Introduction
Through this article, we are going to discuss three important interview questions of SQL which are given below:
- Can we create clustered index on a column containing duplicate values?
- Can we create a Primary Key on a table on which a clustered index is already defined?
- If a clustered index is already defined on a table and we create a primary key on this table, then is there any index that is automatically created on the column on which Primary key is defined?
Many people say no for the first question as they always consider clustered index and Primary key together and primary key can only be created on column with unique and not null values. Since primary key and clustered index combination is always considered as the best combination like made in heaven so many people thought clustered index can only be created on the column on which primary key is created.
But this is not correct. We can create clustered index on the columns on which primary key is not defined or in simple words, clustered index can be created on the non primary key column of a table. We know that when we defined primary key, a clustered index is created on the column / columns automatically by default. But if a clustered index is already defined for the table and we created the primary key later, then clustered index is not created on the primary key column as only one clustered index can be possible for a table which is in this case, already defined. So Primary key and clustered index are both different objects in SQL. Uniqueness is a must in case of Primary key but it is not a must condition in case of Clustered Index.
For example:
Suppose we have a table called tbl_clustered whose structure is given below:
create table tbl_clustered (Id int identity(1,1), Empname nvarchar(200 ))
Below is the data inserted query to insert data in the table tbl_clustered:
Insert into tbl_clustered (Empname )Values
(‘Kumar’),
(‘Gupta’),
(‘Arora’),(‘Gupta’),
(‘Gupta’)
Now let's see the data inserted into the table using the below query:
select * from tbl_clustered
Result
Id Empname
1 Kumar
2 Gupta
3 Arora
4 Gupta
5 Gupta
So till now, we have created a table and inserted some data in it. ID column is the identity column and Empname is varchar type column and we inserted some duplicate values in the Empname column.
Some people thought when we create an Identity column, primary key is automatically created on it. This is wrong. We usually create primary key on Identity column as it contains unique and not null value but primary key is not created on it by default unless we create it manually.
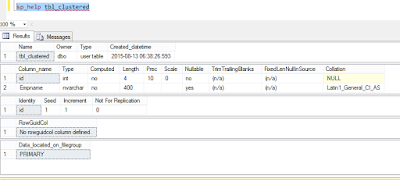
Let's see the table structure to make sure that no primary key or clustered index is created on the table yet.
To see the table structure, we use the following command:
sp_help tbl_clustered
Now let's create a clustered index on the table tbl_clustered.
Create clustered index inx_clux_test on tbl_clustered(Empname).
The above command will create the clustered index successfully irrespective of the fact that Empname column contains the duplicate values. Let's check the table structure again.
sp_help tbl_clustered
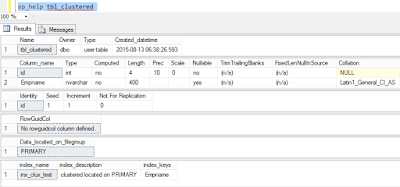
If you see the above picture, you can find the details of clustered index in the last row.
Now let's create a Primary key on the table to show that if a clustered index is already created on a table and then we try to create a primary key, then the primary key is created but without any clustered index.
Let's create the primary key using the below script.
Alter table tbl_clustered, add primary key (id).
Let's see the table details again to check if any clustered index is created on the primary key column when we defined the primary key in the table.
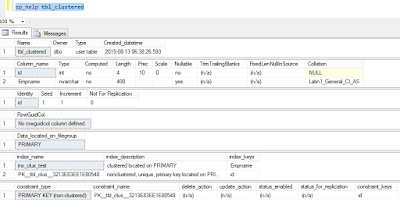
If we see the above picture, we get to know, if we create a primary key on table on which a clustered index is already defined, then a non clustered index is created automatically on the primary key column. So the table has two indexes:
- Clustered Index defined manually by us on the table initially
- Non clustered index created automatically with the creation of primary key on the column on which Primary key is defined
Summary
Through this article, I tried to show that primary key and clustered index are different objects. We can create a clustered index on the column which contains duplicate values but primary key can only be created on the column which contains unique and not null values. Also, if a clustered index is already defined on a table and we try to create a primary on the table, then a non-clustered index is created on the column on which the primary key is defined (instead of clustered index). But we should try to design the database so that clustered index is created on the primary key as we mostly use primary key in Joins conditions. Also, primary key is referred by the foreign keys. So clustered index on the primary key helps in increasing the database performance. You can refer to the following articles for better understanding of the concepts used in this article.
For Primary Keys
For Indexes
Keep learning and don’t forget to gives feedback on the article. You can also send feedback to me on my mailid askvivekjohari@gmail.com.
The post Interview question – Is Clustered index on column with duplicate values possible? appeared first on Technology with Vivek Johari.

