Introduction
Instead of matrices, quaternions are often used to represent the orientation of three-dimensional entities in games and simulations. Quaternions require only 4 floats as opposed to the 9 floats required by a 3x3 matrix. Quaternion multiplication also requires only 16 multiplications and 12 additions versus the 27 multiplications and 18 additions of matrix multiplication.
Despite these advantages, it can still be tricky to implement code for quaternion-based entities that maximizes time efficiency. In this article, we will take a look at how to achieve the most performance when using quaternions in real-time applications where performance is essential.
Vector Transformations
Although quaternion multiplications are relatively computationally inexpensive, the same does not go for quaternion transformations of 3D vectors. In this case, the equivalent matrix operation is actually cheaper to compute, requiring only 3 dot products for a total of 9 multiplications and 6 additions. Even an optimized version of the quaternion operation requires 2 cross products for a total of 15 multiplications and 8 additions. Because of this, many AI and gameplay programmers will maintain a separate copy of each entity’s orientation in matrix form as well as in quaternion form.
Let us consider a typical AI function called “updatePursuitAction” in which an AI entity must determine the direction from its location to the location of a target that it wants to pursue. It then alters its direction to intercept the target. This function is called every frame until the AI system decides the entity should switch to some other AI action. To determine direction we must transform the world-space vector between the entity and its target into the entity’s local space.
In the example code, we have two classes which implement the same AI function each in its own way. The FastGameEntity class implements it using a quaternion and the SlowGameEntity class implements it using a matrix represented as three separate 3D vectors corresponding to the 3 rows ( or columns if using column-major matrices ) of the equivalent matrix.
Listing 1.
virtual void FastGameEntity::updatePursuitAction( const D3DXVECTOR3 &targetPos )
{
D3DXVECTOR3 toTarget = targetPos - pos_;
D3DXQUATERNION conjQ;
D3DXQuaternionConjugate( &conjQ, &ori_ );
rotateVectorWithQuat( conjQ, toTarget );
}
virtual void SlowGameEntity::updatePursuitAction( const D3DXVECTOR3 &targetPos )
{
D3DXVECTOR3 worldToTarget = targetPos - pos_;
D3DXVECTOR3 localToTarget;
localToTarget.x = D3DXVec3Dot( &side_, &worldToTarget );
localToTarget.y = D3DXVec3Dot( &up_, &worldToTarget );
localToTarget.z = D3DXVec3Dot( &dir_, &worldToTarget );
}
For the FastGameEntity we can update its AI by simply calling the “updatePursuitAction” function with the current location of the target. For the SlowGameEntity we must also execute another function on every frame, the “UpdateRotation” function. This function converts the quaternion orientation of the entity into matrix form. This must be done in order to keep the matrix in sync with the quaternion ensuring both always represent the same orientation. This extra operation requires at least 12 more multiplications and 12 more additions.
Listing 2.
virtual void FastGameEntity::updateAI( )
{
D3DXVECTOR3 targetPos;
updatePursuitAction( targetPos );
}
virtual void SlowGameEntity::updateAI( )
{
D3DXVECTOR3 targetPos;
updatePursuitAction( targetPos );
UpdateRotation();
}
If we profile these functions in AMD CodeAnalyst, we see that the FastGameEntity version does in fact run faster than the SlowGameEntity version even though it is using the more expensive quaternion transformation. This is because the extra step of converting from a quaternion to a matrix wipes out any advantage the matrix transformation may have provided.
In Fig. 1 we see the profiler output with the functions called by FastGameEntity underlined in green and those by SlowGameEntity underlined in red. We can now see that more time is spent in the SlowGameEntity functions:
Fig. 1
CS:EIP,Symbol + Offset,64-bit,Timer samples,
"0x401c90","D3DXQuaternionConjugate","","2.2",
"0x4017b0","D3DXVec3Cross","","9.4",
"0x401b10","D3DXVec3Dot","","10.67",
"0x401780","D3DXVECTOR3::D3DXVECTOR3","","7.31",
"0x401ab0","D3DXVECTOR3::operator-","","13.92",
"0x403900","FastGameEntity::FastGameEntity","","0.12",
"0x401db0","FastGameEntity::updateAI","","0.12",
"0x401de0","FastGameEntity::updatePursuitAction","","0.12",
"0x4039d0","GameEntityBase::GameEntityBase","","15.89",
"0x401600","main","","0.23",
"0x403200","operator new","","0.12",
"0x4012f0","quatToMatrix","","25.17",
"0x4010e0","rotateVectorWithQuat","","10.21",
"0x403810","SlowGameEntity::SlowGameEntity","","0.23",
"0x4018c0","SlowGameEntity::updateAI","","0.12",
"0x401a40","SlowGameEntity::updatePursuitAction","","0.12",
Does this mean that we should never use matrix transformations when dealing with quaternion-based entities? No, because there are situations where they will yield better results for performance. In the AI example above, we only need to make one transformation per frame, but what if we need to make several thousand? Take for instance a mesh with thousands of vertices that need to be transformed by the entity’s current rotation. If this is done with quaternion operations it will require more computation than with matrices. So in this case it would make more sense to convert the quaternion into a matrix first, so all of the vertices can be transformed with the matrix.
In Listing. 3 we have two different versions of a “transformManyVertices” function, one which uses a quaternion and one which uses a matrix converted from the quaternion.
Listing 3.
virtual void SlowGameEntity::transformManyVertices( unsigned int numVerts )
{
D3DXVECTOR3 *vertices = new D3DXVECTOR3[ numVerts ];
D3DXVECTOR3 transformedVertex;
D3DXQUATERNION conjQ;
D3DXQuaternionConjugate( &conjQ, &ori_ );
for ( unsigned int i=0; i< numVerts; i++)
{
transformedVertex = vertices[i];
rotateVectorWithQuat( conjQ, transformedVertex );
}
delete [] vertices;
}
virtual void FastGameEntity::transformManyVertices( unsigned int numVerts )
{
UpdateRotation();
D3DXVECTOR3 *vertices = new D3DXVECTOR3[ numVerts ];
D3DXVECTOR3 col1( side_.x, up_.x, dir_.x );
D3DXVECTOR3 col2( side_.y, up_.y, dir_.y );
D3DXVECTOR3 col3( side_.z, up_.z, dir_.z );
for ( unsigned int i=0; i< numVerts; i++)
{
D3DXVECTOR3 transformedVertex;
transformedVertex.x = D3DXVec3Dot( &col1, &vertices[i] );
transformedVertex.y = D3DXVec3Dot( &col2, &vertices[i] );
transformedVertex.z = D3DXVec3Dot( &col3, &vertices[i] );
}
delete [] vertices;
}
If we profile this, we see that now the matrix version is faster than the quaternion version even though we must perform the extra step of converting to a matrix. So whether or not to use matrices versus quaternions depends on the functionality you are trying to implement. As always with optimization, we should use a profiler to determine what the real bottlenecks are in the code to determine what really needs to be optimized.
Fig. 2
CS:EIP,Symbol + Offset,64-bit,Timer samples,
"0x4018a0","`vector constructor iterator'","","0.12",
"0x4026f0","D3DXQUATERNION::D3DXQUATERNION","","0.64",
"0x401800","D3DXVec3Cross","","21.36",
"0x401b60","D3DXVec3Dot","","1.17",
"0x4017d0","D3DXVECTOR3::D3DXVECTOR3","","18.78",
"0x403c50","FastGameEntity::FastGameEntity","","0.18",
"0x401ea0","FastGameEntity::transformManyVertices","","0.23",
"0x403ca0","GameEntityBase::GameEntityBase","","8.07",
"0x401600","main","","0.06",
"0x403360","operator new","","0.06",
"0x4010e0","rotateVectorWithQuat","","47.63",
"0x403bf0","SlowGameEntity::SlowGameEntity","","0.12",
"0x401ba0","SlowGameEntity::transformManyVertices","","0.12",
Updating orientation
When it comes to changing the orientation of an entity, many AI and Gameplay programmers rely on Euler angles and the matrix form of the orientation to calculate the new orientation of the entity for each frame. This requires the new Euler angles to be converted into quaternion form before the entity is rendered and this operation is relatively expensive computationally. It requires the use of either lots of sines and cosines, or the multiplication of three quaternions which results in many multiplications and additions. How can we avoid this? Another alternative is to compute the angular motion of the object using angular velocities, one for each of the three axes of rotation. These velocities can be stored as a single 3D vector. This method has the advantage of requiring much less computation to update the orientation of the entity, needing only one quaternion multiplication with the velocity vector and a quaternion addition.
The SlowGameEntity class and the FastGameEntity class each have their own version of a “calcOrientation” function, which are shown in Listing. 4.
Listing 4.
virtual void calculateOrientation( float dt )
{
ori_ += ( (ori_ * angularVel_) * 0.5f * dt );
}
virtual void calculateOrientation( float dt )
{
D3DXQUATERNION tempQ;
quatFromEuler( tempQ, yaw_, pitch_, roll_ );
ori_ = tempQ * ori_;
}
Again looking at the profiler output, we see that the angular velocity method is slightly faster.
Fig. 3
CS:EIP,Symbol + Offset,64-bit,Timer samples,
"0x406eb8","_cos_pentium4","","1.32",
"0x407428","_sin_pentium4","","1.15",
"0x404410","calcAllEntitysOrientation<SlowGameEntity>","","0.33",
"0x405240","cos","","0.16",
"0x401980","cosf","","1.65",
"0x401870","D3DXQUATERNION::D3DXQUATERNION","","0.82",
"0x401ec0","D3DXQUATERNION::operator*","","0.16",
"0x402230","D3DXQUATERNION::operator*","","0.33",
"0x4021d0","D3DXQUATERNION::operator+=","","3.62",
"0x402170","FastGameEntity::calculateOrientation","","0.16",
"0x403c80","GameEntityBase::GameEntityBase","","23.39",
"0x4032f0","operator new","","0.16",
"0x401000","operator*","","25.86",
"0x401450","quatFromEuler","","29.16",
"0x405370","sin","","0.33",
"0x4019a0","sinf","","3.95",
"0x401e50","SlowGameEntity::calculateOrientation","","2.64",
"0x403a60","SlowGameEntity::SlowGameEntity","","0.49",
Making Friends With the Cache
Finally, let us take a look at how we can make quaterions more cache-friendly, which is usually a good way to improve performance given the fact that memory acesses are much faster from the cache. Since caches are designed on the principle of spatial locality, we will organize our quaternions in contiguous memory, so that they are always adjacent to each other. The cache will be able to operate on this data with less misses because it does not just load one quaternion at a time, but rather loads all of the adjacent bytes as well in order to fill up one cache line. The size of a cache line is hardware dependent, but it is often 64 bytes. So, if all of the quaternions are adjacent, loading one will also load other quaternions at the same time. If we write code that processes the quaternions sequentially, it is likely many of them will already be in the cache when they are needed.
So in the example code we have two different classes, SlowCacheObject and FastCacheObject. SlowCacheObject contains two quaternions, one for the object’s local space transform and the other for its world space transform. FastCacheObject does not contain these quaternions directly, but rather it contains a pointer to a struct which contains them. This way, all of the transforms for all FastCacheObjets can be kept in contiguous arrays of these structs.
Listing. 6 shows the two classes:
Listing 6.
class SlowCacheObject : public ObjectBase
{
public:
virtual void updateWorldTransform( SlowCacheObject *parent )
{
if ( parent )
D3DXQuaternionMultiply( &worldTransform_, &localTransform_, parent->getWorldTransform() );
}
D3DXQUATERNION *getWorldTransform() { return &worldTransform_; }
protected:
D3DXQUATERNION localTransform_;
D3DXQUATERNION worldTransform_;
};
class FastCacheObject : public ObjectBase
{
public:
struct Transforms
{
D3DXQUATERNION localTransform_;
D3DXQUATERNION worldTransform_;
};
Transforms *getTransforms() { return transforms_; }
void setTransforms( Transforms *transforms )
{
transforms_ = transforms;
}
virtual void updateWorldTransform( FastCacheObject *parent ){}
protected:
Transforms *transforms_;
};
We will create two trees, one with SlowCacheObject instances and one with FastCacheObject instances. Each tree will have a single root node which will have two children. Each root child will in turn have four children. The nodes in both trees will be allocated separately so they will not be adjacent in memory. The quaternions for the SlowCacheObject tree will be stored in each node. For the FastCacheObject nodes, there will be three arrays of Transforms structs, one for each level in the tree. These arrays will contain quaternions in contiguous memory for each node.
In order to update the world transform of each object in the tree, we must mulitply its local transform by its parent’s world transform and then store it in the object’s own world transform quaternion. For both trees, we will do this in a top-down fashion starting at the root and working our way down. Fig. 4 shows this process for the SlowCacheObject tree, and Fig.5 shows it for the FastCacheObject tree.
<shapetype id="_x0000_t75" stroked="f" filled="f" path="m@4@5l@4@11@9@11@9@5xe" o:preferrelative="t" o:spt="75" coordsize="21600,21600"><stroke joinstyle="miter"><f eqn="if lineDrawn pixelLineWidth 0"><f eqn="sum @0 1 0"><f eqn="sum 0 0 @1"><f eqn="prod @2 1 2"><f eqn="prod @3 21600 pixelWidth"><f eqn="prod @3 21600 pixelHeight"><f eqn="sum @0 0 1"><f eqn="prod @6 1 2"><f eqn="prod @7 21600 pixelWidth"><f eqn="sum @8 21600 0"><f eqn="prod @7 21600 pixelHeight"><f eqn="sum @10 21600 0"><path o:connecttype="rect" gradientshapeok="t" o:extrusionok="f"><lock aspectratio="t" v:ext="edit"><shape id="Picture_x0020_1" style="WIDTH: 533.25pt; HEIGHT: 276pt; VISIBILITY: visible" type="#_x0000_t75" o:spid="_x0000_i1026" alt="fig4"><imagedata o:title="fig4" src="file:///C:\Users\Cecille\AppData\Local\Temp\msohtmlclip1\01\clip_image001.jpg">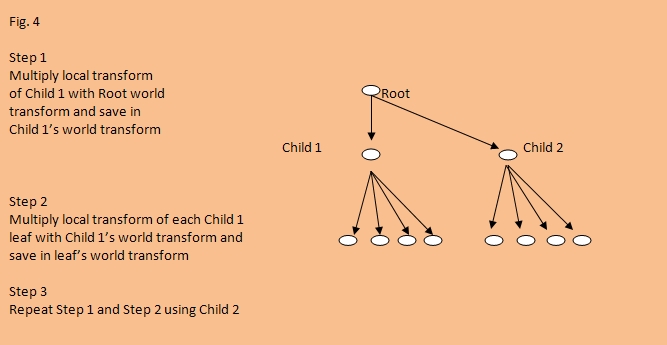
<shape id="Picture_x0020_2" style="WIDTH: 519.75pt; HEIGHT: 219pt; VISIBILITY: visible" type="#_x0000_t75" o:spid="_x0000_i1025" alt="fig5"><imagedata o:title="fig5" src="file:///C:\Users\Cecille\AppData\Local\Temp\msohtmlclip1\01\clip_image003.jpg">

In the example code, all of the code for updating the SlowCacheObject tree is contained in the Node.h and the SlowCacheObject.h files. For the FastCacheObject tree, all of the functionality for updating the tree is contained in the “updateWorldTransforms” function located in the QuatDemoCode.cpp file. As you can see from the above diagram, the method in the SlowCacheObject tree requires alternating back and forth between levels in the tree. After processing all of the left node leaves, we much go back up to the second level and repeat the process starting with the right node. In the FastCacheObject we simply iterate through two arrays and perform quaternion multiplications.
If we profile this code we get the results shown in Fig. 6.
Fig. 6.
CS:EIP,Symbol + Offset,64-bit,Timer samples,
"0x40423a","D3DXQuaternionMultiply","","1.2",
"0x40423a","D3DXQuaternionMultiply+0","","1.2",
"0x401c10","FastCacheObject::getTransforms","","0.76",
"0x401de0","Node<FastCacheObject>::getNumObjects","","0.54",
"0x402120","Node<SlowCacheObject>::updateAllObjects","","7.61",
"0x401f20","Node<SlowCacheObject>::updateWorldTransform","","3.7",
"0x401f80","SlowCacheObject::getWorldTransform","","1.2",
"0x401f50","SlowCacheObject::updateWorldTransform","","4.67",
"0x402500","std::_Aux_cont::_Getcont","","3.8",
"0x4024d0","std::_Iterator_base_aux::_Getmycont","","7.17",
"0x402510","std::_Iterator_base_aux::_Has_container","","16.41",
"0x402e00","std::_Iterator_base_aux::_Iterator_base_aux","","2.28",
"0x402580","std::_Iterator_base_aux::_Same_container","","3.26",
"0x402cb0","std::_Iterator_base_aux::_Set_container","","1.09",
"0x402de0","std::_Iterator_with_base<std::random_access_iterator_tag,FastCacheObject *,int,FastCacheObject * const *,FastCacheObject * const &,std::_Iterator_base_aux>::_Iterator_with_base<std::random_access_iterator_tag,FastCacheObject *,int,FastCacheObject * const *,Fa","","2.61",
"0x402dc0","std::_Ranit<SlowCacheObject *,int,SlowCacheObject * const *,SlowCacheObject * const &>::_Ranit<SlowCacheObject *,int,SlowCacheObject * const *,SlowCacheObject * const &>","","1.96",
"0x4025c0","std::_Vector_const_iterator<FastCacheObject *,std::allocator<FastCacheObject *> >::operator*","","4.35",
"0x402530","std::_Vector_const_iterator<FastCacheObject *,std::allocator<FastCacheObject *> >::operator==","","6.2",
"0x402d30","std::_Vector_const_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::_Vector_const_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >","","6.09",
"0x402260","std::_Vector_const_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::operator!=","","4.89",
"0x402cd0","std::_Vector_const_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::operator++","","4.89",
"0x4025a0","std::_Vector_iterator<FastCacheObject *,std::allocator<FastCacheObject *> >::_Vector_iterator<FastCacheObject *,std::allocator<FastCacheObject *> >","","1.52",
"0x402290","std::_Vector_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::operator*","","1.09",
"0x4022b0","std::_Vector_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::operator++","","3.7",
"0x4024b0","std::_Vector_iterator<SlowCacheObject *,std::allocator<SlowCacheObject *> >::operator++","","0.65",
"0x402200","std::vector<FastCacheObject *,std::allocator<FastCacheObject *> >::begin","","1.09",
"0x402230","std::vector<SlowCacheObject *,std::allocator<SlowCacheObject *> >::end","","2.07",
"0x402100","std::vector<SlowCacheObject *,std::allocator<SlowCacheObject *> >::size","","1.3",
"0x401630","testFastCacheObject","","0.22",
"0x401670","testSlowCacheObject","","0.33",
"0x401580","updateWorldTransforms","","3.37",
Even without counting all of the STL operators used by SlowCacheObject, we can see a significant performance advantage in the FastCacheObject approach. FastCacheObject does not use any STL operators except during construction/destruction of the tree. The main drawback to this approach, however, is that it is very static. If you are working with a very dynamic system where new objects will constantly be added and old objects deleted, it will be necessary to maintain and update all of the Transforms arrays at runtime. This can prove to be more trouble than it is worth, either being too difficult to implement or prohibitively costly in terms of performance. In contrast, the SlowCacheObject system is very dynamic in nature and can handle insertions and deletions in the tree in its present form with no new code required. As with all optimization techniques, you must consider the requirements of the project and the profiler data to determine what really needs to be optimized and how it should be done.
Conclusion
Quaternions definitely have memory space and time efficiency advantages over matrices. But there are still times when matrices are a better choice. So it is essential to always know exactly how each one implements the desired operations before deciding which one to use. Of course, the design requirements of the application always take priority over any performance concerns. So if there are some features such as smooth interpolation that are required by the design then you may have to use quaternions despite their performance. And as always, use a good profiler to determine where the real bottlenecks and hotspots are in the code in order to make the most of your optimization efforts.
Happy Coding,
Gabriel T. Delarosa
Bibliography:
Svarovsky, Jan, “Quaternions for Game Programming,“ Game Programming Gems, Charles River Media, 2000
http://research.scee.net/files/presentations/gcapaustralia09/Pitfalls_of_Object_Oriented_Programming_GCAP_09.pdf

