This article has been divided into the following high level sections:
This article highlights the need for performance testing and how to do it easily, accurately using simple JUnit and maven based Open Source Library. What problems we face typically during the load and stress testing of an application and how we can overcome these issues and make the performance-testing part of the CI build pipeline.
Sometimes, we tend to think that performance testing is not part of the development process. This is probably due to no stories getting created for this, during the usual development sprints. This means the important aspect of a product or service APIs is not not taken care of. But that's not the point, the point is why do we think that it should not be part of the usual development cycle ? or...
Why do we keep this towards the end of the project cycle?
Also to add more ground to the above thinking, there are no straight forward approaches to doing performance testing like we do unit testing or feature/component testing or e2e integration testing or consumer-contract testing. Then the developers or the performance-testers (sometimes a specialized team) are asked to choose a standalone tool from the market place and produce some fancy reports on performance testing, share those reports with business or technology team.
That means it is done in isolation and sometimes after or towards the end of the development sprints, approaching the production release date. Hence, the importance of this testing is missed out to provide room for improvement or fixing of the potential issues in the product. This answers the first question "why".
Ideally, to make it part of the usual development cycle:
the performance testing should be part of the CI build.
And to make it part of the CI build, it has to be easy enough to write/change/share the tests for developers or the performance-testers.
The point is how do we get a useful statistics easily understandable by the developers or, how to fix the issues that arise from load/stress/capacity testing or:
how do we get a continuous feedback from the CI build?
In the traditional approach, too much time is spent understanding the tool and making the tool work due to some are not IDE friendly, i.e., not even maven/JUnit based for that matter.
Some challenges like pointing your performance-testing tool to anywhere in the tech-stack is not an easy or straight forward task, e.g., pointing to a REST end point, SOAP end point, DB Server or KAFKA topics or a MQ end point like ActiveMQ/WMQ, SSL connections, connection via Corporate Proxy, etc.
This makes it a bit difficult to isolate the issues that your application APIs are performing very well and only the downstream systems have the issues. Let's explain what it means:
For example:
You just tested your GET API's performance, pointing to the URL, e.g. /api/v1/id-checks/131001 using the standalone tool and found that the response delay is more, than invoking the same API for a single time. Then you (as a developer) tends to blame it on the DB or the MQ topics, e.g., giving a reason that Oracle DB server is pretty slow while handling the parallel loads. But how do you produce the evidences to support your argument that your APIs are not slow?
Now, you wish you could have a mechanism or tool to isolate this issue from your application, by pointing your performance-test tool directly to the DB or KAFKA-Topics etc, because (as a developer) you know -- which SQL queries are fired to the DB to fetch the result or you know the topic names from which you can directly fetch the data bypassing the application API processing layer, which could prove your point meaningfully as well as produce evidences.
To achieve these steps should be actually very easy as you already have your existing JUnit tests, integration-tests, etc. doing the same stuff, on a daily basis (actually, every CI build is doing this). But it is sometimes difficult to do this using a standalone or market-place performance tool as:
you haven't found a way to reuse your existing tests to generate load/stress.
And/Or it is not flexible enough to feed these existing tests to the tool(s) you have chosen. So you lose interest or didn't have much time to spike it in the sprint, and then, you skip this aspect of testing, passing the blame to the downstream systems or to the tool.
Ideally, you need a custom JUnit load runner which could easily enable you to reuse your existing JUnit tests (e2e integration tests or feature tests or component tests, as most of them use JUnit or TestNG behind the scene) to generate load or stress (Read here the difference between load vs stress aka horizontal load vs vertical load).
The load runner ideally should look like below which could solve the purpose:
@LoadWith("your_load_config.properties")
@TestMapping(testClass = YourExistingEndPointTest.class, testMethod = "aTest")
@RunWith(YourLoadRunner.class)
public class LoadTest {
}
where your_load_config.properties should hold the below properties:
number.of.parallel.users=50
users.to.be.ramped.up.in.seconds=50
repeat.this.loop.times=2
where you want 50 users to be ramped up in 50 seconds (each user firing tests in 1 sec gap) and this to be run twice (loop=2) i.e., total 100 parallel users will fire requests, each approximately in 1 second gap.
and @TestMapping means:
@TestMapping(testClass = YourExistingEndPointTest.class, testMethod = "aTest")
Your aTest method of YourExistingEndPointTestabove should have the required assertions to match the actual result received vs expected result.
Once the load run gets completed, you probably would need a statistics precisely like below:
| Total number of tests fired | 100 |
| Total number of tests passed | 90 |
| Total number of tests failed | 10 |
| Average delay between requests(in sec) | 1 |
| Average response time delay(in sec) | 5 |
and ideally much more statistics could be drawn on demand, provided your YourLoadRunner could produce a CSV/SpreadSheet with below kind of data (or more):
| TestClassName | TestMethod | UniqueTestId | RequestTimeStamp | ResponseDelay | ResponseTimeStamp | Result |
YourExistingTest | aTest | test-id-001 | 2018-06-09T21:31:38.695 | 165 | 2018-06-09T21:31:38.860 | PASSED |
YourExistingTest | aTest | test-id-002 | 2018-06-09T21:31:39.695 | 169 | 2018-06-09T21:31:39.864 | FAILED |
Of course, these are basics and you should be able do all this testing using any chosen tools.
But what if you want to fire different kind of requests for each user concurrently?
and what about:
- One of your users wants to fire POST, then GET?
- Another user keeps on firing POST > then GET > then PUT > then GET to verify all CRUD operation going well or not?
- Another user dynamically changes the payload everytime firing a request?
- And so on... every scenario with asserting each outcome of the test?
- What if you want to gradually increase or decrease the load on the application under test ?
- One user generating stress and another generating load, both are in parallel ?
Now you definitely need a mechanism to reuse your existing tests as you might be already testing these scenarios in your regular e2e testing (sequentially, but not in parallel).
So you might need a junit runner like below which could alleviate the pain of redoing the same things again.
Recently, while carrying out performance testing, my team came across this Open Source maven lib called ZeroCode (See README on GitHub) which provides the handy JUnit load runners for load testing, which made the performance testing an effortless job. We came up with many scenarios creatively and were able to succesfully load-tests our application. And of course, we kept on adding these tests to our load-regression pack ready for CI build at the same time. How nice was that!
That means simply, we were able to map our existing JUnit tests to the load runner.
Basically, we combined these two libraries, i.e., Junit and Zerocode to generate load/stress:
- JUnit (very popular open source and commonly used in Java community)
- Zerocode (new and gaining popularity due to easy assertions for BDD/TDD automation)
See the basic examples of:
- For sample performance testing, browse the maven performance-test project
- Download(zip) and run the performance-tests, unzip and import as usual maven project
- Browse the helloworld project to learn the easy way of doing TDD/BDD automation
When you have the test run statistics generated in a CSV file, you can draw any charts or graphs using these data sets.
This particular library generates two kinds of reports (see sample load test reports here):
- CSV report (at target/zerocode-junit-granular-report.csv )
- Interactive fuzzy search and filter HTML report (at target/zerocode-junit-interactive-fuzzy-search.html)
Most importantly, there will be times when tests fail and we need to know the failures reason for that particular instance of the test case.
How to trace a failed test with the request/response/request-time/response-time/failure-reason?
You can trace a failed test by many parameters, but most easily is by its unique step-id. How?
In the CSV report (as well as HTML), you will find a column correlationId holding a unique ID corresponding to a test step for every run. Just pick this ID and search in the target/zerocode_rest_bdd_logs.log file, you will get the entire details with matching the TEST-STEP-CORRELATION-ID as below:
For example:
2018-06-13 21:55:39,865 [main] INFO
org.jsmart.zerocode.core.runner.ZeroCodeMultiStepsScenarioRunnerImpl -
--------- TEST-STEP-CORRELATION-ID: a0ce510c-1cfb-4fc5-81dd-17901c7e2f6d ---------
*requestTimeStamp:2018-06-13T21:55:39.071
step:get_user_details
url:https:
method:GET
request:
{ }
--------- TEST-STEP-CORRELATION-ID: a0ce510c-1cfb-4fc5-81dd-17901c7e2f6d ---------
Response:
{
"status" : 200,
"headers" : {
"Date" : [ [ "Wed, 13 Jun 2018 20:55:39 GMT" ] ],
"Server" : [ [ "GitHub.com" ] ],
"Transfer-Encoding" : [ [ "chunked" ] ],
"X-RateLimit-Limit" : [ [ "60" ] ],
"Vary" : [ [ "Accept" ] ]
"Status" : [ [ "200 OK" ] ]
},
"body" : {
"login" : "octocat",
"id" : 583231,
"updated_at" : "2018-05-23T04:11:38Z"
}
}
*responseTimeStamp:2018-06-13T21:55:39.849
*Response delay:778.0 milli-secs
---------> Assertion: <----------
{
"status" : 200,
"body" : {
"login" : "octocat-CRAZY",
"id" : 583231,
"type" : "User"
}
}
-done-
java.lang.RuntimeException: Assertion failed for :-
[GIVEN-the GitHub REST end point, WHEN-I invoke GET, THEN-I will receive the 200 status with body]
|
|
+---Step --> [get_user_details]
Failures:
---------
Assertion path '$.body.login' with actual value 'octocat'
did not match the expected value 'octocat-CRAZY'
and a throughput results can be drawn as below sample:
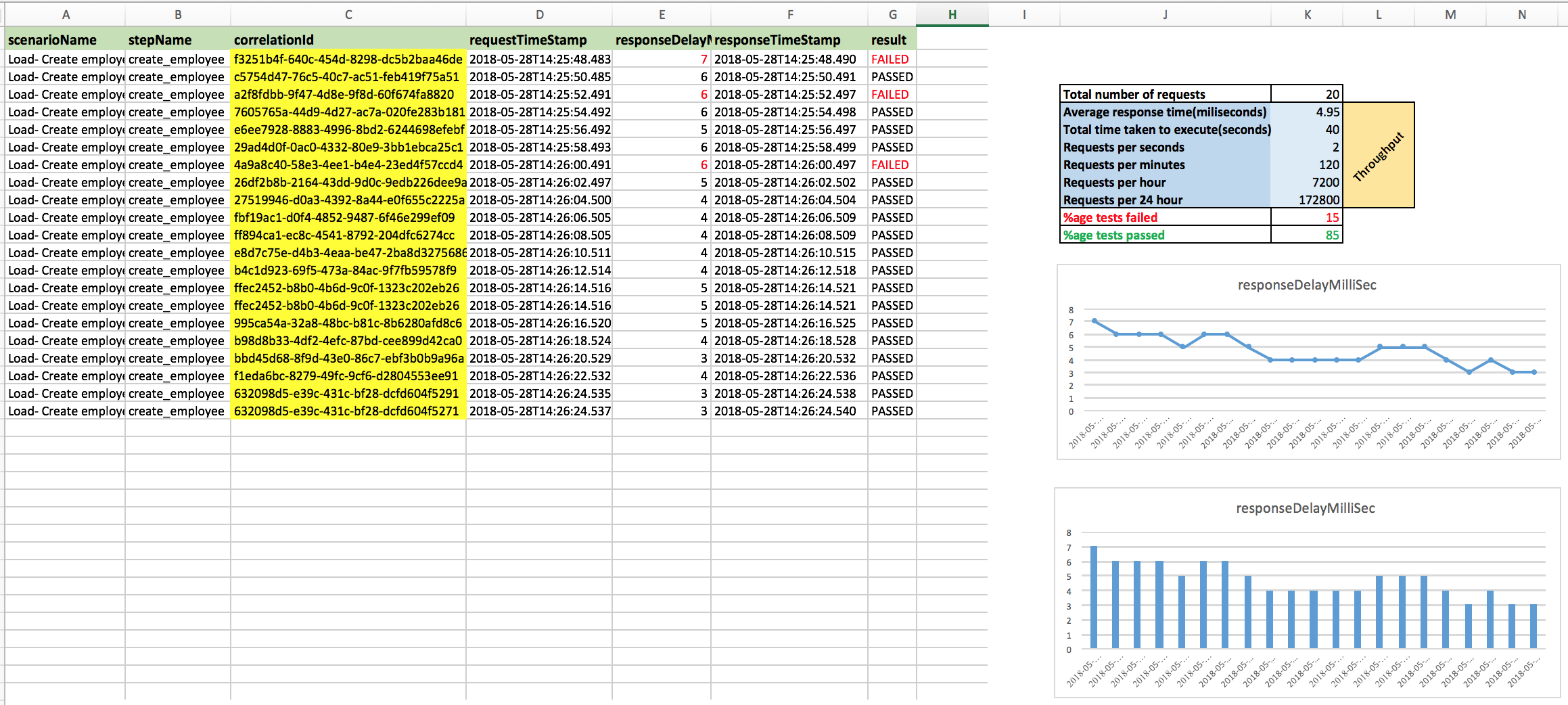
and of course, you can draw Line Graphs, Pi-Charts, 3D Charts, etc. using Microsoft Excel or any other handy tools (and much more stuff depending upon your business needs).
Earlier, the library used to give single load runner, but one can manipulate the payload keeping the structure intact. But with recent versions (v1.2.2 onwards), one can load multiple parallel users with each payload dynamically changing. This helps in mimicking production like scenarios.

