In this article, I'm going to show you how to set up OpenShift to integrate with Splunk for logging in a Docker container orchestration environment.
These techniques could easily be adapted for a standard Kubernetes installation as well!

The techniques used in this article are based on the Kubernetes Logging Cluster Administration Guide. I also found Jason Poon's article Kubernetes Logging with Splunk very helpful.
First, clone the Terraform AWS OpenShift repo:
git clone git@github.com:dwmkerr/terraform-aws-openshift
This repo can be used to create a vanilla OpenShift cluster. I'm adding 'recipes' to the project, which will allow you to mix in more features (but still keep the main codebase clean). For now, let's merge in the 'splunk' recipe:
cd terraform-aws-openshift
git pull origin recipes/splunk
Pulling this recipe in adds the extra config and scripts required to set up Splunk.
Now that we've got the code, we can get started!
Create the Infrastructure
To create the cluster, you'll need to install the AWS CLI and log in, and install Terraform.
Before you continue, be aware: the machines on AWS we'll create are going to run to about $250 per month:
Once you are logged in with the AWS CLI, just run:
make infrastructure
You'll be asked to specify a region:
Any AWS region will work fine, use us-east-1 if you are not sure.
It'll take about 5 minutes for Terraform to build the required infrastructure, which looks like this:
Once it's done, you'll see a message like this:
The infrastructure is ready! A few of the most useful parameters are shown as output variables. If you log into AWS, you'll see our new instances, as well as the VPC, network settings, etc.
Installing OpenShift
Installing OpenShift is easy:
make openshift
This command will take quite some time to run (sometimes up to 30 minutes). Once it is complete, you'll see a message like this:
You can now open the OpenShift console. Use the public address of the master node (which you can get with $(terraform output master-url)), or just run:
make browse-openshift
The default username and password is admin and 123. You'll see we have a clean installation and are ready to create our first project:
Close the console for now.
Installing Splunk
You've probably figured out the pattern by now...
make splunk
Once this command is complete, you can open the Splunk console with:
make browse-splunk
Again, the username and password is admin and 123. You can change the password on login, or leave it:
You can close the Splunk console now, we'll come back to it shortly.
Demoing Splunk and OpenShift
To see Splunk and OpenShift in action, it helps to have some kind of processing going on in the cluster. You can create a very basic sample project which will spin up two nodes which just write a counter every second as a way to get something running:
make sample
This will create a simple 'counter' service:
We can see the logs in OpenShift:
Almost immediately, you'll be able to see the data in Splunk:
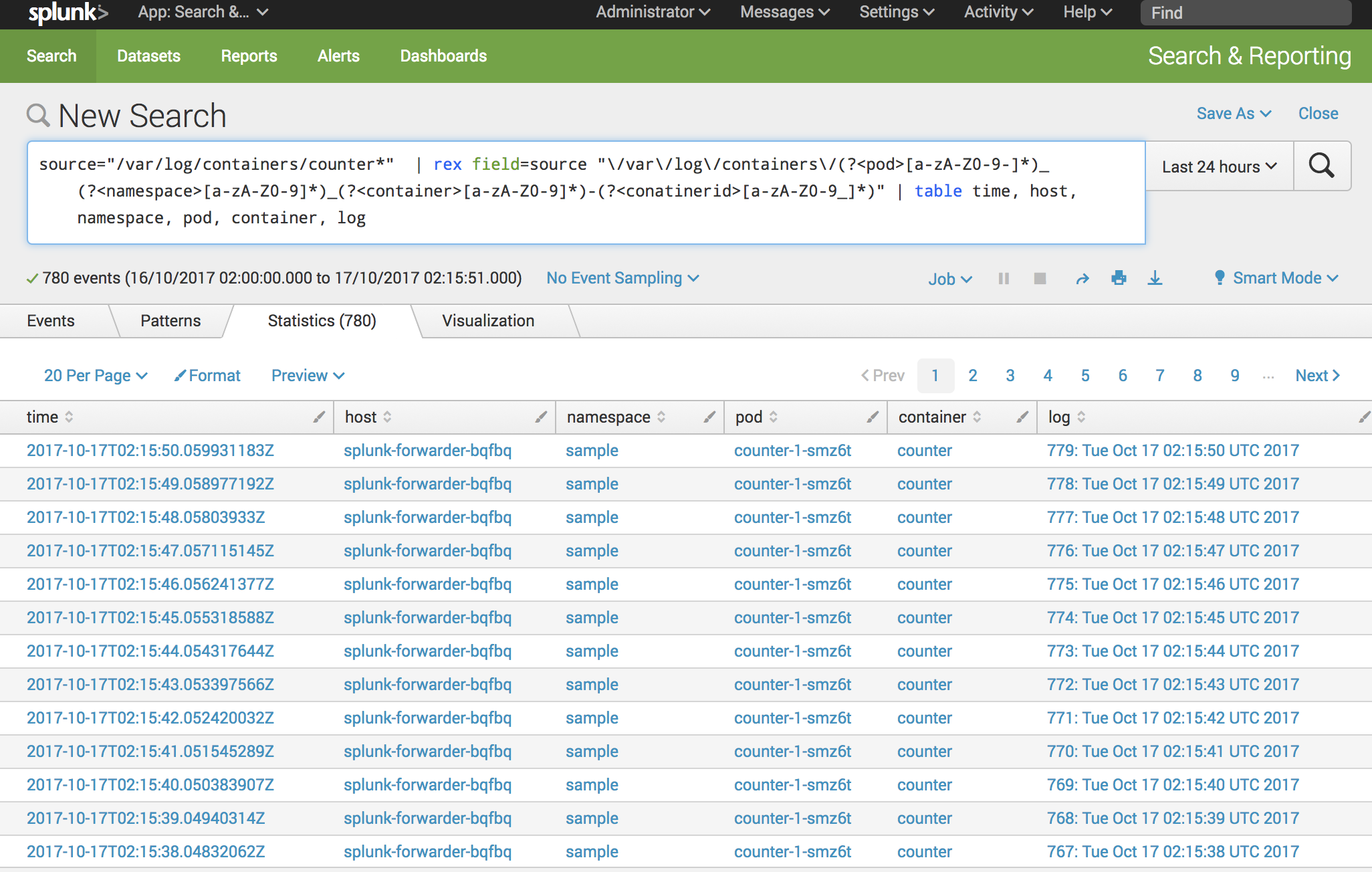
And because of the way the log files are named, we can even rip out the namespace, pod, container and id:
That's it! You have OpenShift running, Splunk set up and automatically forwarding of all container logs. Enjoy!
How It Works
I've tried to keep the setup as simple as possible. Here's how it works.
How Log Files are Written
The Docker Engine has a log driver which determines how container logs are handled. It defaults to the json-file driver, which means that logs are written as a json file to:
/var/lib/docker/containers/{container-id}/{container-id}-json.log
Or visually:
Normally, we wouldn't touch this file, in theory, it is supposed to be used internally and we would use docker logs <container-id>.
In theory, all we need to do is use a Splunk Forwarder to send this file to our indexer. The only problem is that we only get the container ID from the file name, finding the right container ID for your container can be a pain. However, we are running on Kubernetes, which means the picture is a little different...
How Log Files Are Written - on Kubernetes
When running on Kubernetes, things are little different. On machines with systemd, the log driver for the docker engine is set to journald (see Kubernetes - Logging Architecture).
It is possible to forward journald to Splunk, but only by streaming it to a file and then forwarding the file. Given that we need to use a file as an intermediate, it seems easier just to change the driver back to json-file and forward that.
So first, we configure the docker engine to use json-file (see this file):
sed -i '/OPTIONS=.*/c\OPTIONS="--selinux-enabled
--insecure-registry 172.30.0.0/16 --log-driver=json-file
--log-opt max-size=1M --log-opt max-file=3"' /etc/sysconfig/docker
Here, we just change the options to default to the json-file driver, with a max file size of 1MB (and maximum of three files, so we don't chew all the space on the host).
Now the cool thing about Kubernetes is that it creates symlinks to the log files, which have much more descriptive names:
We still have the original container log, in the same location. But we also have a pod container log (which is a symlink to the container log) and another container log, which is a symlink to the pod container log.
This means we can read the container log, and extract some really useful information from the file name. The container log file name has the following format:
/var/log/containers/{container-id}/{container-id}-json.log
How Log Files Are Read
Now that we are writing the log files to a well defined location, reading them is straightforward. The diagram below shows how we use a splunk-forwarder to complete the picture:
First, we create a DaemonSet, which ensures we run a specific pod on every node.
The DaemonSet runs with a new account which has the 'any id' privilege, allowing it to run as root. We then mount the log folders into the container (which are owned by root, which is why our container needs these extra permissions to read the files).
The pod contains a splunk-forwarder container, which is configured to monitor the /var/log/containers folder. It also monitors the docker socket, allowing us to see docker events. The forwarder is also configured with the IP address of the Splunk Indexer.

