SQL Server Database Engine is a general-purpose multi-model Database Engine that enables you to combine the classic relational concepts with NoSQL concepts such as JSON documents. In this article, you will see some use cases that describe how to combine JSON with relational data and when to use it.
Background
In this article, we will see what our good friend JSON can do in SQL Server Database Engine. Since today is Friday the 13th, this is may be the right time to talk about this topic; although, I will not talk about Jason Voorhees 😊.
One common misconception is that SQL Server is just a relational database engine where you should put your highly normalized data in tables. Some developers even believe that this is an old concept suitable for legacy apps that don’t follow modern patterns like NoSQL. The fact is that currently classic pure relational databases don’t exist. If you look at the SQL Server, PostgreSQL, MySQL, Oracle and other “classic database systems”, you will see that they are supporting a variety of NoSQL concepts such as JSON data. Having some kind of NoSQL support is a must-have for all modern databases and you would need to learn how to leverage this in your applications.
In this article, I will focus on SQL Server and Azure SQL Database – general-purpose multi-model databases that enable you to combine the classic relational concepts with NoSQL concepts such as JSON, XML, and Graphs. Unlike classic relational and NoSQL database, SQL Database does not force you to choose between these two concepts – it enables you to combine the best characteristics of relational and non-relational models on the different entities in the same database in order to create an optimal data model.
In this article, I will show you what you can do with JSON in SQL Server and Azure SQL Database (managed version of SQL Server hosed by Microsoft in Azure cloud). I will use term SQL Server Database Engine but note that everything applies both to on-premises version (SQL Server 2016+) and Azure cloud version (Azure SQL Database).
JSON in SQL Server Database Engine
SQL Server Database Engine enables you to store JSON documents in database, parse JSON documents and convert them into relational data (tables) or take your relational data. SQL Server Database Engine provides functions and operators that enable you to work with JSON as any other type in SQL Server and use it in any T-SQL type of query.
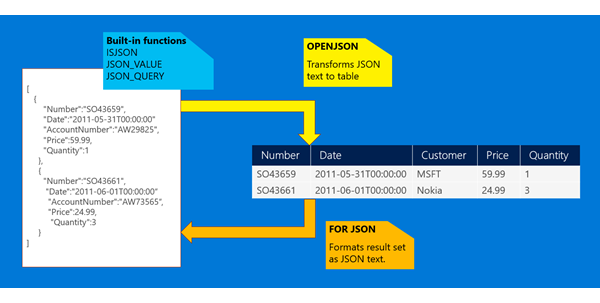
We have several JSON functions that you can use to take a value from a JSON text stored in some variable or column, and use it in any query as any other column. You can select values from JSON text, filter them, order results using JSON values, etc.
SELECT PersonID, FirstName, LastName,
JSON_VALUE(AdditionalInfo, '$.Title') Title,
JSON_VALUE(AdditionalInfo, '$.NameStyle') NameStyle,
JSON_VALUE(AdditionalInfo, '$.PaymentInfo.Salary') Salary,
JSON_QUERY(AdditionalInfo, '$.Skills') Skills
EmailAddresses
FROM Person
WHERE JSON_VALUE(AdditionalInfo, '$.Company') = @company
AND ISJSON(AdditionalInfo) > 0
ORDER BY JSON_VALUE(AdditionalInfo, '$.PaymentInfo.Salary')
One interesting advantage is that you can build any query with advanced SQL operators such as GROUP BY, HAVING, window aggregates on JSON documents - something that is not common even in specialized NoSQL databases that works with JSON documents.
OPENJSON function can take a JSON document and return all values as tabular result set. This is useful if you need to query JSON document or import it into a table.
SET @json =
N'{ "Title":"Mr",
"PaymentInfo":{"Salary":1500,"Type":"Weekly"},
"Company":"AdventureWorks",
"Skills":["SQL",".Net","C#"] }';
SELECT *
FROM OPENJSON(@json);
There is FOR JSON query clause that instructs Database Engine to return results formatted in JSON format instead of table format, and a set of JSON functions that parse JSON text and return either scalar values of tables out of the JSON text.
SELECT FirstName, LastName
FROM Person
FOR JSON PATH
The result of this query is a text in JSON format that represents the rows of the query result.
You can find more information about JSON support in SQL Server in my previous Friday 13th article.
In this article, I will talk more about use cases that show you when and how you can use JSON in database.
Tailor Complexity of Your Data Models
In the specialized database (relational or NoSQL), you usually need to make a design choice how to represent your data, and this decision is hard to change later.
Classic relational databases force you to create highly normalized data models where high-level concepts such as Customer, Order, or Invoice are physically decoupled from their related entities such as Customer emails, Customer phones, Product parts, Order Line Items, Invoice tags, etc. Normalized models require high granularity of entities because they are designed to support a large number of independent transactions that are updating both conceptual entities and their parts at the same time. This is good because breaking conceptual entities into the separate tables enables each transaction to update its own table without affecting others. The drawback of this approach is the fact that you need to get information from different tables to reconstruct one complex entity and its attributes, and also the fact that there is a risk of locks and even deadlocks if a transaction must atomically update several tables.
Classic document databases(NoSQL) merge the dependent entities into the main conceptual entities as aggregated parts of each primary entity with serialized collections and other complex objects. This way, you need single lookup to retrieve or update the entity and all related data. However, this model is not suitable if you have frequent updates of related data. In addition, if anyone asks you to create some report with grouping aggregations and complex calculations over document data or a more complex query that uses multiple different collections, you might feel the pain.
The ideal model depends on the nature of your data and workload, so you need to consider how the data will be used when you are choosing between normalization and de-normalization. The reality is that in some cases, you might need to organize your data in relational/normalized structure, but for some of the information you might want to leverage some NoSQL concepts. Modern multi-model databases that support both relational and NoSQL concepts such as SQL Server and Azure SQL database, enable you to do this.
There is no "ideal" model and we cannot say that relational/normalized models is always better than de-normalized/NoSQL model or vice versa. There are particular use cases where relational model would fit better to your needs and other where de-normalized model is better approach. The important thing is that you need to identify these cases and select optimal model in every particular scenario. Multi-model databases enable you to make these kind of decisions without migrating data from one database system to another (for example from relational database to NoSQL or vice versa) just to redesign some part. In multi-model databases such as SQL Server and Azure SQL Database, you can make these decisions for every part of database schema and combine the best of both worlds where appropriate.
The following figure shows one normalized and equivalent de-normalized model using JSON collections for dependent entities:

On the left side, you see one classic normalized schema, which is fine and properly designed. However, in some cases, normalized model might increase complexity:
- If you need to return or update entire
Customer, Order or Invoice object, you would need to run several queries. This is not only programming inconvenience - for every logical object, you would need one logical read/write for primary entity, and at least one logical read for every collection of dependent entities. - If you want to move you data to other system using transactional replication or some exports, you will need to setup replication and export data from several tables, handle errors if some of the tables fail, etc.
Many developers and architects are in temptation to switch to NoSQL where they will have three collections (Customer, Order, Invoice) with single read/write operation for every logical entity, simpler exports and replication. However, in that case, you are loosing some benefits of relational databases that you always use such as referential integrity (database ensure that you will not have dirty data such as Invoices without Customers), and in most NoSQL databases is not easy to create cross-collection queries.
SQL Server Database Engine enables you to mix these concepts where appropriate, and to have a set of standard relational tables with foreign keys and referential integrity, and complex data such as lists, arrays, collections, and dictionaries formatted as JSON or XML, spatial data or even graph relationships between the tables. SQL Server and Azure SQL Database enable you to fine tune design of your data model and use the most appropriate data structures depending on your use case.
If you have data models where related data are not frequently updated, you can store related entities in table cells as sub-collection formatted as JSON and combine simplicity of NoSQL design with the power of querying with SQL.
One of the most important things is that you can change your design without migrating from relational system to NoSQL or vice versa. If you see that your JSON collection is frequently updated and that it would be better to represent it as sub-table, you can use OPENJSON function that parses JSON collection stored in some table cell, transform it to table format and load it in sub-table. Also, if you see that your sub-table is not updated frequently, but you need additional queries to always read it together with the primary table, you can use FOR JSON to de-normalize it and put the content in some column in primary table. This way, you have full flexibility to migrate back and forward and tailor your models to your needs.
Note: In most of the cases, de-normalization and transforming normalized relational model to de-normalized model will not match performance of the original normalized model. The optimal performance for data access is direct data access provided by relational/normalized model that cannot be compared with parsing of semi-structured data. The only case when you might get performance benefit is the case where you have many logical reads/writes in the transactions that need to access several tables to gather logical entity or update all parts of the entities that are divided per different tables. In NoSQL case, this would be read/write of a single row in a single table. This is specific scenario that you need to identify, otherwise you might get unexpected performance degradations (probably the same degradation that you will get if you just switch to NoSQL because you are redesigning classic relational workload/model into NoSQL model that is not appropriate for your use case).
Build Your ViewModel in Database
One of the biggest pain-points in highly normalized database models is that some time you need to execute 10 queries to gather information from different tables just to gather all information necessary to reconstruct a single entity. Let’s look at the following simple database schema that represents people with their email addresses and phone numbers:

If you would need to get the information about the person you would need to send one query to read Person row, another to get email addresses using PersonID, and third to get the Phone numbers by joining PersonPhone and PersonPhoneNumberType. The queries might get complicated if you are searching for people and getting the related information for every person that satisfies search criteria. Even if you don’t see how complex this is due to some ORM that translates your LINQ/Lazy loading actions to queries, you might be surprised when you see what set of SQL queries is generated to execute this operation.
With JSON and de-normalization, you can get the People rows that you need with all related information about related email in phones as collection per row:
| ID | FirstName | LastName | Emails | Phones |
| 274
| Stephen
| Jiang
|
[{"EmailAddress":
"stephen0@adventure-works.com"}
,{"EmailAddress":
"stephen.jiang@outlook.com"}]
|
[{"PhoneNumber":"112-555-6207″,
"PhoneNumberType":"Work"},
{"PhoneNumber":"238-555-0197″,
"PhoneNumberType":"Cell"},
{"PhoneNumber":"817-555-1797″,
"PhoneNumberType":"Home"}]
|
| 275
| John
| Finley
|
[{"EmailAddress":
"johnf@adventure-works.com"}]
|
[{"PhoneNumber":"112-555-6207″,
"PhoneNumberType":"Work"}]
|
You can use the JSON functions to get this result out of the relational model. External applications that accept these result can easily "materialize" SQL results as DTO object by deserializing collections form JSON format to collection of objects (for example, using Json.NET - Newtonsoft if you are using .NET in application layer). Take a look at this article to see how to serialize and deserialize JSON collections returned by query using Entity Framework.
The main question is how to return JSON collection for dependent collections of sub-objects?
One option would be to de-normalize emails and phones and store them as additional columns in Person table. You should use this approach if you know that emails and phones are not frequently updated and if you know that you will always read collection of emails/phones as one chunk. In that case, you could move your tables into columns using the query like:
UPDATE Person
SET Emails = (SELECT EmailAddress
FROM EmailAddresses e
WHERE e. BusinessEntityID = Person. BusinessEntityID
FOR JSON PATH)
Now, if you select rows from Person table, you would get JSON collections of emails and phones as any other column.
Another option would be to leave emails and phones in separate tables, and to “attach” them to every Person row at query time using column sub-query (user defined expressions in SQL Server terminology):
SELECT Person.Person.BusinessEntityID AS ID, Person.Person.FirstName, _
Person.Person.LastName,
Emails = (SELECT Person.EmailAddress.EmailAddress
FROM Person.EmailAddress
WHERE Person.Person.BusinessEntityID = Person.EmailAddress.BusinessEntityID
FOR JSON PATH),
Phones = (SELECT Person.PersonPhone.PhoneNumber, _
Person.PhoneNumberType.Name AS PhoneNumberType
FROM Person.PersonPhone
INNER JOIN Person.PhoneNumberType
ON Person.PersonPhone.PhoneNumberTypeID = _
Person.PhoneNumberType.PhoneNumberTypeID
WHERE Person.Person.BusinessEntityID = Person.PersonPhone.BusinessEntityID
FOR JSON PATH)
FROM Person.Person
WHERE <<condition>>
Your application that takes the results of this query will get one row-per person and collection of phones and emails without any notion that under the hood, there are some relational table structures.
If you are using this result in some Single-page application that expects JSON as response, you can put FOR JSON clause on the main query and format everything as one big JSON text that could be sent to the client.
Another interesting case where you can leverage JSON is reducing complexity of your code that returns data from the database. Imagine that you have a report or some data that you should show in browser.
Usually, you need to use some ORM that read data from the tables in some model objects, and then you have some view model classes that are used to transform model into the data structures that client apps understand. Then you have some component that converts these view models into JSON responses that are sent to the clients.
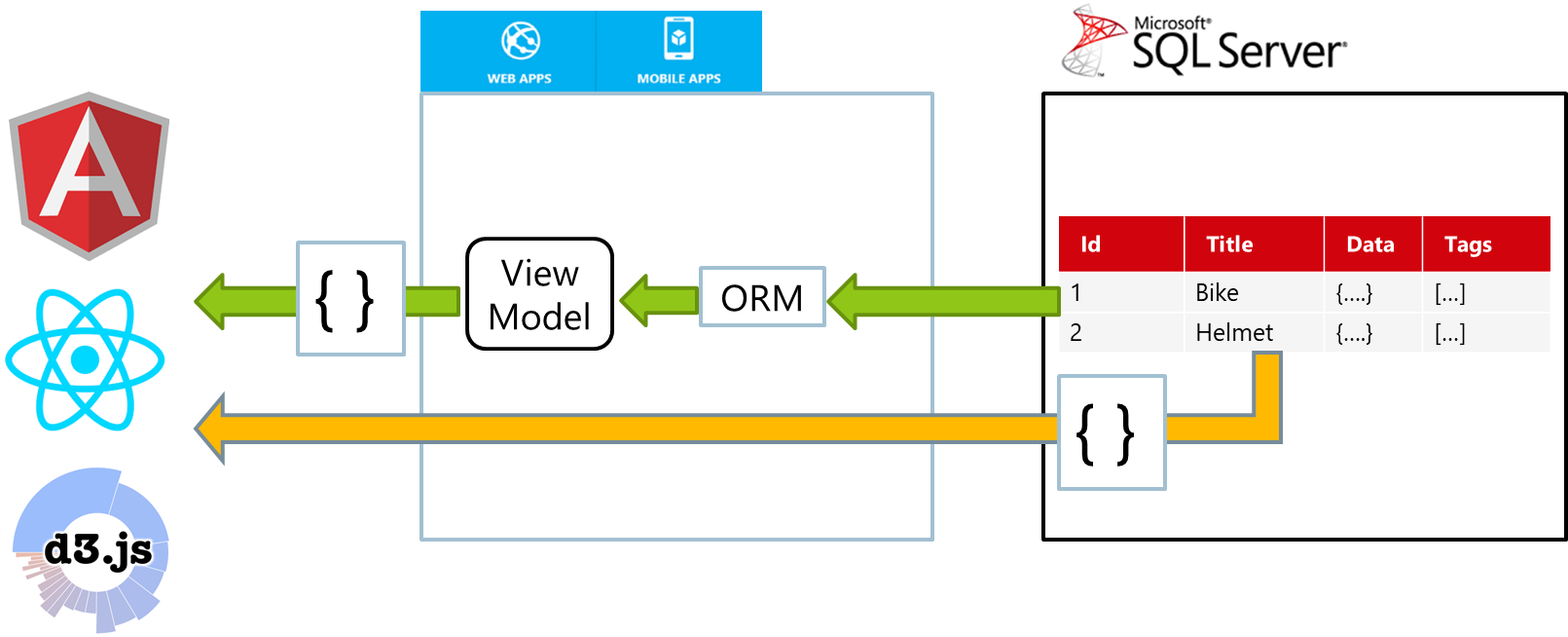
With FOR JSON clause in SQL Database, you can execute any query, ask SQL server to return results formatted as JSON and directly send the result to your clients. This might dramatically reduce the amount of code that you need to write as well as testing of every layer in the architecture, because you need one SQL query with FOR JSON clause per REST API call.
Simplify Development of Data-centric REST API
We need to remember that JSON is Web concept and not some database storage optimization format. It is perfect for JavaScript code that communicates with the web servers using AJAX request. This is a primary communication pattern choices for communication in every modern web app.
Single-page applications represent the modern architecture for building web applications. They are based on the rich JavaScript application frameworks and libraries, and have a lot of client-side JavaScript code that is executing in the web browsers. Single-page applications communicate with backend systems via HTTP/AJAX requests that retrieve or send JSON messages to some REST APIs, which gets or stores data in the database. One of the main difficulties in web development is transformation of relation data into JSON messages and vice versa. In classic REST API, you need to get the data from the database and transform it to JSON message that will be sent to your single-page application.
FOR JSON clause and OPENJSON function enable you to easily transform relational data stored in tables to JSON and to parse JSON text coming from the single-page applications into SQL database. This might be a perfect tool for building REST API for single page apps that communicate with backed system using JSON messages.
With JSON operators and functions, you can easily get the data from SQL tables or create complex reports using T-SQL, format results as JSON text and let REST API to return this text to some client-side app.
If you are using ASP.NET and you need to create a REST API endpoint that executes some query in database and returns result as JSON response, you can put something like this in the action method in your controller:
public async Task Report() {
await db.Sql("SELECT color AS x, AVG(price) AS y FROM product GROUP BY color FOR JSON PATH")
.Stream(Response.Body);
}
This action uses helper functions from Belgrade SqlClient Data Access library that execute a T-SQL query directly in your database and stream the result into your output stream (in this case HttpResponse body).
If you are using Node.JS and express, you can use something like:
router.get('/Report', function (req, res) {
req.sql("select Color AS x, AVG(price) AS y FROM Product GROUP BY color FOR JSON PATH")
.into(res, '[]');
});
See more details about building REST API for single page applications in this post, and an example that shows how to create REST API back-end to Angular application here.
Log Data Analysis
Applications and devices generate large volumes of logs, with information about what happened in the app, error details, etc. In many cases, log data is represented in JSON format. You can store your JSON logs in some cheap log storage such as files, but if you want to analyze plain text logs, you might need to deal with complex parsing and regular expressions. CSV or TSV is easy for parsing; however, they require a fixed set of columns. JSON is in many cases chosen as a format for logs with trade-off between availability of parsing tools and flexibility of structure.
Telemetry data ends-up into log files that are stored on file systems, Azure Blob Storage, Hadoop file system, etc. These storage systems represent an excellent choice for storing log data because their price is lower than Azure SQL or Cosmos DB, and generally, it is faster to write log entries to the plain files because there is no additional overhead for data processing like in relational or even NoSQL databases. However, they represent cold storage with very limited query and analytic capabilities.
If you need to have a hot log data that you can quickly and easily analyze, SQL Server Database Engine enables you to load log files formatted as JSON from the cold storage, query and analyze log data using standard T-SQL language.
First, you would need to create a table where you will store your hot logs:
CREATE TABLE WebLogs (
_id bigint IDENTITY,
data nvarchar(max),
INDEX cci CLUSTERED COLUMNSTORE
)
In this simplified example, I have an equivalent of classic NoSQL collection with one data column that will contain single log record. You can also add more columns like type, date when log entry is added but this depends on your use case. Adding relational columns is useful if you need to filter data using these columns because it might be much faster than filtering by properties in JSON column.
Note the CLUSTERED COLUMNSTORE index in the table definition – this is an index that you should probably put on the tables that contain a lot of JSON database because it can perform high compression of data and decrease your storage requirements up to 20x. In addition, tables with COLUMNSTORE indexes are optimized for analytic queries so they might be a good choice if you need to analyze your logs.
If you are storing logs on file shares or Azure Blob storage, you can import files using BULK IMPORT SQL command directly into the target table in SQL Database:
BULK INSERT WebLogs
FROM 'data/log-2018-07-13.json'
WITH ( DATA_SOURCE = 'MyAzureBlobStorageWebLogs');
In this example, log entries are imported as one JSON log entry per row.
Once you load data in SQL tables, you can analyze it using standard T-SQL language. An example of T-SQL query that finds top 10 IP addresses that have accessed the system in some date period is shown in the following example:
SELECT TOP 10 JSON_VALUE(data, '$.ip'), COUNT(*)
FROM WebLogs
WHERE CAST(JSON_VALUE(data, '$.date') AS date) BETWEEN @start AND @end
GROUP BY JSON_VALUE(data, '$.ip')
ORDER BY COUNT(*) DESC
SQL Server and Azure SQL Database represent good choice for loading hot logging data from cold storage in order to provide fast and rich analytics using T-SQL and wide ecosystem of tools that work with SQL Server and Azure SQL Database.
Internet of Things Data Analysis
Internet of things (IoT) might be seen as a special case of logging data where you need to store and analyze a lot of telemetry data sent from various devices. IoT use cases commonly share some patterns in how they ingest, process, and store data. First, these systems need to ingest bursts of data from device sensors of various locales. Next, these systems process and analyze streaming data to derive real-time insights. The data is stored in some persistent storage for further analysis.
In the following picture, you can see IoT pipeline where IoT devices send data to Azure Iot Hub, and finally IoT data lands into Azure SQL Database:

In IoT pipelines, we can notice two major paths from the source of data to the storage:
- Hot path where the most recent data that is coming from sensors need to be placed in storage layer as soon as possible. In this example, events are sent via Azure Event Hub and Azure Functions into Azure SQL Database (assumption is that this is lambda architecture implemented on Azure cloud platform).
- Cold path where IoT data is stored on some low-price storage layer, such as Azure Blob Storage. Cold data can be loaded later in some system for analysis to query the data.
If you are using Azure cloud for IoT solutions, there are a variety of options for storing IoT data, such as:
- Azure Blob storage if you need to store a large amount of cold data with a low-prices. Stored IoT data can be on-demand loaded into some Azure SQL Database or Azure SQL Datawarehouse to run analytic using standard queries or analyzed using some Azure Machine Learning service.
- Azure SQL Database or Azure SQL Datawarehouse if you can parse incoming data and store it in the relational format.
- Azure SQL Database if you need to store semi-structured data formatted as JSON and you need to correlate IoT information with some existing relational data.
- Azure SQL Database or Azure Cosmos DB if you need to store semi-structured data formatted as JSON.
If you store IoT data in Azure SQL Database, you can use built-in native functions that enable you to parse and analyze IoT data collected from the devices.
In addition, you can easily build telemetry pipeline where you have Azure Event Hub, Azure Event Grid, or Azure IoT Hub that is accepting data from your IoT devices, Azure Function where you can place a simple code that just accepts the JSON message from Azure Event Hub and calls a SQL procedure that accepts this JSON message, and finally SQL procedure that either store raw json message that can be processed or parse the json message when they enter the database and store the fields into the columns.

As an example, Azure Function that read JSON messages from Azure Event Hub and sends the message to Azure SQL Database is shown in the following code sample:
using System.Configuration;
using System.Data.SqlClient;
using Belgrade.SqlClient.SqlDb;
public static async void Run(string myEventHubMessage, TraceWriter log)
{
if(String.IsNullOrWhiteSpace(myEventHubMessage))
return;
try{
string ConnString = ConfigurationManager.ConnectionStrings
["azure-db-connection"].ConnectionString;
var cmd = new Command(ConnString);
var sqlCmd = new SqlCommand("ImportEvents");
sqlCmd.CommandType = System.Data.CommandType.StoredProcedure;
sqlCmd.Parameters.AddWithValue("Events", myEventHubMessage);
await cmd.ExecuteNonQuery(sqlCmd);
} catch (Exception ex) {
log.Error($"C# Event Hub trigger function exception: {ex.Message}");
}
}
This is a fairly simple function and probably the only thing that you would need in order to bind your Event Hub service and database storage. When this function takes the JSON message as myEventHubMessage variable, it just passes it to the SQL procedure called ImportEvents.
In the procedure, you can choose whether you want to store JSON message as-is in the table row or parse it and break it into columns. The following simple implementation just inserts provided value in the table.
CREATE PROCEDURE dbo.ImportEvents @Events NVARCHAR(MAX)
AS BEGIN
INSERT INTO dbo.Events (Data)
VALUES( @Events);
END
Another implementation might parse incoming JSON message, take the properties and store them into the columns:
CREATE PROCEDURE dbo.ImportEvents @Events NVARCHAR(MAX)
AS BEGIN
INSERT INTO dbo.Events
SELECT *
FROM OPENJSON(@Events)
WITH ([eventId] int, [deviceId] int, [value] int, [timestamp] datetime2(7)))
END
The good thing in this approach is that you can easily change implementation of the schema that you use to store your IoT events, without affecting the rest of the pipeline.
You can find more information about this IoT scenario in this article.
Points of Interest
JSON support in relational databases might sometime open the world of NoSQL in your relational database. If you ever had a problem with complex schema and wanted to try to solve the problem with NoSQL database, but you could not migrate your system easily, JSON support in SQL database might enable you to combine the best concepts from NoSQL databases and relational world.
Next Steps
If you want to learn more about the JSON support in SQL Server/Azure SQL Database, I would recommend the following resources:
History
- 13th July, 2018: Initial version

