Introduction
No one like spam messages -- how can spam automatically be flagged by a machine?
Is a message spam if it doesn't have that much spam in it?
How many spam words does a spam message need to have spam, to be spam, spam classified as spammity spam?
Text classification can be difficult because humans communicate using various languages, use slang, make spelling mistakes, and spammers continually update their methods.
Background
Text Classification Methods
- Keywords & Phrases: "winner", "free", "as seen on", "double your", "new rule"
- not statistical, just searching for text; but spammers have tricks you won't believe!
- Word statistics
The most frequent word in English is "THE" (other top words are: AND I OF A IS OR AT)...
- Spammers can get creative, misspell words
"m0rtgage", "F R E E", "ca$h", "\/laGr@", unicode characters that are visually similar - Spammers can paste in large sections of text (e.g. Melville or Poe) to throw the statistics off.
- Some languages don't space words: Chinese, Japanese, Thai
- Some languages fuse words together: Agglutinative Language
German "Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz" - A common method to reduce data for text searching is to exclude "stop" words:
Stop words are by definition the most common words, removing them may discard potentially helpful context.
- Multi Word stastics (n-gram / shingles)
Multiple words give the statistics more context, but require more training data.
"you win !" vs "winner is you"
- still susceptible to misspellings
- different word forms inflate the model size
verb forms / noun-verb agreement: single/plural, gender, tense, formality, subject/target...
- Multi word+character statistics <<-- this is what this article will be testing
- + multi-words for context
- + fallback to fewer words for untrained phrases
- + fallback to characters for untrained words
- + can easily edit the model, and quickly rerun it
- - large model size
- Wikipedia size example:
~10 languages, reduce to ~300k n-grams (50k each n-gram type) for each language
gigabytes to download and extract
several hours on a multi-core to reduce one language text to word frequency data
and ~1GB RAM to load the reduced model
Can effectively identify a language fragment of a few words (e.g., name of a book or play) - - Running: not super fast with large models, but not terribly slow when optimized...
* Tweakable: pre-processing, gram sizes/weights, model size, multithreading - Artificial Neural Networks:
* a rapidly growing field; many, many options
- can be difficult to impossible to trace back why something does or does not work
- training at scale can be time consuming and require large hardware resources
- editing the model typically requires retraining
Probability & Statistics
Bayes Rule: P(A|B) = P(B|A) * P(A) / P(B)
The probability of A (when B has occurred) = the probability of B (when A has occurred) * probability of A (anytime) / probability of B (anytime)
Applied to spam:
P(spam | word) = P( word | spam) * P(spam) / ( P(word | spam) + P(word | ham) )
Chain Rule: P(A & B) = P(A) * P(B)
Optimization: multiplying numbers is slower than adding, and tiny numbers can underflow
So use logarithms:
Log(A * B) = Log(A) + Log(B)
Log(A / B) = Log(A) - Log(B)
Fuzzy Logic: real world states may not be as binary as we model them
If the unknown unknowns turn out to be bigger than assumed, or hidden variables are involved...
Then it may not be safe to assume one thing excludes another: P(A) = 1 - P(B)
A message (or webpage) could contain both spam and non-spam, or be in a foreign language on which the model cannot make an informed decision.
Text Pre-Processing: It is extremely important to normalize spaces, and deal with symbols, numbers, etc. in a repeatable way.
Using the Code
var bec = new BayesEnsembleClassifier();
bec.Train(files);
bec.TrainPost();
bec.Test(filename_test);
for (int r = 5; r <= 95; r += 5) {
bec.TestRandom(filename_test, randomness);
}
The Train step tokenizes the text, removes HTML & builds frequency tables on n-gram shingles of 1-3 words, and 3,5,7 characters for both spam and ham. Character grams can cross words. Weights and sizes/lengths of n-grams are customizable.
Categories are dynamic (but an efficient storage needs a more complicated data structure to reduce size and avoid turnover).
For example:
- Top 2-word ham entries are: ". the", "the .", "the the", "and the"...
- Top 2 word spam entries: "and .", "to .", "his .", "he ."
- Top spam char-grams are " th", "the", " and ", " his ", " childe"
- Top ham char-grams are " th", "the", "ing", " the ", " and ", " that", "evermor"
Post: Filters out rare n-grams and pre-calculates Log probabilities
Test: Evaluates lines in the test file and displays TruePositive/TrueNegative/FalseNegative/FalsePositive & F-Score
TestRandom makes changes to the test text before processing (it increments randomly selected characters), and displays scores.
Points of Interest
Memory Usage: (provided training set)
Loading Peak 135MB
After Loading 47MB
Timing
Load/Train 6809ms (but optimized usage would save the reduced & compacted training data)
Eval 250ms (provided test set: 100 messages, 35583 words)
Resilience
Because the model includes character grams, it can successfully categorize text when upto 50% of the characters in the text are changed. (long after the individual words are humanly recognizable)
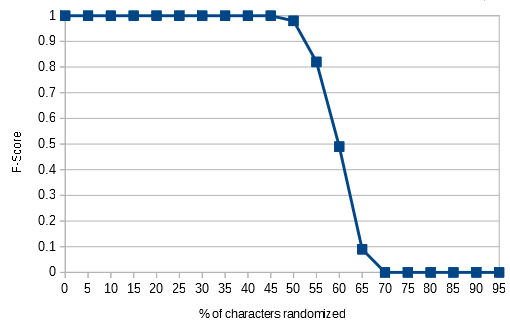
% Chars Changed, F-Score, Test Text (partial first line)
0% 1.00 bust by this expressing at stepped and . my my dreary a and . shaven we spoken
5% 1.00 bust by this eypressinh at stepped bnd . my my dreary a and . shaven we spoken
10% 1.00 bust by this eypressinh at suepped bnd . my my dreary a and . siaven we spoken
15% 1.00 bust by this eypressinh at suepped bnd . ny my ereary a and . siaven we sppkeo
20% 1.00 bust by this eypressinh at sufpped bnd . ny my ereary a and . siawen we sppkeo
25% 1.00 busu by this eypressinh at sufpped bnd . ny my eseary a and . siawen we sppkeo
30% 1.00 busu by uiis eypressinh at sufpqed bnd . nz my eseary a and . siawen we sppkeo
35% 1.00 busu by uiis eypretsinh at sufpqed bne . nz mz eseary a and . siawen we sppkeo
40% 1.00 busu by uiis eypretsinh at sufpqed boe . nz mz eseary a and . siawen we sppkeo
45% 1.00 busu bz uiis eypretsinh at sufpqed boe . nz mz esfary a and . siawen we sppkeo
50% 0.98 busu bz uijs eypretsinh at sufqqed boe . nz mz esfarz a and . siawen wf sppkeo
55% 0.82 busu bz uijs eypretsinh bt tufqqed boe . nz mz esfarz a and . siawen wf sppkeo
60% 0.49 butu bz uijs eypretsinh bt tufqqed boe . nz mz esfarz a and . siawen wf sppkeo
65% 0.09 butu bz uijt eypretsinh bt tufqqee boe . nz mz esfasz a and . siawfn wf sppkeo
70% 0.00 butu bz uijt eyprftsinh bt tufqqee boe . nz mz esfasz a ane . siawfn wf sppkeo
75% 0.00 butu bz uijt eyprftsinh bt tufqqee boe . nz mz esfbsz a bne . siawfn wf tpplfo
80% 0.00 bvtu bz uijt eyprftsinh bt tufqqee boe . nz nz esfbsz a bne . siawfn wf tpplfo
85% 0.00 cvtu bz uijt eyprfttjnh bt tufqqee boe . nz nz esfbsz a bne . sibwfo wf tqplfo
90% 0.00 cvtu bz uijt eyqrfttjnh bt tufqqee boe . nz nz esfbsz b boe . tibwfo wf tqplfo
95% 0.00 cvtu cz uijt eyqrfttjnh bu tufqqee boe . nz nz esfbsz b boe . tibwfo wf tqplfo
Notes
The final PredictLine() is a bit complicated...
Writing out loops to a multi-way grouping and aggregation takes a lot of code.
And LINQ queries are nearly impossible to debug if something was left out.
Not sure which is worse.
History

