Note: You can evaluate CodAI by visiting https://codai.herokuapp.com/
Introduction
In this article we will discuss programming language detection using deep neural networks . I used Keras with tensorflow backend for this task. CodAI uses a neural network quite similar to the my previous article LSTM Spam detector network https://www.codeproject.com/Articles/1231788/LSTM-Spam-Detection .
This article contains the following topics:
- Prepare train and test data
- Build the model
- Serve the model as REST api
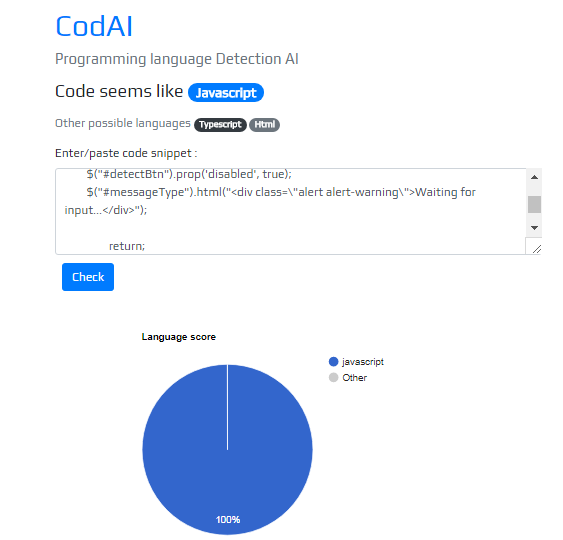
Using the code
1.Prepare train and test data
First step is to prepare the test data ,our test data is a text file with the HTML comprising PRE blocks that contain a code sample. I used BeautifulSoup to extract all PRE tag contents
soup = BeautifulSoup(open("LanguageSamples.txt"), 'html.parser')
count=0
code_snippets=[]
languages=[]
for pretag in soup.find_all('pre',text=True):
count=count+1
line=str(pretag.contents[0])
code_snippets.append(line)
languages.append(pretag["lang"].lower())
Next we need to tokenize the input, Keras Tokenizer is used for this with maximum features of 10000 and word indexes are saved to json file.
max_fatures=10000
tokenizer = Tokenizer(num_words=max_fatures)
tokenizer.fit_on_texts(code_snippets)
dictionary = tokenizer.word_index
# Let's save this out so we can use it later
with open('wordindex.json', 'w') as dictionary_file:
json.dump(dictionary, dictionary_file)
X = tokenizer.texts_to_sequences(code_snippets)
X = pad_sequences(X,100)
Y = pd.get_dummies(languages)
2.Build the model
CodAI neural network consists of convolutional neural network,LSTM and feed forwarded network.
embed_dim =128
lstm_out = 64
model = Sequential()
model.add(Embedding(max_fatures, embed_dim,input_length = 100))
model.add(Conv1D(filters=128, kernel_size=3, padding='same', dilation_rate=1,activation='relu'))
model.add(MaxPooling1D(pool_size=4))
model.add(Conv1D(filters=64, kernel_size=3, padding='same', dilation_rate=1,activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(lstm_out))
model.add(Dropout(0.5))
model.add(Dense(64))
model.add(Dense(len(Y.columns),activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
Model summary as shown below

This model trained for 400 epoches and gave 100% accuracy on validation data.
3. Serve the model as REST API
I used Flask and Heroku cloud platform for serving Keras model. convert_text_to_index_array function is used to convert input code snippet int to word vectors and this is fed into our neural network.
def convert_text_to_index_array(text):
wordvec=[]
global dictionary
for word in kpt.text_to_word_sequence(text) :
if word in dictionary:
if dictionary[word]<=10000:
wordvec.append([dictionary[word]])
else:
wordvec.append([0])
else:
wordvec.append([0])
return wordvec
predict route processes the input and predicts each class score and returns the result as json.
@app.route("/predict", methods=["POST"])
def predict():
global model
data = {"success": False}
X_test=[]
if flask.request.method == "POST":
code_snip=flask.request.json
word_vec=convert_text_to_index_array(code_snip)
X_test.append(word_vec)
X_test = pad_sequences(X_test, maxlen=100)
y_prob = model.predict(X_test[0].reshape(1,X_test.shape[1]),batch_size=1,verbose = 2)[0]
languages=['angular', 'asm', 'asp.net', 'c#', 'c++', 'css', 'delphi', 'html',
'java', 'javascript', 'objectivec', 'pascal', 'perl', 'php',
'powershell', 'python', 'razor', 'react', 'ruby', 'scala', 'sql',
'swift', 'typescript', 'vb.net', 'xml']
data["predictions"] = []
for i in range(len(languages)):
r = {"label": languages[i], "probability": format(y_prob[i]*100, '.2f') }
data["predictions"].append(r)
data["success"] = True
return flask.jsonify(data)
Conclusion
I learned many new things from this project.Programming language detection is a bit challenging one for me.Hope you enjoyed this article.
History
Updated broken image link

