Introduction
It's kind of scary realising that should your JavaScript fail, the only way you'll know is if some kind user lets you know. We've all seen "object x is undefined" errors and so on, how many times have you reported the error to the webmaster? It's easy for these problems to go unnoticed for prolonged periods of time.
I have recently been getting to grips with 'AJAX' techniques, and had a magic light-bulb moment when I realised that by using a combination of AJAX and C#, we can do away with reliance on users, and log the errors automatically ourselves.
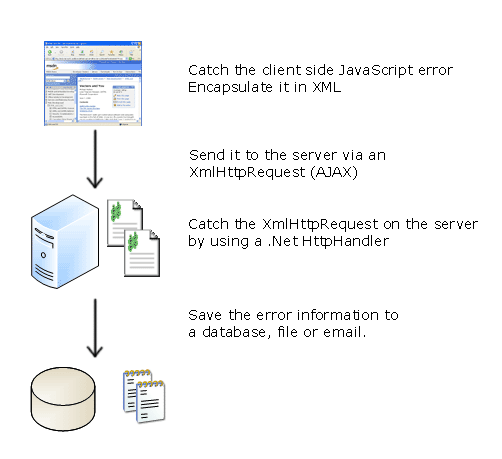
The basic plan of attack is as follows:
Background
The whole concept hinges on catching the errors in the first place, then using XMLHttpRequests to send the error data back to the server via a .NET HTTP handler which finally invokes a method of some kind that does something useful with the error information.
Check out MSDN for more info on catching errors on the client side.
If you haven't used AJAX before, I suggest the following helpful resources:
If you're new to HttpHandlers in .NET, go no further than:
Using the code
The sample ASP.NET (C#) project is pretty straightforward and easy to use (to get the sample code working, simply web-share the JavaScriptErrorLogger folder so that you make HTTP requests to the web server). Let's take a look at the essentials.
The good news is that it's pretty easy to apply the error catching code to existing JavaScripts. To handle errors, all you need to do is handle the Window.Onerror event:
window.onerror = errorHandler;
errorHandler will, of course, point to a function that does something constructive with the event:
function errorHandler(message, url, line)
{
alert( message + '\n' + url + '\n' + line );
return true;
}
Obviously, your error handling needs to be very reliable. Alerting the error data is not especially ground breaking, so here is the JavaScript used in the sample code which actually executes the XmlHttpRequest:
function errorHandler(message, url, line)
{
var xmlHttpRequest;
var bHookTheEventHandler = true;
if (document.all)
{
xmlHttpRequest = new ActiveXObject("Msxml2.XMLHTTP");
} else {
xmlHttpRequest = new XMLHttpRequest();
}
var xmlDoc = new ActiveXObject("Msxml2.DOMDocument.3.0");
xmlDoc.async = false;
xmlDoc.loadXML("<JavaScriptError line='" + line + "' url='"
+ url + "'>" + message +
"</JavaScriptError>");
if(bHookTheEventHandler)
{
xmlHttpRequest.onreadystatechange =
sendSomeXml_HandlerOnReadyStateChange;
}
xmlHttpRequest.open("post", "http://localhost/JavaScript" +
"ErrorLogger/logerror.ashx", bHookTheEventHandler);
xmlHttpRequest.send( xmlDoc );
return true;
}
Note that handling the xmlHttpRequest.onreadystatechange event is not necessary if you just want to log errors, but you could use it in this context if you wanted to let the user know that an error has occurred and has been logged.
Before we can catch any incoming requests, we need to tweak the web.config file (see the background links above for more info). The beauty of this approach is that the URL specified when making the XmlHttpRequest doesn't have to actually exist. In this example, the HTTP handler will catch requests for .ashx URLs.
<httpHandlers>
<add verb="*" path="*.ashx"
type="JavaScriptErrorLogger.LogErrorHandler, JavaScriptErrorLogger" />
</httpHandlers>
On the server side, we'll catch the incoming XML using an HTTP handler:
using System;
using System.Web;
using System.Xml;
namespace JavaScriptErrorLogger
{
public class LogErrorHandler : IHttpHandler
{
public void ProcessRequest( HttpContext httpContext )
{
XmlDocument xmlDoc = null;
if (httpContext.Request.InputStream.Length > 0 &&
httpContext.Request.ContentType.ToLower().IndexOf("/xml") > 0)
{
xmlDoc = new XmlDocument();
xmlDoc.Load( httpContext.Request.InputStream );
Console.WriteLine( xmlDoc.InnerXml );
}
}
}
}
Most of the examples I have found on the net make the client side XmlRequest using GET. If you want to send data to the server, you'll need to POST it (as in the error handling code provided earlier). Having used POST, we can get the data sent to the server by using httpContext.Request.InputStream (as above). In this example, we are simply outputting the XML to the console, where as in the sample code, we use a method that will log the XML to a file.
Having caught the XML in our HTTP handler, we could send it (or other XML) back out again:
public void ReturnXML( HttpContext httpContext, string rawXml )
{
if(rawXml == "")
throw new ApplicationException("The value of rawXml was not defined.");
httpContext.Response.ContentType = "application/xml";
XmlTextWriter xw = new XmlTextWriter( httpContext.Response.OutputStream,
new System.Text.UTF8Encoding() );
xw.WriteRaw( rawXml );
xw.Close();
}
Points of Interest
You will see in the sample code that I use a simple object to pass the error information about (at the C# level). This object has only one property (a string) which contains the XML that describes the error. But being clever, you'll realize that this could be extended to include any other info we want to send with the error, such as the client's browser and so on. You could go further and deserialize the XML straight into a C# object.
Since - in an ideal world - you'll never get any errors, it will be wise to construct a test-harness so you can periodically invoke an error and check that it is processing the errors just as you intend it to. If your system hasn't send you any error logs for a while, it'd be best if that was because there weren't any - not because the error handling is broken.

