This article I will be talking about Apache
Spark / Databricks. It will guide you
through how to use the new cloud based hosted Databricks platform. This article
will talk about it from a Microsoft Azure standpoint but it should be exactly
the same ideas if you were to use Amazon cloud.
A picture says a thousand word, they say, so here is a nice picture of what
Apache Spark is.
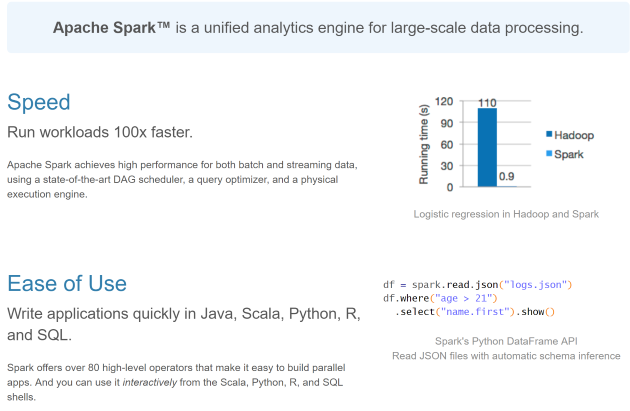
CLICK FOR BIGGER IMAGE
At its heart Apache
Spark is a tool for Data Scientists to allow them to explore and
crunch vaste amounts of data with ease. It features things like
- Distributed Datasets (so that number crunching can happen across a
compute cluster)
- A DataFrame API, such that you can do things like add columns, aggregate
column values, and alias data, join DataFrames. This also supports a SQL
syntax, and also rund distrobuted across a cluster
- A streaming API
- A Machine Learning API
- A Graph API
Spark also comes with various adaptors to allow it connect to various data
sources such as
- Blobs
- Databases
- Filesystems (HDFS / s3 / Azure storage / azure datalake / Databricks
file system)
This is not the first time I have written about Apache
Spark, here are some older articles on it should you be interested
So when I wrote those articles, there was limited options about how you could
run you Apache
Spark jobs on a cluster, you could basically do one of the following:
- Create a Java/Scala/Python app that used the Apache
Spark APIs and would run against a cluster
- Create a JAR that you could get an existing cluster to run using a
spark-submit command line
The problem with this was that neither were ideal, with the app approach you
didnt really want your analytics job to be an app, you really just wanted it to
be a class library of some sort
Spark-Submit would let you submit a class library, however the feedback that
you got from it was not great
There was another product that came out to address this call
Apache Livy that was a REST API
over Apache
Spark . But it too had its issues, in that it was not that great to setup,
and the API was fairly limited. To address this the good folk that own/maintain
Apache Spark came out with Databricks.
Databricks is essentially a fully managed Apache
Spark in the Cloud (Amazon / Azure). It also has the concept of REST
APIs for common things. Lets dig into that next.
Just before we get into Databricks, why
is it that I think it's so cool?
Well I have stated one point above already, but lets see the full list
- Great (really good) REST API
- Nice managemanent dashboard in the cloud
- The ability to create a on-demand cluster for your own job run that is
torn down at the end of the job is MASSIVE.
The reason this one point alone should make you think about examining Databricks
is as follows
- By using your own cluster you are not sharing any resources with
some one else, so you can guarentee your performance based on the nodes
you choose for your cluster
- The cluster gets torn down after your job has run. This saves you
money
- If you chose to use a single cluster rather than a new
cluster per job, you can have the single static cluster set to
AutoScale. This is a pretty neat feature. Just imagine trying to do
that in-premise. Obviously sinceApache
Spark
also supports running on Kubernetes that does ease the process a bit.
However to my mind to make the best use of Kubernetes you also want to run
that on a Cloud such as Amazon / Azure / Google, as scaling the VMs needed
for a cluster is just so MUCH easier if you are in a Cloud. Just as an aside
if you don't know your Kubernetes from an onion I wrote a mini series on it
which you can find here :
https://sachabarbs.wordpress.com/kubernetes-series/
- It's actually fairly cheap I think for what it gives you
- It's highly intuitive
So there is a small bit of code that goes with this article, which is split
into 2 things
- A throw-away WPF app that simply acts as a vehicle to demonstrate the
REST calls, in all seriousness you could use postman for the Databricks
REST exploration. The WPF app just makes this easier, as you don't have to
worry about remembering to set an access token, once you have set it up
once, and trying to find the right REST API syntax. The UI just shows you a
working set of REST calls for Databricks
- A simple IntelliJ IDEA Scala/SBT project, that represents a Apache
Spark job that we wish to upload and run on Databricks.
This will compiled using SBT, as such SBT is a must have if you want to run
this code
The code repo can be found here :
https://github.com/sachabarber/databrick-azure-spark-demo
There are a few of these, not because Databricks
needs them as such, but because I was keen to show you an entire workflow of how
you might use Databricks for real to do
your own jobs, which means we should create a new JAR file to act as a job to
send to Databricks.
As such the following is required
- A Databricks installation (either
Amazon/Azure hosted)
- Visual Studio 2017 (Community editition is fine here)
- Java 1.8 SDK installed and in your path
- IntelliJ IDEA Community Edition 2017.1.3 (or later)
- SBT Intellij IDEA plugin installed
Obviously if you just want to read along and not try this yourself, you won't
need any of this
As I said already I will be using Microsoft Azure, but after the initial
creation of Databricks in the Cloud (which
will be cloud vendor specific) the rest of the instructions should hold for
Amazon or Azure.
Anyway the first step for working with Databricks
in the cloud is to create a new Databricks
instance. Which for Azure simple means creating a new resource as follows:

CLICK FOR BIGGER IMAGE
Once you have creating the Databricks
instance, you should be able to launch the workspace from the overview of the Databricks
instance
CLICK FOR BIGGER IMAGE
This should launch you into a new Databricks
workspace website that is coupled to your Azure/Amazon subscription, so you
should initially see something like this after you have passed the logging in
phase (which happens automatically, well on Azure it does anyway)
CLICK FOR BIGGER IMAGE
From here you can see/do the following things, some of which we will explore
in more detail below
- Create a new Job/Cluster/Notebook
- Explore DBFS (Databricks
file system) data
- Look at previous job runs
- View / start / stop clusters
In this section we are going to explore what you can do in the Databricks
workspace web site that is tied to your Databricks
cloud installation . We will not be leaving the workspace web site, everything
below will be done directly in the workspace web site, which to my mind is
pretty cool, but where this stuff really shines is when we get to do all of this
stuff programatically, rather than just clicking buttons on a web site.
After all we would like to build this stuff into our own processing
pipelines. Luckily there is a pretty good one-one translation from what you can
do using the web site compared to what is exposed via the rest API. But I am
jumping ahead we will get there in the section after this, so for now lets just
examine what we can do in the Databricks
workspace web site that is tied to your Databricks
cloud installation.
So the very first thing you might like to do is create a cluster to run some
code on. This is easily done using the Databricks
workspace web site as follows
This will bring you to a screen like this, where you can configure your
cluster, where you pick the variouos bits and peices for your cluster
CLICK FOR BIGGER IMAGE
Once you have created a cluster it will end up being listed on the clusters
overview page
CLICK FOR BIGGER IMAGE
- Interactive clusters are ones that are tied to Notebooks which we look
at next
- Job clusters are ones that are used to run Jobs
Now I am a long time Dev (I'm old, or feel it or something), so think nothing
about opening up an IDE and writing an app/class lib/jar whatever. Bust at its
heart Apache
Spark is a tool for data scientists, who simply want to try some simple bits
of number crunching code. That is exactly where notbooks come into play.
A notebook is a cellular editor that is hosted, that allows the user to run
python/R/Scala code against a Apache
Spark cluster.
You can create a new notebook from the home menu as shown below
CLICK FOR BIGGER IMAGE
So after you have picked your language you will be presented with a blank
notebook where you can write some code into the cells. Teaching you the short
cuts and how to use notebooks properly is outside the scope of this article, but
here is some points on notebooks:
- They allow you to quickly explore the APIs
- They allow you to re-assign variables which are remembered
- They allow you to enter just a specific cell
- They give you some pre-defined variables. But be wary you will need to
swap these out if you translate this to real code. For example
spark
is a pre-defined variable
So lets say I have just created a Scala notebook, and I typed the text as
shown below in a cell. I can quickly run this using ALT + Enter or the run
button in the notebook UI
CLICK FOR BIGGER IMAGE
What this will do is run the active cell and print out the variables/output
statements to the notebook UI, which can also be seen above
One of the very common tasks when using Apache
Spark is to grab some data from some external source and save it to storage
once transformed into the required results
Here is an example of working with an existing Azure Blob Storage Account and
some Scala code. This particular example simply loads a CSV file from Azure Blob
Storage transforms the file and then saves it back to Azure Blob Storage as a
date stamped named CSV file
import java.util.Calendar
import java.text.SimpleDateFormat
spark.conf.set("fs.azure.account.key.YOUR_STORAGE_ACCOUNT_NAME_HERE.blob.core.windows.net", "YOUR_STORAGE_KEY_HERE")
spark.sparkContext.hadoopConfiguration.set(
"fs.azure.account.key.YOUR_STORAGE_ACCOUNT_NAME_HERE.blob.core.windows.net",
"YOUR_STORAGE_KEY_HERE"
)
val now = Calendar.getInstance().getTime()
val minuteFormat = new SimpleDateFormat("mm")
val hourFormat = new SimpleDateFormat("HH")
val secondFormat = new SimpleDateFormat("ss")
val currentHour = hourFormat.format(now)
val currentMinute = minuteFormat.format(now)
val currentSecond = secondFormat.format(now)
val fileId = currentHour + currentMinute + currentSecond
fileId
val data = Array(1, 2, 3, 4, 5)
val dataRdd = sc.parallelize(data)
val ages_df = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("wasbs://YOUR_CONTAINER_NAME_HERE@YOUR_STORAGE_ACCOUNT_NAME_HERE.blob.core.windows.net/Ages.csv")
ages_df.head
val selectedData = ages_df.select("age")
selectedData.write
.format("com.databricks.spark.csv")
.option("header", "false")
.save("wasbs://YOUR_CONTAINER_NAME_HERE@YOUR_STORAGE_ACCOUNT_NAME_HERE.blob.core.windows.net/" + fileId + "_SavedAges.csv")
val saved_ages_df = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("wasbs://YOUR_CONTAINER_NAME_HERE@YOUR_STORAGE_ACCOUNT_NAME_HERE.blob.core.windows.net/" + fileId + "_SavedAges.csv")
saved_ages_df.show()
Which for me looked like this for my storage account in Azure
CLICK FOR BIGGER IMAGE
If you are wondering why there are folders for the results such as
080629_SavedAges.csv, this is due to how Apache
Spark deals with partitions. Trust me it doesnt matter when you load things
back into memory as Apache
Spark just deals with this, as can be seen
CLICK FOR BIGGER IMAGE
The Databricks
web UI allows you to create a new job from either a Notebook or a JAR that you
have that you can drag in and set a main entry point for. You may also setup a
schedule and a cluster that you want to use. Once you are happy you can click
the "run now" button which will run your job.
CLICK FOR BIGGER IMAGE
Once you have run a job it is likely that you want to have a look at it to
see that it worked how you expected it to work, and that it is running
optimally. Luckily Apache
Spark comes equipt with a nice visualiser for a given analysis run that you
can use for this. Its kind of like the SQL Query Profiler in SQL Server.
This is accessible from the jobs page
CLICK FOR BIGGER IMAGE
So lets take a look at a successful job, which we can view using the "Succeeded"
link in the Last Run column in the Jobs page.
From there we can view the Apache
Spark UI or the logs for the job.
Lets see the Apache
Spark UI for this job.
CLICK FOR BIGGER IMAGE
The Spark UI is your friend, try and get acquianted with it
Ok so now that we have covered how to use the Databricks
web UI, how about we get familiar with the REST API such that we can craft our
own code around using Apache
Spark as our analytics engine. This next section will show how to use some
of the REST APIs available.
So you may now be wondering what APIs are actually available? This is the
place to check :
https://docs.databricks.com/api/latest/index.html
From there the main top level APIs are
- Clusters
- DBFS
- Groups
- Instance Profiles
- Jobs
- Libraries
- Secrets
- Token
- Workspace
There are simply not enough hours in the day for me to show you ALL of them.
So I have chosen a few to demo, which we will talk about below
The Databricks
REST APIs ALL need to have a JWT token associated with them. Which means you
need to firstly create a token for this. This is easily achieved in the Databricks
web UI. Just follow these steps
CLICK FOR BIGGER IMAGE
So once you have done that, grab the token value, and you will also need to
take a note of one other bit of information which is shown highlighted in the
image below. With these 2 bits of information we can use Postman to try a
request
CLICK FOR BIGGER IMAGE
So as I just said you will need to ensure that the token from the previous
step is supplied on every call. But just how do we do that? What does it look
like? Lets use Postman to show an example using the last 2 bits of information
from the previous pararaph
The token you got from above needs to be turned into a Base64 encoded string.
There are many online tools for this, just pick one. The important thing to note
is that you must ALSO include a prefix of "token:". So the full
string to encode is something like "token:dapi56b...........d5"
This will give you a base64 encoded string. From there we need to head into
Postman to try out the request, which may look somethinng like this
CLICK FOR BIGGER IMAGE
The important things to note here are:
Obviously you could just mess around in Postman to learn how the Databricks
REST APIs work, nothing wrong with that at all. But to make life easier for you
I have come up with a simple (throw away) demo app that you can use to explore
what I think are the 2 most important APIs
This is what it looks like running
And here is what it looks like when you have chosen to run one of the
pre-canned REST API calls that the demo app provides
So above when I started talking about the Databricks
REST APIs we said we needed to supply an API token. So how does the demo app
deal with this.
Well there are 2 parts to how it does that, this entry in the App.Config
should point to your own file that contains the token information
So for me this is my file
C:\Users\sacha\Desktop\databrick-azure-spark-demo\MyDataBricksToken.txt
Where the file simply contains a single line of contents "token:dapi56b...........d5"
which is the base64 encoded string proceeded by "token:" which we
talked about above.
This is then read into a globally available property in the demo app as
follows:
using System.Configuration;
using System.IO;
using System.Windows;
using SAS.Spark.Runner.REST.DataBricks;
namespace SAS.Spark.Runner
{
public partial class App : Application
{
protected override void OnStartup(StartupEventArgs e)
{
base.OnStartup(e);
var tokenFileName = ConfigurationManager.AppSettings["TokenFileLocation"];
if (!File.Exists(tokenFileName))
{
MessageBox.Show("Expecting token file to be provided");
}
AccessToken = File.ReadAllText(tokenFileName);
if(!AccessToken.StartsWith("token:"))
{
MessageBox.Show("Token file should start with 'token:' +
"following directly by YOUR DataBricks initial token you created");
}
}
public static string AccessToken { get; private set; }
}
}
And that is all there is to it. The demo app should take care of the rest of
it for you.
As I say I did not have time to explore every single API, but I had time to
look at 2 of the most common ones, Clusters and Jobs. Which I will talk about
below.
But before I get into that, I just wanted to show you the rough idea behind
each of the API explorations
Most of the API explorations are done using a viewmodel something like this
using SAS.Spark.Runner.REST.DataBricks;
using System;
using System.Threading.Tasks;
using System.Windows.Input;
using SAS.Spark.Runner.Services;
namespace SAS.Spark.Runner.ViewModels.Clusters
{
public class ClusterGetViewModel : INPCBase
{
private IMessageBoxService _messageBoxService;
private IDatabricksWebApiClient _databricksWebApiClient;
private string _clustersJson;
private string _clusterId;
public ClusterGetViewModel(
IMessageBoxService messageBoxService,
IDatabricksWebApiClient databricksWebApiClient)
{
_messageBoxService = messageBoxService;
_databricksWebApiClient = databricksWebApiClient;
FetchClusterCommand =
new SimpleAsyncCommand<object, object>(ExecuteFetchClusterCommandAsync);
}
private async Task<object> ExecuteFetchClusterCommandAsync(object param)
{
if(string.IsNullOrEmpty(_clusterId))
{
_messageBoxService.ShowError("You must supply 'ClusterId'");
return System.Threading.Tasks.Task.FromResult<object>(null);
}
try
{
var cluster = await _databricksWebApiClient.ClustersGetAsync(_clusterId);
ClustersJson = cluster.ToString();
}
catch(Exception ex)
{
_messageBoxService.ShowError(ex.Message);
}
return System.Threading.Tasks.Task.FromResult<object>(null);
}
public string ClustersJson
{
get
{
return this._clustersJson;
}
set
{
RaiseAndSetIfChanged(ref this._clustersJson,
value, () => ClustersJson);
}
}
public string ClusterId
{
get
{
return this._clusterId;
}
set
{
RaiseAndSetIfChanged(ref this._clusterId,
value, () => ClusterId);
}
}
public ICommand FetchClusterCommand { get; private set; }
}
}
The idea being that we use simple REST Service and we have a property representing the JSON response.
The REST service implements this interface
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
namespace SAS.Spark.Runner.REST.DataBricks
{
public interface IDatabricksWebApiClient
{
Task<CreateJobResponse> JobsCreateAsync(string jsonJobRequest);
Task<DatabricksRunNowResponse> JobsRunNowAsync(DatabricksRunNowRequest runRequest);
Task<DatabricksRunResponse> JobsRunsGetAsync(int runId);
Task<JObject> JobsListAsync();
Task<DatabricksRunNowResponse> JobsRunsSubmitJarTaskAsync(RunsSubmitJarTaskRequest runsSubmitJarTaskRequest);
Task<DatabricksClusterStartResponse> ClustersStartAsync(string clusterId);
Task<JObject> ClustersGetAsync(string clusterId);
Task<ClusterListResponse> ClustersListAsync();
Task<DbfsListResponse> DbfsListAsync();
Task<JObject> DbfsPutAsync(FileInfo file);
Task<DatabricksDbfsCreateResponse> DbfsCreateAsync(DatabricksDbfsCreateRequest dbfsRequest);
Task<JObject> DbfsAddBlockAsync(DatabricksDbfsAddBlockRequest dbfsRequest);
Task<JObject> DbfsCloseAsync(DatabricksDbfsCloseRequest dbfsRequest);
}
}
The actual UI is simple done using a DataTemplate, where we have bound the ViewModel in question to a
ContentControl. For the JSON representation I am just using the
AvalonEdit TextBox.
Here is an example for the ViewModel above:
<Controls:MetroWindow x:Class="SAS.Spark.Runner.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:vms="clr-namespace:SAS.Spark.Runner.ViewModels"
xmlns:vmsClusters="clr-namespace:SAS.Spark.Runner.ViewModels.Clusters"
xmlns:vmsJobs="clr-namespace:SAS.Spark.Runner.ViewModels.Jobs"
xmlns:avalonEdit="http://icsharpcode.net/sharpdevelop/avalonedit"
xmlns:Controls="clr-namespace:MahApps.Metro.Controls;assembly=MahApps.Metro"
xmlns:local="clr-namespace:SAS.Spark.Runner"
mc:Ignorable="d"
WindowState="Maximized"
Title="DataBricks API Runner">
<Controls:MetroWindow.Resources>
.....
.....
<DataTemplate DataType="{x:Type vmsClusters:ClusterGetViewModel}">
<DockPanel LastChildFill="True">
<StackPanel Orientation="Horizontal" DockPanel.Dock="Top">
<Label Content="ClusterId" Margin="3" VerticalAlignment="Center"
VerticalContentAlignment="Center" Height="24"/>
<TextBox Text="{Binding ClusterId}" Width="200" VerticalAlignment="Center"
VerticalContentAlig
nment="Center" Height="24"/>
<Button Content="Get Cluster" Margin="3,0,3,0" Width="100"
HorizontalAlignment="Left"
VerticalAlignment="Center"
VerticalContentAlignment="Center"
Command="{Binding FetchClusterCommand}"/>
</StackPanel>
<avalonEdit:TextEditor
FontFamily="Segoe UI"
SyntaxHighlighting="JavaScript"
FontSize="10pt"
vms:TextEditorProps.JsonText="{Binding ClustersJson}"/>
</DockPanel>
</DataTemplate>
<Controls:MetroWindow.Resources>
</Controls:MetroWindow>
As the ViewModels used in the demo app all mainly follow this pattern, I wont
be showing you any more ViewModel code apart from one where we upload a JAR file
as that one is a bit special.
Just have in the back of your mind that all roughly work this way, and you
will be ok
This section shows the Cluster APIs that I chose to look at
Databricks docs are here :
https://docs.databricks.com/api/latest/clusters.html#list, and this API call
does the following:
- Returns information about all pinned clusters, currently active
clusters, up to 70 of the most recently terminated interactive clusters in
the past 30 days, and up to 30 of the most recently terminated job clusters
in the past 30 days. For example, if there is 1 pinned cluster, 4 active
clusters, 45 terminated interactive clusters in the past 30 days, and 50
terminated job clusters in the past 30 days, then this API returns the 1
pinned cluster, 4 active clusters, all 45 terminated interactive clusters,
and the 30 most recently terminated job clusters.
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<ClusterListResponse> ClustersListAsync()
{
var request = new RestRequest("api/2.0/clusters/list", Method.GET);
request.AddHeader("Authorization", $"Basic {_authHeader}");
var response = await _client.ExecuteTaskAsync<ClusterListResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<ClusterListResponse>(response.Content);
return dbResponse;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
Databricks docs are here :
https://docs.azuredatabricks.net/api/latest/clusters.html#get, and this API
call does the following:
- Retrieves the information for a cluster given its identifier. Clusters
can be described while they are running, or up to 60 days after they are
terminated
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<JObject> ClustersGetAsync(string clusterId)
{
var request = new RestSharp.Serializers.Newtonsoft.Json.RestRequest("api/2.0/clusters/get", Method.GET);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddQueryParameter("cluster_id", clusterId);
var response = await _client.ExecuteTaskAsync(request);
JObject responseContent = JObject.Parse(response.Content);
return responseContent;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
Databricks docs are here :
https://docs.azuredatabricks.net/api/latest/clusters.html#start, and this
API call does the following:
- Starts a terminated Spark cluster given its ID. This is similar to
createCluster, except:
- The previous cluster id and attributes are preserved.
- The cluster starts with the last specified cluster size. If the
previous cluster was an autoscaling cluster, the current cluster starts
with the minimum number of nodes.
- If the cluster is not currently in a TERMINATED state, nothing will
happen.
Clusters launched to run a job cannot be started.
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<DatabricksClusterStartResponse> ClustersStartAsync(string clusterId)
{
var request = new RestSharp.Serializers.Newtonsoft.Json.RestRequest("api/2.0/clusters/start", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(new { cluster_id = clusterId });
var response = await _client.ExecuteTaskAsync<DatabricksClusterStartResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DatabricksClusterStartResponse>(response.Content);
return dbResponse;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
This section shows the Jobs APIs that I chose to look at
Databricks docs are here :
https://docs.databricks.com/api/latest/jobs.html#list, and this API call
does the following:
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<JObject> JobsListAsync()
{
var request = new RestSharp.Serializers.Newtonsoft.Json.RestRequest("api/2.0/jobs/list", Method.GET);
request.AddHeader("Authorization", $"Basic {_authHeader}");
var response = await _client.ExecuteTaskAsync(request);
JObject responseContent = JObject.Parse(response.Content);
return responseContent;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
Databricks docs are here :
https://docs.databricks.com/api/latest/jobs.html#create, and this API call
does the following:
- Creates a new job with the provided settings
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<CreateJobResponse> JobsCreateAsync(string jsonJobRequest)
{
var request = new RestSharp.Serializers.Newtonsoft.Json.RestRequest("api/2.0/jobs/create", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddParameter("application/json", jsonJobRequest, ParameterType.RequestBody);
var response = await _client.ExecuteTaskAsync<CreateJobResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<CreateJobResponse>(response.Content);
return dbResponse;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
An example request for this one is worth a special call out, as its not a simple parameter, we need to pass in quite a lot of JSON form this request. Here is an example
request for a job that runs at 10:15pm each night:
{
"name": "Nightly model training",
"new_cluster": {
"spark_version": "4.0.x-scala2.11",
"node_type_id": "r3.xlarge",
"aws_attributes": {
"availability": "ON_DEMAND"
},
"num_workers": 10
},
"libraries": [
{
"jar": "dbfs:/my-jar.jar"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2"
}
}
],
"email_notifications": {
"on_start": [],
"on_success": [],
"on_failure": []
},
"timeout_seconds": 3600,
"max_retries": 1,
"schedule": {
"quartz_cron_expression": "0 15 22 ? * *",
"timezone_id": "America/Los_Angeles"
},
"spark_jar_task": {
"main_class_name": "com.databricks.ComputeModels"
}
}
Although the demo app doesn't use this one directly, I use a very similar one,
which I will go through it quite some detail below.
Databricks docs are here :
https://docs.databricks.com/api/latest/jobs.html#runs-get, and this API call
does the following:
- Retrieves the metadata of a run
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<DatabricksRunResponse> JobsRunsGetAsync(int runId)
{
var request = new RestRequest("api/2.0/jobs/runs/get", Method.GET);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddQueryParameter("run_id", runId.ToString());
var response = await _client.ExecuteTaskAsync<DatabricksRunResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DatabricksRunResponse>(response.Content);
return dbResponse;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
Databricks docs are here :
https://docs.databricks.com/api/latest/jobs.html#jobsrunnow, and this API call
does the following:
- Runs the job now, and returns the run_id of the triggered run
This is simply done via the following code
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
.....
.....
public async Task<DatabricksRunNowResponse> JobsRunNowAsync(DatabricksRunNowRequest runRequest)
{
var request = new RestRequest("api/2.0/jobs/run-now", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(runRequest);
var response = await _client.ExecuteTaskAsync<DatabricksRunNowResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DatabricksRunNowResponse>(response.Content);
return dbResponse;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
Where we use this sort of request
using Newtonsoft.Json;
namespace SAS.Spark.Runner.REST.DataBricks.Requests
{
public class DatabricksRunNowRequest
{
[JsonProperty(PropertyName = "job_id")]
public int JobId { get; set; }
}
}
Databricks docs are here :
https://docs.azuredatabricks.net/api/latest/jobs.html#runs-submit, and this API call
does the following:
- Submit a one-time run with the provided settings. This endpoint doesn't
require a Databricks job to be created. You can directly submit your
workload. Runs submitted via this endpoint don't show up in the UI. Once the
run is submitted, you can use the
jobs/runs/get API to check
the run state.
Now this is probably the most complex, but most useful of ALL of the REST
APIs, a it allows you to do the following :
- Run by using a JAR writen Scala (where you can pass in command line args
too)
- Run using a notebook
- Run using a python file (where you can pass in command line args too)
As I am quite keen on Scala I will be using Scala for the demo
The demo code has a 2nd project in the source code :
Src/SAS.SparkScalaJobApp
which is a IntelliJ IDEA Scala project. To run
this you will need the prerequisites at the top of this article.
One you have downloaded the code you should run SBT in a command line window,
and navigate to the Src/SAS.SparkScalaJobApp folder. And
issue these SBT command
> clean
>compile
>assembly
From there you should be able to go to the Target directory and see a FAT Jar
(one with all dependencies bundled together)
We will use this in just a moment, but lets just take a minute to examine the
code. It is a very simple Spark job that expects a single Int command line
argument (that we will send via the REST call in a moment), and will then create
List of that many items that have some simple Spark transformations applied.
NOTE :
One thing to note is that we need to be careful about how we use
things like SparkContext and SparkSession which if you
have done any spark before you will have created yourself. When using a Cloud
provider such as AWS or Azure you need to use the existing
SparkContext
and
SparkSession, and we also need to avoid
terminating/shutting down this items, as they are in effect shared. This blog is
a good read on this :
https://databricks.com/blog/2016/08/15/how-to-use-sparksession-in-apache-spark-2-0.html
import scala.util.Try
import scala.util.Success
import scala.util.Failure
import org.apache.spark.sql.SparkSession
object SparkApp extends App {
println("===== Starting =====")
if(args.length != 1) {
println("Need exactly 1 int arg")
}
Try {
Integer.parseInt(args(0))
} match {
case Success(v:Int) => {
val combinedArgs = args.aggregate("")(_ + _, _ + _)
println(s"Args were $combinedArgs")
SparkDemoRunner.runUsingArg(v)
println("===== Done =====")
}
case Failure(e) => {
println(s"Could not parse command line arg [$args(0)] to Int")
println("===== Done =====")
}
}
}
object SparkDemoRunner {
def runUsingArg(howManyItems : Int) : Unit = {
val session = SparkSession.builder().getOrCreate()
import session.sqlContext.implicits._
val multiplier = 2
println(s"multiplier is set to $multiplier")
val multiplierBroadcast = session.sparkContext.broadcast(multiplier)
val data = List.tabulate(howManyItems)(_ + 1)
val dataRdd = session.sparkContext.parallelize(data)
val mappedRdd = dataRdd.map(_ * multiplierBroadcast.value)
val df = mappedRdd.toDF
df.show()
}
}
Anyway so once we have that Jar file available, we need to use a few APIs
which I will go through 1 by 1, but here is the rough flow:
- Examine if the chosen Jar file exists in the Dbfs (Databricks file
system, which means we have uploaded it already)
- Start the upload of the file (which we have to do in chunks as there is
a 1MB limit on the single
2.0/dbfs/put API) to get a file handle
- Upload blocks of data for the file hadle as Base64 encoded strings
- Close the file using the file handle
- Craft a runs-submit request to make use of the just uploaded/latest Dbfs
file
So that's the rough outline of it
So here is the ViewModel that will allow you pick the Jar (which as stated
above should be in the Target folder of the Src/SAS.SparkScalaJobApp
source code if you followed the instructions above to compile it using SBT.
using SAS.Spark.Runner.REST.DataBricks;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Windows.Input;
using SAS.Spark.Runner.Services;
using System.Linq;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using System.Collections.Generic;
using Newtonsoft.Json;
using System.Diagnostics;
namespace SAS.Spark.Runner.ViewModels.Jobs
{
public class JobsPickAndRunJarViewModel : INPCBase
{
private IMessageBoxService _messageBoxService;
private IDatabricksWebApiClient _databricksWebApiClient;
private IOpenFileService _openFileService;
private IDataBricksFileUploadService _dataBricksFileUploadService;
private string _jarFilePath;
private string _status;
private FileInfo _jarFile;
private bool _isBusy;
private bool _isPolling = false;
private string _jobsJson;
private Stopwatch _watch = new Stopwatch();
public JobsPickAndRunJarViewModel(
IMessageBoxService messageBoxService,
IDatabricksWebApiClient databricksWebApiClient,
IOpenFileService openFileService,
IDataBricksFileUploadService dataBricksFileUploadService)
{
_messageBoxService = messageBoxService;
_databricksWebApiClient = databricksWebApiClient;
_openFileService = openFileService;
_dataBricksFileUploadService = dataBricksFileUploadService;
PickInputJarFileCommand = new SimpleAsyncCommand<object, object>(x => !IsBusy && !_isPolling, ExecutePickInputJarFileCommandAsync);
}
public string JobsJson
{
get
{
return this._jobsJson;
}
set
{
RaiseAndSetIfChanged(ref this._jobsJson, value, () => JobsJson);
}
}
public string JarFilePath
{
get
{
return this._jarFilePath;
}
set
{
RaiseAndSetIfChanged(ref this._jarFilePath, value, () => JarFilePath);
}
}
public string Status
{
get
{
return this._status;
}
set
{
RaiseAndSetIfChanged(ref this._status, value, () => Status);
}
}
public bool IsBusy
{
get
{
return this._isBusy;
}
set
{
RaiseAndSetIfChanged(ref this._isBusy, value, () => IsBusy);
}
}
public ICommand PickInputJarFileCommand { get; private set; }
private async Task<object> ExecutePickInputJarFileCommandAsync(object param)
{
IsBusy = true;
try
{
_openFileService.Filter = "Jar Files (*.jar)|*.jar";
_openFileService.InitialDirectory = @"c:\";
_openFileService.FileName = "";
var dialogResult = _openFileService.ShowDialog(null);
if(dialogResult.Value)
{
if(!_openFileService.FileName.ToLower().EndsWith(".jar"))
{
_messageBoxService.ShowError($"{_openFileService.FileName} is not a JAR file");
return Task.FromResult<object>(null);
}
_jarFile = new FileInfo(_openFileService.FileName);
JarFilePath = _jarFile.Name;
var rawBytesLength = File.ReadAllBytes(_jarFile.FullName).Length;
await _dataBricksFileUploadService.UploadFileAsync(_jarFile, rawBytesLength,
(newStatus) => this.Status = newStatus);
bool uploadedOk = await IsDbfsFileUploadedAndAvailableAsync(_jarFile, rawBytesLength);
if (uploadedOk)
{
var runId = await SubmitJarJobAsync(_jarFile);
if(!runId.HasValue)
{
IsBusy = false;
_messageBoxService.ShowError(this.Status = $"Looks like there was a problem with calling Spark API '2.0/jobs/runs/submit'");
}
else
{
await PollForRunIdAsync(runId.Value);
}
}
else
{
IsBusy = false;
_messageBoxService.ShowError("Looks like the Jar file did not upload ok....Boo");
}
}
}
catch (Exception ex)
{
_messageBoxService.ShowError(ex.Message);
}
finally
{
IsBusy = false;
}
return Task.FromResult<object>(null);
}
private async Task<bool> IsDbfsFileUploadedAndAvailableAsync(FileInfo dbfsFile, int rawBytesLength)
{
bool fileUploadOk = false;
int maxNumberOfAttemptsAllowed = 10;
int numberOfAttempts = 0;
while (!fileUploadOk || (numberOfAttempts == maxNumberOfAttemptsAllowed))
{
var response = await _databricksWebApiClient.DbfsListAsync();
fileUploadOk = response.files.Any(x =>
x.file_size == rawBytesLength &&
x.is_dir == false &&
x.path == $@"/{dbfsFile.Name}"
);
numberOfAttempts++;
this.Status = $"Checking that Jar has been uploaded ok.\r\nAttempt {numberOfAttempts} out of {maxNumberOfAttemptsAllowed}";
await Task.Delay(500);
}
return fileUploadOk;
}
private async Task<int?> SubmitJarJobAsync(FileInfo dbfsFile)
{
this.Status = $"Creating the Spark job using '2.0/jobs/runs/submit'";
var datePart = DateTime.Now.ToShortDateString().Replace("/", "");
var timePart = DateTime.Now.ToShortTimeString().Replace(":", "");
var request = new RunsSubmitJarTaskRequest()
{
run_name = $"JobsPickAndRunJarViewModel_{datePart}_{timePart}",
new_cluster = new NewCluster
{
spark_version = "4.0.x-scala2.11",
node_type_id = "Standard_F4s",
num_workers = 2
},
libraries = new List<Library>
{
new Library { jar = $"dbfs:/{dbfsFile.Name}"}
},
timeout_seconds = 3600,
spark_jar_task = new SparkJarTask
{
main_class_name = "SparkApp",
parameters = new List<string>() { "10" }
}
};
var response = await _databricksWebApiClient.JobsRunsSubmitJarTaskAsync(request);
return response.RunId;
}
private async Task PollForRunIdAsync(int runId)
{
_watch.Reset();
_watch.Start();
while (_isPolling)
{
var response = await _databricksWebApiClient.JobsRunsGetAsync(runId);
JobsJson = JsonConvert.SerializeObject(response, Formatting.Indented);
var state = response.state;
this.Status = "Job not complete polling for completion.\r\n" +
$"Job has been running for {_watch.Elapsed.Seconds} seconds";
try
{
if (!string.IsNullOrEmpty(state.result_state))
{
_isPolling = false;
IsBusy = false;
_messageBoxService.ShowInformation(
$"Job finnished with Status : {state.result_state}");
}
else
{
switch (state.life_cycle_state)
{
case "TERMINATING":
case "RUNNING":
case "PENDING":
break;
case "SKIPPED":
case "TERMINATED":
case "INTERNAL_ERROR":
_isPolling = false;
IsBusy = false;
break;
}
}
}
finally
{
if (_isPolling)
{
await Task.Delay(5000);
}
}
}
}
}
}
Where we use this helper class to do the actual upload to Dbfs
using SAS.Spark.Runner.REST.DataBricks;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
namespace SAS.Spark.Runner.Services
{
public class DataBricksFileUploadService : IDataBricksFileUploadService
{
private IDatabricksWebApiClient _databricksWebApiClient;
public DataBricksFileUploadService(IDatabricksWebApiClient databricksWebApiClient)
{
_databricksWebApiClient = databricksWebApiClient;
}
public async Task UploadFileAsync(FileInfo file, int rawBytesLength,
Action<string> statusCallback, string path = "")
{
var dbfsPath = $"/{file.Name}";
statusCallback("Creating DBFS file");
var dbfsCreateResponse = await _databricksWebApiClient.DbfsCreateAsync(
new DatabricksDbfsCreateRequest
{
overwrite = true,
path = dbfsPath
});
FileStream fileStream = new FileStream(file.FullName, FileMode.Open, FileAccess.Read);
var oneMegaByte = 1 << 20;
byte[] buffer = new byte[oneMegaByte];
int bytesRead = 0;
int totalBytesSoFar = 0;
while ((bytesRead = fileStream.Read(buffer, 0, buffer.Length)) != 0)
{
totalBytesSoFar += bytesRead;
statusCallback(
$"Uploaded {FormatAsNumeric(totalBytesSoFar)} " +
$"out of {FormatAsNumeric(rawBytesLength)} bytes to DBFS");
var base64EncodedData = Convert.ToBase64String(buffer.Take(bytesRead).ToArray());
await _databricksWebApiClient.DbfsAddBlockAsync(
new DatabricksDbfsAddBlockRequest
{
data = base64EncodedData,
handle = dbfsCreateResponse.Handle
});
}
fileStream.Close();
statusCallback($"Finalising write to DBFS file");
await _databricksWebApiClient.DbfsCloseAsync(
new DatabricksDbfsCloseRequest
{
handle = dbfsCreateResponse.Handle
});
}
private string FormatAsNumeric(int byteLength)
{
return byteLength.ToString("###,###,###");
}
}
}
And just for completeness here is the set of REST APIs that make the 2 proceeded code snippets work
using System;
using System.Configuration;
using System.IO;
using System.Threading.Tasks;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using RestSharp;
using SAS.Spark.Runner.REST.DataBricks.Requests;
using SAS.Spark.Runner.REST.DataBricks.Responses;
using RestRequest = RestSharp.Serializers.Newtonsoft.Json.RestRequest;
namespace SAS.Spark.Runner.REST.DataBricks
{
public class DatabricksWebApiClient : IDatabricksWebApiClient
{
private readonly string _baseUrl;
private readonly string _authHeader;
private readonly RestClient _client;
public DatabricksWebApiClient()
{
_baseUrl = ConfigurationManager.AppSettings["BaseUrl"];
_authHeader = Base64Encode(App.AccessToken);
_client = new RestClient(_baseUrl);
}
public async Task<DatabricksRunNowResponse> JobsRunsSubmitJarTaskAsync(
RunsSubmitJarTaskRequest runsSubmitJarTaskRequest)
{
var request = new RestRequest("2.0/jobs/runs/submit", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(runsSubmitJarTaskRequest);
var response = await _client.ExecuteTaskAsync<DatabricksRunNowResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DatabricksRunNowResponse>(response.Content);
return dbResponse;
}
public async Task<DbfsListResponse> DbfsListAsync()
{
var request = new RestRequest("api/2.0/dbfs/list", Method.GET);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddQueryParameter("path", "/");
var response = await _client.ExecuteTaskAsync<DbfsListResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DbfsListResponse>(response.Content);
return dbResponse;
}
public async Task<JObject> DbfsPutAsync(FileInfo file)
{
var request = new RestRequest("api/2.0/dbfs/put", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddFile("back", file.FullName);
request.AddHeader("Content -Type", "multipart/form-data");
var response = await _client.ExecuteTaskAsync(request);
JObject responseContent = JObject.Parse(response.Content);
return responseContent;
}
public async Task<DatabricksDbfsCreateResponse> DbfsCreateAsync(DatabricksDbfsCreateRequest dbfsRequest)
{
var request = new RestRequest("api/2.0/dbfs/create", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(dbfsRequest);
var response = await _client.ExecuteTaskAsync<DatabricksDbfsCreateResponse>(request);
var dbResponse = JsonConvert.DeserializeObject<DatabricksDbfsCreateResponse>(response.Content);
return dbResponse;
}
public async Task<JObject> DbfsAddBlockAsync(DatabricksDbfsAddBlockRequest dbfsRequest)
{
var request = new RestRequest("api/2.0/dbfs/add-block", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(dbfsRequest);
var response = await _client.ExecuteTaskAsync(request);
JObject responseContent = JObject.Parse(response.Content);
return responseContent;
}
public async Task<JObject> DbfsCloseAsync(DatabricksDbfsCloseRequest dbfsRequest)
{
var request = new RestRequest("api/2.0/dbfs/close", Method.POST);
request.AddHeader("Authorization", $"Basic {_authHeader}");
request.AddJsonBody(dbfsRequest);
var response = await _client.ExecuteTaskAsync(request);
JObject responseContent = JObject.Parse(response.Content);
return responseContent;
}
private static string Base64Encode(string plainText)
{
var plainTextBytes = System.Text.Encoding.UTF8.GetBytes(plainText);
return Convert.ToBase64String(plainTextBytes);
}
}
}
As I say this is the most complex of all of the APIs I chose to look at. In
reality you would probably not kick a Databricks
job off from a UI. You might use a REST API of your own, which could delegate
off to some Job manager like
https://www.hangfire.io/ which would obviously still have to do the polling
part for you.
With all that in place you should be able to pick the JAR from the UI, and
submit it, watch it run and see the logs from the Databricks
web UI for the run.
I have to say using Apache
Spark / Databricks is an
absolute dream. Databricks have just
nailed it, it's just what was needed, its awesome what you can do with it.
Being able to spin up a cluster on demand that runs a job and is destroyed after
the job run (to save the idle costs) is just frickin great.
I urge you to give it a look, I think you will love it

