In the previous article, we talked about the way that powerful type of Recurrent Neural Networks – Long Short-Term Memory (LSTM) Networks function. They are not keeping just propagating output information to the next time step, but they are also storing and propagating the state of the so-called LSTM cell. This cell is holding four neural networks inside – gates, which are used to decide which information will be stored in cell state and pushed to output. So, the output of the network at one time step is not depending only on the previous time step but depends on n previous time steps.
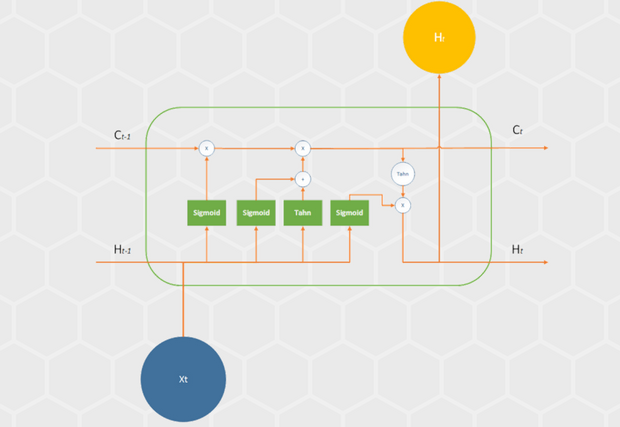
Ok, that is enough to get us up to speed with theory, and prepare us for the practical part – implementation of this kind of networks. In this article, we will consider two similar language modeling problems and solve them using two different APIs. Firstly, we will create the network that will be able to predict words based on the provided peace of text and for this purpose, we will use TensorFlow. In the second implementation, we will be classifying reviews from the IMDB dataset using the Keras.
Before we wander off into the problem we are solving and the code itself, make sure to setup your environment. As in all previous articles from this series, I will be using Python 3.6. Also, I am using Anaconda and Spyder, but you can use any IDE that you prefer. However, the important thing to do is to install Tensorflow and Keras.
The Problem for Tensorflow Implementation
Let’s say that we want to train one LSTM to predict the next word using a sample text. Simple text in our example will be one of the favorite sections of mine from Marcus Aurelius – Meditations:
In a sense, people are our proper occupation. Our job is to do them good and put up with them. But when they obstruct our proper tasks, they become irrelevant to us—like sun, wind, animals. Our actions may be impeded by them, but there can be no impeding our intentions or our dispositions. Because we can accommodate and adapt. The mind adapts and converts to its own purposes the obstacle to our acting. The impediment to action advances action. What stands in the way becomes the way.
Note that this text is a bit modified. Every punctuation mark is surrounded by space characters, ergo every word and every punctuation mark are considered as a symbol. To demonstrate how LSTM Networks work, we will use simplified process. We will push sequences of three symbols as inputs and one output. By repeating this process, the network will learn how to predict next word based on three previous ones.

Tensorflow Implementation
So, we have our plan of attack: provide a sequence of three symbols and one output to the LSTM Network and learn it to predict that output. However, since we are using mathematical models, the first thing we need to do is to prepare this data (text) for any kind of operation. These networks understand numbers, not strings as we have it in our text, so we need to convert these symbols into numbers. We will do this by assigning a unique integer to each symbol based on the frequency of occurrence.
For this purpose, we will use DataHandler class. This class has two purposes, to load the data from the file, and to assign a number to each symbol. Here is the code:
import numpy as np
import collections
class DataHandler:
def read_data(self, fname):
with open(fname) as f:
content = f.readlines()
content = [x.strip() for x in content]
content = [content[i].split() for i in range(len(content))]
content = np.array(content)
content = np.reshape(content, [-1, ])
return content
def build_datasets(self, words):
count = collections.Counter(words).most_common()
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return dictionary, reverse_dictionary
The first method of this class read_data is used to read text from the defined file and create an array of symbols. Here is how that looks like once called on the sample text:
The second method build_datasets is used for creating two dictionaries. The first dictionary labeled as just dictionary contains symbols as keys and their corresponding number as a value. Second dictionary reverse_dictionary contains the same information, just keys are numbers and values are the symbols themselves. This is how they will look like created using the sample text we are using in this example:
Awesome! Our data is ready for use. Off to the fun part, the creation of the model. For this purpose, we will create a new class that will be able to generate LSTM network based on the passed parameters. Take a look:
import tensorflow as tf
from tensorflow.contrib import rnn
class RNNGenerator:
def create_LSTM(self, inputs, weights, biases, seq_size, num_units):
# Reshape input to [1, sequence_size] and split it into sequences
inputs = tf.reshape(inputs, [-1, seq_size])
inputs = tf.split(inputs, seq_size, 1)
# LSTM with 2 layers
rnn_model = rnn.MultiRNNCell([rnn.BasicLSTMCell(num_units),rnn.BasicLSTMCell(num_units)])
# Generate prediction
outputs, states = rnn.static_rnn(rnn_model, inputs, dtype=tf.float32)
return tf.matmul(outputs[-1], weights['out']) + biases['out']
We imported some important classes there: TensorFlow itself and rnn class form tensorflow.contrib. Since our LSTM Network is a subtype of RNNs, we will use this to create our model. Firstly, we reshaped our input and then split it into sequences of three symbols. Then we created the model itself.
We created two LSTM layers using BasicLSTMCell method. Each of these layers has a number of units defined by the parameter num_units. Apart from that, we use MultiRNNCell to combine these two layers in one network. Then we used static_rnn method to construct the network and generate the predictions.
In the end, we will use SessionRunner class. This class contains environment in which our model will be run and evaluated. Here is how the code looks like:
import tensorflow as tf
import random
import numpy as np
class SessionRunner():
training_iters = 50000
def __init__(self, optimizer, accuracy, cost, lstm, initilizer, writer):
self.optimizer = optimizer
self.accuracy = accuracy
self.cost = cost
self.lstm = lstm
self.initilizer = initilizer
self.writer = writer
def run_session(self, x, y, n_input, dictionary, reverse_dictionary, training_data):
with tf.Session() as session:
session.run(self.initilizer)
step = 0
offset = random.randint(0, n_input + 1)
acc_total = 0
self.writer.add_graph(session.graph)
while step < self.training_iters:
if offset > (len(training_data) - n_input - 1):
offset = random.randint(0, n_input+1)
sym_in_keys = [ [dictionary[ str(training_data[i])]]
for i in range(offset, offset+n_input) ]
sym_in_keys = np.reshape(np.array(sym_in_keys), [-1, n_input, 1])
sym_out_onehot = np.zeros([len(dictionary)], dtype=float)
sym_out_onehot[dictionary[str(training_data[offset+n_input])]] = 1.0
sym_out_onehot = np.reshape(sym_out_onehot,[1,-1])
_, acc, loss, onehot_pred = session.run([self.optimizer, self.accuracy,
self.cost, self.lstm], feed_dict={x: sym_in_keys, y: sym_out_onehot})
acc_total += acc
if (step + 1) % 1000 == 0:
print("Iteration = " + str(step + 1) + ", Average Accuracy= " +
"{:.2f}%".format(100*acc_total/1000))
acc_total = 0
step += 1
offset += (n_input+1)
50000 iterations are being run using our model. We injected model, optimizer, loss function, etc. in the constructor, so the class has this information available. Of course, the first thing we need to do is slice up the data in the provided dictionary, and make encoded outputs (sym_in_keys and sym_out_onehot, respectively). Also, we are pushing random sequences in the model so we avoid overfitting. This is handled by offset variable. Finally, we will run the session and get accuracy. Don’t get confused by final if statement in the code. It is used just for display purposes (at every 1000 iterations present the average accuracy).
Our main script combines all this into one, and here is how it looks like:
import tensorflow as tf
from DataHandler import DataHandler
from RNN_generator import RNNGenerator
from session_runner import SessionRunner
log_path = '/output/tensorflow/'
writer = tf.summary.FileWriter(log_path)
# Load and prepare data
data_handler = DataHandler()
training_data = data_handler.read_data('meditations.txt')
dictionary, reverse_dictionary = data_handler.build_datasets(training_data)
# TensorFlow Graph input
n_input = 3
n_units = 512
x = tf.placeholder("float", [None, n_input, 1])
y = tf.placeholder("float", [None, len(dictionary)])
# RNN output weights and biases
weights = {
'out': tf.Variable(tf.random_normal([n_units, len(dictionary)]))
}
biases = {
'out': tf.Variable(tf.random_normal([len(dictionary)]))
}
rnn_generator = RNNGenerator()
lstm = rnn_generator.create_LSTM(x, weights, biases, n_input, n_units)
# Loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=lstm, labels=y))
optimizer = tf.train.RMSPropOptimizer(learning_rate=0.001).minimize(cost)
# Model evaluation
correct_pred = tf.equal(tf.argmax(lstm,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
initilizer = tf.global_variables_initializer()
session_runner = SessionRunner(optimizer, accuracy, cost, lstm, initilizer, writer)
session_runner.run_session(x, y, n_input, dictionary, reverse_dictionary, training_data)
Once we run this code, we get the accuracy of 97.10%:
The Problem for Keras Implementation
This example with TensorFlow was pretty straightforward, and simple. We used the small amount of data and network was able to learn this rather quickly. What if we have a more complex problem? For example, let’s say that we want to classify sentiment of each movie review on some site. Lucky for us, there is already a dataset, dedicated to this problem – The Large Movie Review Dataset (often referred to as the IMDB dataset).
This dataset was collected by Stanford researchers back in 2011. It contains 25000 movie reviews (good or bad) for training and the same amount of reviews for testing. Our goal is to create a network that will be able to determine which of these reviews are positive and which are negative. We will use Keras API which has this dataset built in.
Keras Implementation
The power of Keras is that it abstracts a lot of things we had to take care of while we were using TensorFlow. However, it is giving us a less flexibility. Of course, everything is a trade-off. So, let’s start this implementation by importing necessary classes and libraries.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM
from keras.datasets import imdb
As you can see, there is a little difference in imports from examples where we implemented standard ANN or when we implemented Convolutional Neural Network. We imported Sequential, Dense and Dropout. Still, we can see a couple new imports. We used Embedding as well as LSTM from the keras.layers. As you can imagine, LSTM is used for creating LSTM layers in the networks. Embedding, on the other hand, is used to provide a dense representation of words.
This is one cool technique that will map each movie review into a real vector domain. Words are encoded as real-valued vectors in a high dimensional space, where the similarity between words in terms of meaning translates to closeness in the vector space. We can notice that we imported imdb dataset that is provided in the keras.datasets. However, to load data from that dataset, we need to do this:
num_words = 1000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
We are loading dataset of top 1000 words. After this, we need to divide this dataset and create and pad sequences. This is done by using sequence from keras.preprocessing, like this:
X_train = sequence.pad_sequences(X_train, maxlen=200)
X_test = sequence.pad_sequences(X_test, maxlen=200)
In the padding, we used number 200, meaning that our sequences will be 200 words long. Here is how training input data looks like after this:
Now we can define, compile and fit LSTM model:
# Define network architecture and compile
model = Sequential()
model.add(Embedding(num_words, 50, input_length=200))
model.add(Dropout(0.2))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(250, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
As we have learned from the previous articles, Sequential is used for model composition. The first layer that is added to it is Embedding and we’ve explained its purpose in the previous chapter. After the word embedding is done, we added one LSTM layer. In the end, since this is a classification problem, we are trying to figure out was the review good or bad, Dense layer with sigmoid function is added. Finally, the model is compiled and binary_crossentorpy and Adam optimizer are used. This is how our model looks like:
Let’s fit our data to the model and get the accuracy:
.gist table { margin-bottom: 0; }
We got the accuracy of 85.12%.
Conclusion
We saw two approaches when creating LSTM networks. Both approaches were dealing with simple problems and each was using a different API. This way, one could see that TensorFlow is more detailed and flexible, however, you need to take care of lot more stuff than when you are using Keras. Keras is simpler and more straightforward but it doesn’t give us the flexibility and possibilities we have when we are using pure TensorFlow. Both of these examples provided ok results, but they could be even better. Especially the second example, for which we usually use a combination of CNN and RNN to get higher accuracy, but that is a topic for another article.
Thanks for reading!

