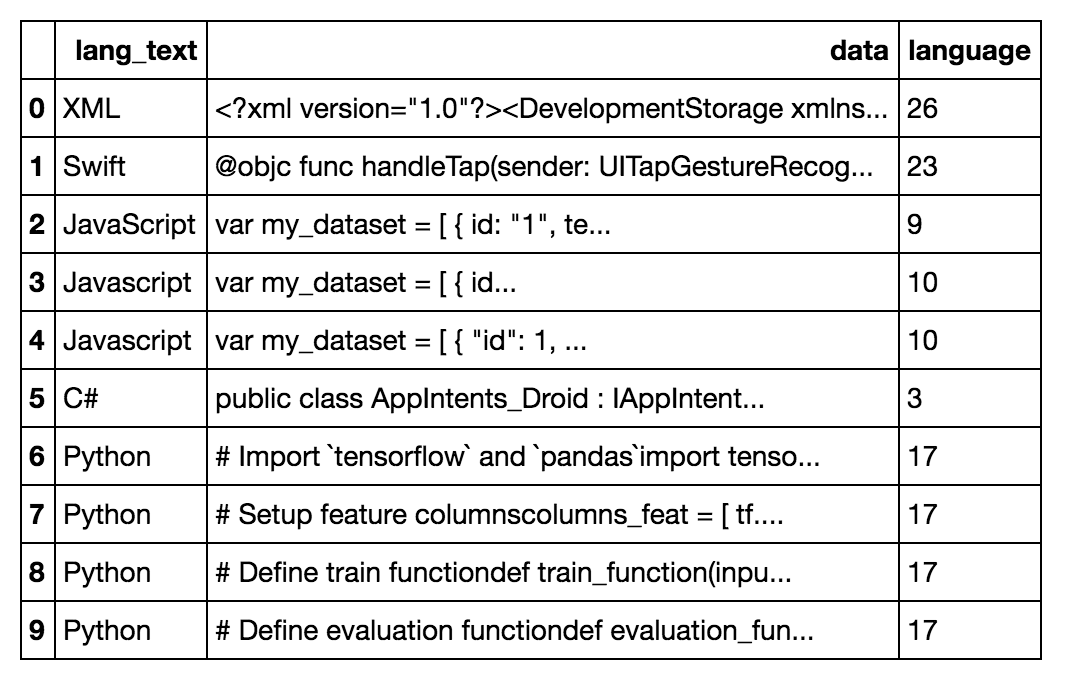
We can see how the column was encoded by running this:
lb_enc.classes_
Which displays this (the position in the array matches the integer value in the new "language" categorical column):
array(['ASM', 'ASP.NET', 'Angular', 'C#', 'C++', 'CSS', 'Delphi', 'HTML',
'Java', 'JavaScript', 'Javascript', 'ObjectiveC', 'PERL', 'PHP',
'Pascal', 'PowerShell', 'Powershell', 'Python', 'Razor', 'React',
'Ruby', 'SQL', 'Scala', 'Swift', 'TypeScript', 'VB.NET', 'XML'], dtype=object)
Boilerplate Code
As mentioned in the introduction, a lot of the code for this project was already discussed in my previous article Create Your First Machine Learning Model to Filter Spam which I recommend reading if you want more of the details on the code below.
In summary, here are the next steps:
- Declare the function for outputting the results of the training
- Declare the function for training and testing the models
- Declare the function for creating the models to test
- Shuffle the data
- Split the training and test data
- Pass the data and the models into the training and testing function and see the results:
def output_accuracy(actual_y, predicted_y, model_name, train_time, predict_time):
print('Model Name: ' + model_name)
print('Train time: ', round(train_time, 2))
print('Predict time: ', round(predict_time, 2))
print('Model Accuracy: {:.4f}'.format(accuracy_score(actual_y, predicted_y)))
print('')
print(classification_report(actual_y, predicted_y, digits=4))
print("=======================================================")
def test_models(X_train_input_raw, y_train_input, X_test_input_raw, y_test_input, models_dict):
return_trained_models = {}
return_vectorizer = FeatureUnion([('tfidf_vect', TfidfVectorizer())])
X_train = return_vectorizer.fit_transform(X_train_input_raw)
X_test = return_vectorizer.transform(X_test_input_raw)
for key in models_dict:
model_name = key
model = models_dict[key]
t1 = time.time()
model.fit(X_train, y_train_input)
t2 = time.time()
predicted_y = model.predict(X_test)
t3 = time.time()
output_accuracy(y_test_input, predicted_y, model_name, t2 - t1, t3 - t2)
return_trained_models[model_name] = model
return (return_trained_models, return_vectorizer)
def create_models():
models = {}
models['LinearSVC'] = LinearSVC()
models['LogisticRegression'] = LogisticRegression()
models['RandomForestClassifier'] = RandomForestClassifier()
models['DecisionTreeClassifier'] = DecisionTreeClassifier()
models['MultinomialNB'] = MultinomialNB()
return models
X_input, y_input = shuffle(df['data'], df['language'], random_state=7)
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X_input, y_input, test_size=0.7)
models = create_models()
trained_models, fitted_vectorizer = test_models(X_train_raw, y_train, X_test_raw, y_test, models)
And this is the result:
Model Name: LinearSVC
Train time: 0.99
Predict time: 0.0
Model Accuracy: 0.9262
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.8968 1.0000 0.9456 339
4 0.9695 0.8527 0.9074 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 0.9032 0.7568 0.8235 74
8 0.7778 0.5833 0.6667 36
9 0.9613 0.9255 0.9430 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 0.9589 0.9589 0.9589 73
18 1.0000 1.0000 1.0000 8
19 0.7600 0.9268 0.8352 41
20 0.1818 1.0000 0.3077 2
21 1.0000 1.0000 1.0000 137
22 1.0000 0.8750 0.9333 24
23 1.0000 1.0000 1.0000 7
24 1.0000 1.0000 1.0000 25
25 0.9571 0.9571 0.9571 70
26 0.9211 0.9722 0.9459 108
avg / total 0.9339 0.9262 0.9255 1422
=========================================================================
Model Name: DecisionTreeClassifier
Train time: 0.13
Predict time: 0.0
Model Accuracy: 0.9388
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.9123 0.9204 0.9163 339
4 0.8408 0.9196 0.8785 224
5 1.0000 0.8929 0.9434 28
6 1.0000 1.0000 1.0000 7
7 1.0000 0.9595 0.9793 74
8 0.9091 0.8333 0.8696 36
9 0.9817 1.0000 0.9908 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 0.5000 0.6667 6
16 1.0000 0.4000 0.5714 5
17 1.0000 1.0000 1.0000 73
18 1.0000 1.0000 1.0000 8
19 0.9268 0.9268 0.9268 41
20 1.0000 1.0000 1.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 0.7500 0.8571 24
23 1.0000 1.0000 1.0000 7
24 0.6786 0.7600 0.7170 25
25 1.0000 1.0000 1.0000 70
26 1.0000 1.0000 1.0000 108
avg / total 0.9419 0.9388 0.9376 1422
=========================================================================
Model Name: LogisticRegression
Train time: 0.71
Predict time: 0.01
Model Accuracy: 0.9304
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.9040 1.0000 0.9496 339
4 0.9569 0.8929 0.9238 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 0.8929 0.6757 0.7692 74
8 0.8750 0.5833 0.7000 36
9 0.9281 0.9627 0.9451 161
10 1.0000 0.5000 0.6667 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 0.9589 0.9589 0.9589 73
18 1.0000 1.0000 1.0000 8
19 0.7600 0.9268 0.8352 41
20 1.0000 1.0000 1.0000 2
21 1.0000 0.9781 0.9889 137
22 1.0000 0.8750 0.9333 24
23 1.0000 1.0000 1.0000 7
24 1.0000 1.0000 1.0000 25
25 0.9571 0.9571 0.9571 70
26 0.9211 0.9722 0.9459 108
avg / total 0.9329 0.9304 0.9272 1422
=========================================================================
Model Name: RandomForestClassifier
Train time: 0.04
Predict time: 0.01
Model Accuracy: 0.9374
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 1.0000 1.0000 1.0000 2
2 1.0000 1.0000 1.0000 1
3 0.8760 1.0000 0.9339 339
4 0.9452 0.9241 0.9345 224
5 0.9032 1.0000 0.9492 28
6 0.7000 1.0000 0.8235 7
7 1.0000 0.8378 0.9118 74
8 1.0000 0.5278 0.6909 36
9 0.9527 1.0000 0.9758 161
10 1.0000 0.1667 0.2857 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 1.0000 1.0000 1.0000 2
14 1.0000 0.4545 0.6250 11
15 1.0000 0.5000 0.6667 6
16 1.0000 0.4000 0.5714 5
17 1.0000 1.0000 1.0000 73
18 1.0000 0.6250 0.7692 8
19 0.9268 0.9268 0.9268 41
20 0.0000 0.0000 0.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 1.0000 1.0000 24
23 1.0000 0.5714 0.7273 7
24 1.0000 1.0000 1.0000 25
25 1.0000 0.9571 0.9781 70
26 0.8889 0.8889 0.8889 108
avg / total 0.9411 0.9374 0.9324 1422
=========================================================================
Model Name: MultinomialNB
Train time: 0.01
Predict time: 0.0
Model Accuracy: 0.8776
precision recall f1-score support
0 1.0000 1.0000 1.0000 6
1 0.0000 0.0000 0.0000 2
2 0.0000 0.0000 0.0000 1
3 0.8380 0.9764 0.9019 339
4 1.0000 0.8750 0.9333 224
5 1.0000 1.0000 1.0000 28
6 1.0000 1.0000 1.0000 7
7 0.6628 0.7703 0.7125 74
8 1.0000 0.5833 0.7368 36
9 0.8952 0.6894 0.7789 161
10 1.0000 0.3333 0.5000 6
11 1.0000 1.0000 1.0000 14
12 1.0000 1.0000 1.0000 5
13 0.0000 0.0000 0.0000 2
14 1.0000 0.7273 0.8421 11
15 1.0000 1.0000 1.0000 6
16 1.0000 0.4000 0.5714 5
17 1.0000 0.9178 0.9571 73
18 0.8000 1.0000 0.8889 8
19 0.4607 1.0000 0.6308 41
20 0.0000 0.0000 0.0000 2
21 1.0000 1.0000 1.0000 137
22 1.0000 1.0000 1.0000 24
23 1.0000 1.0000 1.0000 7
24 0.8462 0.8800 0.8627 25
25 0.8642 1.0000 0.9272 70
26 0.9630 0.7222 0.8254 108
avg / total 0.8982 0.8776 0.8770 1422
=========================================================================
Again for details on this code and the meaning or "accuracy", "precision", "recall", and "f1-support", please see my previous article - Create Your First Machine Learning Model to Filter Spam.
Conclusion
Machine learning, deep learning, and artificial intelligence are the future and we as software engineers need to understand and embrace the power that these technologies offer as we can leverage them to more effectively solve the problem that companies and clients we work for present to use and need our help in solving.
I have a blog that is dedicated to helping software engineers understand and develop their skills in the areas of machine learning, deep learning, and artificial intelligence. If you felt you learned something from this article, feel free to stop by my blog at CognitiveCoder.com.
Thanks for reading all the way to the bottom.
History
- 3/3/2018 - Initial version
- 3/3/2018 - Fixed broken image links

