In this part of the article, we will add face recognition and control of the head to the code from part 1 to complete our Design Goal 1.
Introduction
The Rodney Robot project is a hobbyist robotic project to design and build an autonomous house-bot. This article is the second in the series describing the project.
Background
In Part 1 to help define the requirements for our robot, we selected our first mission and split it down into a number of Design Goals to make it more manageable.
The mission was taken from the article Let's build a robot! and was: Take a message to... - Since the robot will [have] the ability to recognize family members, how about the ability to make it the 'message taker and reminder'. I could say 'Robot, remind (PersonName) to pick me up from the station at 6pm'. Then, even if that household member had their phone turned on silent, or were listening to loud music or (insert reason to NOT pick me up at the station), the robot could wander through the house, find the person, and give them the message.
The design goals for this mission were:
- Design Goal 1: To be able to look around using the camera, search for faces, attempt to identify any people seen and display a message for any identified
- Design Goal 2: Facial expressions and speech synthesis. Rodney will need to be able to deliver the message
- Design Goal 3: Locomotion controlled by a remote keyboard and/or joystick
- Design Goal 4: Addition of a laser ranger finder or similar ranging sensor used to aid navigation
- Design Goal 5: Autonomous locomotion
- Design Goal 6: Task assignment and completion notification
In the first part, we used ROS (Robot Operating System) to add pan/tilt functionality to move the head and camera. In this part, I'll add the face recognition and control node to complete Design Goal 1.
Mission 1, Design Goal 1 Continued
Access Images from the Raspberry Pi Camera
As stated in Part 1, we can make use of work already carried out by the ROS community to make our life easier. The Raspberry Pi Ubuntu image I have installed includes a ROS package raspicam_node, we will make use of this package to access the camera. If you are using a different OS image on your Raspberry Pi, you can still install the node from the GitHub site.
To add the node to our system, we just need to include one of the supplied ROS launch files in our launch file. I'm going to use an image resolution of 1280 x 960 pixels, so adding the following to our launch file will start the raspicam_node in the required resolution.
<include file="$(find raspicam_node)/launch/camerav2_1280x960.launch" />
ROS uses its own image format to pass images between nodes. In the case of raspicam_node, this image is in a compressed format. Now when we come to use the image to detect and recognise a face, we will be using OpenCV to process the image. We therefore need a method to convert ROS images to OpenCV images and back again. Not a problem, those nice people in the ROS community have produced a package called cv_bridge which will do the work for us.
I will write the face recognition node in Python since 1) the pan_tilt node was written in C++ and writing the next node in Python will give us examples in both languages and 2) I already have a Python face recognition library I would like to make use of.
Now I'm using the Raspberry Pi camera but you can use a different camera. You may find a ROS node is already available for your camera or you may need to wrap the camera library in a ROS node of your own. Although the topic name our face recognition node subscribes to is called /raspicam/image/compressed, you can always remap your topic name to match this name in the launch file if you don't want to change the code.
<remap from="my_camera_node/image/compressed" to="raspicam_node/image compressed" />
Detect and Recognise Faces
Before the system can attempt to recognise a face, we need to train it with the subjects we wish to recognise. We will write two non ROS Python scripts to train our system. The first, data_set_generator.py, will use the camera to capture facial images of each of our subjects. The second, training.py, uses the images collected by the first script to do the actual training. The output of this second script is a yaml file containing the training data, the ROS node will load this training data during its initialisation. If you wish to add new people to your list of subjects, you will need to rerun each script.
Our ROS package for the node is called face_recognition and is available in the face_recognition folder. The sub folder scripts contains our two training scripts.
Each of the scripts makes use of face detection and face recognition built in to OpenCV. If you wish to fully understand how this works, then may I suggest you read some of the many articles available on the internet. One of these can be found here. Not one article I came across had the code for exactly what I wanted so I have borrowed code from a number of articles. Here, I'll give a high level description of each of the scripts starting with data_set_generator.py.
After the required imports, we load the classifier using the OpenCV library, declare a helper function which we use to ensure that folders we require exist. The folder dataset will hold all the captured images and trainer will hold both the yaml file with the training data and a file containing names and ids of our subjects.
import cv2
import os
import io
import numpy
import yaml
import picamera
face_detector = cv2.CascadeClassifier('../classifiers/haarcascade_frontalface_default.xml')
def assure_path_exists(path):
dir = os.path.dirname(path)
if not os.path.exists(dir):
os.makedirs(dir)
assure_path_exists("dataset/")
assure_path_exists("../trainer/")
Next, we set the camera resolution, set up some variables including the file name which holds our list of subjects and open the file.
We then create a window to display the image read from the camera. This will enable the subject to position themselves within the camera field of view.
The script will then prompt the user for the subjects unique ID, the subjects name and whether it is low light conditions or not. The unique IDs should start at 1 and be incremented by 1 each time you add a new subject and the name is the name that you wish the robot to use for this subject. You should ideally run this script twice per subject, once in bright light and a second time in low light conditions. This will improve the chances of the recognition algorithm having success. Each run of the script will take 100 images of the subject, the file name of each image is constructed from the subject id and an image number. Image numbers are numbered 0 to 99 for those taken in bright light and 100 to 199 for those taken in low light.
The next step is to add the subject to the names file if they don't already exist.
with picamera.PiCamera() as camera:
camera.resolution = (1280, 960)
looping = True
count = 0
end = 99
names_dict = {}
name_file = '../trainer/names.yml'
if os.path.exists(name_file):
with open(name_file, 'r') as stream:
names_dict = yaml.load(stream)
cv2.namedWindow('frame', cv2.WINDOW_NORMAL)
face_id = raw_input("What is this persons ID number? ")
name = raw_input("What is this persons name? ")
low_light = raw_input("Low light Y/N?" )
if low_light == 'Y' or low_light == 'y':
count = 100
end = 199
if not face_id in names_dict:
names_dict[int(face_id)]=name
with open(name_file, 'w') as outfile:
yaml.dump(names_dict, outfile, default_flow_style=False)
A loop is then entered to capture the images. Each pass of the loop captures an image from the camera and converts it to a numpy array for the OpenCV calls.
Using OpenCV, we then convert the image to a grey scale image and attempt to detect a face in the image. If a face is detected, the image is cropped around the face, the number of image samples is incremented and the cropped grey scale image is stored in the dataset folder. The original image from the camera along with a superimposed frame around the face is displayed to the user.
A check is then made to see if the user has pressed the 'q' key on the keyboard which is used to exit the program early. Otherwise, a check is made to see if we have captured the one hundred images of the face, if so, this main loop is exited.
while(looping):
stream = io.BytesIO()
camera.capture(stream, format='jpeg')
buff = numpy.fromstring(stream.getvalue(), dtype=numpy.uint8)
image_frame = cv2.imdecode(buff, 1)
gray = cv2.cvtColor(image_frame, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray, 1.3, 5)
if (len(faces) != 0):
(x, y, w, h) = faces[0]
cv2.rectangle(image_frame, (x,y), (x+w,y+h), (255,0,0), 4)
count += 1
cv2.imwrite("dataset/User." + str(face_id) + '.' + str(count) + ".jpg", gray[y:y+h,x:x+w])
cv2.imshow('frame', image_frame)
if cv2.waitKey(100) & 0xFF == ord('q'):
looping = False
elif count>end:
looping = False
The last two lines close the window displaying the image and print a message indicating the process is complete.
cv2.destroyAllWindows()
print("Data prepared")
Once you have run the script for each subject, or if you have rerun the script for a new subject, you then run the training.py script.
The training.py script starts with the imports and the assure_path_exists function definition, it then creates an instance of the OpenCV classes LBPHFaceRecognizer_create and CascadeClassifier using the same classifier file.
import cv2
import os
import numpy as np
def assure_path_exists(path):
dir = os.path.dirname(path)
if not os.path.exists(dir):
os.makedirs(dir)
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("../classifiers/haarcascade_frontalface_default.xml");
The get_images_and_labels function reads in each stored image, detects the face and obtains the id from the file name.
def get_images_and_labels(path):
image_paths = [os.path.join(path,f) for f in os.listdir(path)]
face_samples=[]
ids = []
for image_path in image_paths:
gray = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
id = int(os.path.split(image_path)[-1].split(".")[1])
faces = detector.detectMultiScale(gray);
if (len(faces) == 0):
print "No face on " + image_path
else:
(x, y, w, h) = faces[0]
face_samples.append(gray[y:y+h,x:x+w])
ids.append(id)
return face_samples,ids
Once all the faces and ids are obtained, they are passed to the OpenCV face recognizer and the data from the recognizer is saved to disk. The face recognition library that will be used by our node will later load this data to train the recognizer.
faces,ids = get_images_and_labels('dataset')
recognizer.train(faces, np.array(ids))
assure_path_exists('../trainer/')
recognizer.save('../trainer/trainer.yml')
print("Done")
The code for the ROS node itself is in the sub folder src in the file face_recognition_node.py. The code makes use of a library file, face_recognition_lib.py, which contains the class FaceRecognition. This file is in the sub folder src/face_recognition_lib.
Before describing the code for the node, I'll discuss the FaceRecognition class. After the required imports and the declaration of the class, it defines a number of functions.
The class constructor creates the OpenCV face recognizer and then reads the training file created by the training script. It then opens the file containing the list of names and the ids, and creates the classifier. It finally stores a confidence value passed to it. This value will be used to determine if the suggested ID for the face is accepted.
def __init__(self, path, confidence):
self.__face_recognizer = cv2.face.LBPHFaceRecognizer_create()
self.__face_recognizer.read(path + '/trainer/trainer.yml')
with open(path + '/trainer/names.yml', 'r') as stream:
self.__names_dict = yaml.load(stream)
self.__face_detector = cv2.CascadeClassifier
(path + '/classifiers/haarcascade_frontalface_default.xml')
self.__confidence_level = confidence
Two functions are declared which will be used to modify the captured image if a face is detected. The first will draw a rectangle on the image and the second will draw the supplied text on the image.
def draw_rectangle(self, img, rect, bgr):
(x, y, w, h) = rect
cv2.rectangle(img, (x, y), (x+w, y+h), bgr, 4)
def draw_text(self, img, text, x, y, bgr):
cv2.putText(img, text, (x, y), cv2.FONT_HERSHEY_PLAIN, 3.0, bgr, 4)
The next function detect_faces, is used to detect any faces in the supplied image. It converts the image to grey scale so that OpenCV can be used to detect any faces. If faces are detected, then the data for each face and a location of the face in the image is returned. Note that this part of the code is written to allow more than one face to be seen in the image.
def detect_faces(self, img):
face_data = []
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces_detected = self.__face_detector.detectMultiScale(gray, 1.3, 5);
if (len(faces_detected) == 0):
return None, None
for face in faces_detected:
(x, y, w, h) = face
face_data.append(gray[y:y+w, x:x+h])
return face_data, faces_detected
The final function in the class, scan_for_faces, is the one which will be called by the node to do the face detecting and recognition on the supplied image. This function calls the detect_faces function and if any faces are detected, it loops through each face calling the OpenCV face predictor which returns the id of the recognised face and a value indicating the confidence in the prediction. This value is converted to a percentage of confidence. From the supplied id, a name is obtained. A rectangle is drawn around the face along with the name of the subject and the confidence level. If the confidence level of the prediction exceeds the stored threshold value, the box and text drawn on the image will be in the colour green, otherwise in the colour red. Also if the confidence threshold is exceeded, a dictionary entry of the id and name will be entered. Once all the faces detected have been analysed, this dictionary is returned to the caller.
def scan_for_faces(self, img):
faces, rects = self.detect_faces(img)
detected_dict = {}
if(faces != None):
for index in range(len(faces)):
label, confidence = self.__face_recognizer.predict(faces[index])
our_confidence = round(100 - confidence, 2)
name_text = self.__names_dict[label]
name_text_confidence = name_text + " {0:.2f}%".format(our_confidence)
if(our_confidence > self.__confidence_level):
colour = (0, 255, 0)
else:
colour = (0, 0, 255)
self.draw_rectangle(img, rects[index], colour)
self.draw_text(img, name_text_confidence, rects[index,0], rects[index,1]-5, colour)
if(our_confidence > self.__confidence_level):
detected_dict[label]=name_text
return detected_dict
Next I'll describe the ROS node itself.
The main routine initialises ROS for the node and creates an instance of FaceRecognitionNode and then calls spin to process the topics subscribed to and published.
def main(args):
rospy.init_node('face_recognition_node', anonymous=False)
frn = FaceRecognitionNode()
rospy.loginfo("Face recognition node started")
try:
rospy.spin()
except KeyboardInterrupt:
print("Shutting down")
if __name__ == '__main__':
main(sys.argv)
The rest of the file contains the FaceRecognitionNode class.
The constructor for FaceRecognitionNode creates an instance of CVBridge, as previously stated, this will be used to convert the ROS image to an OpenCV image. It then registers that it will publish the topic face_recognition_node/image/compressed which will be used to send the image with a box drawn around any faces recognised with the subject name and confidence level also printed on the image. This topic is used for testing the node.
The node subscribes to the topic raspicam_node/image/compressed which will contain the latest image from the camera, the function callback is registered to be called when a new image is received.
The confidence threshold is read from the parameter server and is set to the default value of 20% if a value is not held in the parameter server.
The constructor then creates an instance of the FaceRecognition class described above.
Finally, we create and start an action server. An action is used when a node is required to perform a non-blocking task which may take some time. A request is sent to perform the task and a reply is received once the task is complete. Feedback during the task can also be received. The task request can also be cancelled. More information on ROS actions can be found here. The file containing our user defined action message is described later in this section.
class FaceRecognitionNode:
def __init__(self):
self.__bridge = CvBridge()
self.__image_pub = rospy.Publisher('face_recognition_node/image/compressed',
CompressedImage, queue_size=1)
self.__image_sub = rospy.Subscriber('raspicam_node/image/compressed',
CompressedImage, self.callback)
confidence_level = rospy.get_param('/face_rec_python/confidence_level', 20)
rospy.loginfo("FaceRecognitionNode: Confidence level %s", str(confidence_level))
self.__frc = face_recognition_lib.FaceRecognition
(roslib.packages.get_pkg_dir('face_recognition', required=True), confidence_level)
self.__as = actionlib.SimpleActionServer
('face_recognition', scan_for_facesAction, self.do_action, False)
self.__as.start()
The function do_action is called by the action server when a request to conduct the action is received.
This function converts the last received image from a ROS image to an OpenCV image. A call to the scan_for_faces is made to check the image for known faces. The adjusted image, which may now contain superimposed boxes and names is converted back to a ROS image and published on the face_recognition_node/image/compressed topic.
The names and ids returned from the call to scan_for_faces is then used to create the result of the action. If no faces were recognised, the data in the result will be empty.
def do_action(self, goal):
image = self.__bridge.compressed_imgmsg_to_cv2(self.__current_image)
detected_dict = self.__frc.scan_for_faces(image)
try:
self.__image_pub.publish(self.__bridge.cv2_to_compressed_imgmsg(image))
except CvBridgeError as e:
print(e)
ids = []
names = []
for k, v in detected_dict.items():
ids.append(k)
names.append(v)
result = scan_for_facesResult()
result.ids_detected = ids
result.names_detected = names
self.__as.set_succeeded(result)
The function callback is called each time a message is received on the raspicam/image/compressed topic.
This function simply stores the current image should it be required for facial recognition.
def callback(self, data):
self.__current_image = data
The node package also contains a config.yaml file which can be used to set the confidence level without having to recompile the code. The package also contains a launch file, test.launch, which can be used to test the node. As well as launching this node, it will launch the camera node.
Face Recognition Action
As stated above, the face_recognition package uses a user defined action message to kick off the operation and to return the result of looking for known faces. The package face_recognition_msgs contains our first ROS action scan_for_faces.action.
The files for the package are available in the face_recognition_msgs folder and the file for the action is stored in the action sub folder.
An action specification contains a goal, result and feedback section. It looks similar to a message definition file except each of these parts is divided by the three dashes (---).
# This action scans the next camera image for faces that are recognised
# There are no parameters to start the action
---
# Results of the scan
uint16[] ids_detected
string[] names_detected
---
# No parameters for feedback
Above the first three dashes is the goal. In our case, we don't have any parameters for the goal, just the receipt of the goal will start our action.
The result parameters are below the first three dashes and in our case contain an array of ids and an array of names for any recognised faces.
Below the second three dashes is the feedback parameters. In our case, we will not return any feedback.
Controlling the Head
We now have a node to carry out the facial recognition operation on an image from the camera and from part 1 of this article, we have the pan/tilt functionality to move the servos connected to the head. We will now add a node which accepts a position the head should be in, but moves the head to that target in steps so as not to rock the robot when the head moves from one extreme to the other. The node will also accept not only absolute position to move to, but a relative distance to move from the current position.
Our ROS package for the node is called head_control and is available in the head_control folder. The package contains all the usual ROS files and folders.
The action folder contains the point_head.action file. This action will pass a goal containing the position to move to and feedback of where the head is on its way to the target position.
# This action moves the head to a given position
# The goal definition is the position to move the head to if absolute is true,
# otherwise the pan/tilt values are how much relative to move the head.
# Values are radians.
bool absolute
float64 pan
float64 tilt
---
# There are no parameters for the result
---
# Feedback gives the current position
float64 current_pan
float64 current_tilt
The goal contains a pan and tilt value in radians. It also contains a boolean flag absolute. If the flag is true, then the pan and tilt values are the absolute target position. If the flag is false, then the values represent how much the head should be moved relative to the current position.
The feedback values represent the current position of the head on its way to the target position.
The config folder contains a config.yaml file which can be used to override some of the default configuration values. You can configure:
- The default position of the head
- The maximum value the pan and tilt device should move per request. This is to stop the servo moving a requested angle in one jump and causing the head to shudder
head:
position:
pan: 0.0
tilt: 0.0
max_step:
pan: 0.0872665
tilt: 0.0872665
The include/head_control and src folders contain the C++ code for the package. For this package, we have one C++ class, HeadControlNode and a main routine contained within the head_control_node.cpp file.
The main routine informs ROS of our node, creates an instance of the class for the node and passes it the node handle and node name. For the first time in the project, we are not going to hand total control of the node to ROS. In all our other nodes so far, we have handed off control to ROS with a call to ros::spin in C++ or rospy.spin in our Python code. These calls hand control to ROS and our code only gets to run when ROS calls one of our callback functions when a message is received. In this node, I want to retain control as we want to move the servos in small incremental steps to a target position. If we allow the servos to move a large angle in one go, the head comes to a shuddering stop when the target position is reached. The way that we retain control is to call ros::spinOnce. In this function, ROS will publish any topics we have requested and process any incoming topics by calling our callbacks but will then return control to main.
Before we enter the while loop, we create an instance of ros::Rate and pass it the timing we would like to maintain, in our case I'm setting the rate to 10Hz. When inside the loop we call r.sleep, this Rate instance will attempt to keep the loop at 10Hz by accounting for the time used to complete the work in the loop.
Our loop will continue while the call to ros::ok returns true, it will return false when the node has finished shutting down, e.g., when you press Ctrl-c on the keyboard.
In the loop, we will call moveServo which is described later in the article.
int main(int argc, char **argv),
{
ros::init(argc, argv, "head_control_node");
ros::NodeHandle n;
std::string node_name = ros::this_node::getName();
HeadControlNode head_control(n, node_name);
ROS_INFO("%s started", node_name.c_str());
ros::Rate r(10);
while(ros::ok())
{
head_control.moveServo();
ros::spinOnce();
r.sleep();
}
return 0;
}
The rest of the file contains the HeadControlNode class.
The constructor for HeadControlNode registers our callback function, pointHeadCallback,with the action server. This callback will be called when the action server receives the action goal, this in effect kicks off the action.
We then start the server running with the as_.start call.
The constructor then advertises that it will publish the topic pan_tilt_node/joints which will be used to pass the required pan/tilt position to the pan/tilt node.
We then set some configuration defaults and read any overrides from the parameter server should they be available.
Next, we set names of our joints in the joint state message as these will not change.
Finally, we publish a message to move the head to a known starting point. We can't move to this position in small steps as we don't know our starting position after power up.
HeadControlNode::HeadControlNode(ros::NodeHandle n, std::string name) : as_(n, name, false)
{
nh_ = n;
as_.registerGoalCallback(boost::bind(&HeadControlNode::pointHeadCallback, this));
as_.start();
move_head_pub_ = nh_.advertise<sensor_msgs::JointState>("pan_tilt_node/joints", 10, true);
nh_.param<std::string>("/servo/index0/pan/joint_name", pan_joint_name_, "reserved_pan0");
nh_.param<std::string>("/servo/index0/tilt/joint_name", tilt_joint_name_, "reserved_tilt0");
nh_.param("/head/max_step/pan", pan_step_, 0.174533);
nh_.param("/head/max_step/tilt", tilt_step_, 0.174533);
double pan; double tilt; nh_.param("/head/position/pan", pan, 0.0);
nh_.param("/head/position/tilt", tilt, 0.0);
default_position_.pan = pan;
default_position_.tilt = tilt;
msg_.name.push_back(pan_joint_name_);
msg_.name.push_back(tilt_joint_name_);
msg_.position.push_back(0.0);
msg_.position.push_back(0.0);
current_pan_tilt_ = default_position_;
publishJointState(current_pan_tilt_);
move_head_ = false;
movement_complete_ = false;
target_pan_tilt_ = current_pan_tilt_;
}
I'll now briefly describe the functions that make up the class.
The pointHeadCallback is called by ROS when the action server receives a goal message. The goal data is either the absolute or relative target position depending on the state of the absolute flag.
The function calls the action server to inform it that the goal has been accepted, it stores the new target position and sets the flag move_head to true indicating that the head is required to be moved.
void HeadControlNode::pointHeadCallback()
{
head_control::point_headGoal::ConstPtr goal;
goal = as_.acceptNewGoal();
if (goal->absolute == true)
{
target_pan_tilt_.pan = goal->pan;
target_pan_tilt_.tilt = goal->tilt;
}
else
{
target_pan_tilt_.pan += goal->pan;
target_pan_tilt_.tilt += goal->tilt;
}
move_head_ = true;
movement_complete_ = false;
}
The function, moveServo, is the function called by main in our loop. It checks to see if a request to move the head was made and if so enters an 'if', 'else if', 'else' construct.
The 'if' part of this construct checks to see if the action has been pre-empted. If so, accepts the pre-emption and tidies up.
The 'else if' part checks to see if the head movement is complete, if so a counter is decremented. This counter is used to include time for the head to stop moving and blurring any camera images after the servos reach the target position. When the counter reaches zero, the fact that the action is complete is reported to the action server. There are no parameters in the result.
The 'else' part is responsible for calculating the next step movement of the servos towards the target position, it also publishes the joint state message with the next required servo position using the helper function publishJointState and reports the feedback to the action server. This feedback will contain the position that the servos were just asked to move to.
void HeadControlNode::moveServo()
{
if(move_head_ == true)
{
if(as_.isPreemptRequested() || !ros::ok())
{
as_.setPreempted();
movement_complete_ = false;
move_head_ = false;
}
else if(movement_complete_ == true)
{
loop_count_down_--;
if(loop_count_down_ <= 0)
{
movement_complete_ = false;
move_head_ = false;
head_control::point_headResult result;
as_.setSucceeded(result);
}
}
else
{
if((target_pan_tilt_.pan == current_pan_tilt_.pan) &&
(target_pan_tilt_.tilt == current_pan_tilt_.tilt))
{
movement_complete_ = true;
loop_count_down_ = 8;
}
else
{
if(std::abs(target_pan_tilt_.pan - current_pan_tilt_.pan) > pan_step_)
{
if(target_pan_tilt_.pan > current_pan_tilt_.pan)
{
current_pan_tilt_.pan += pan_step_;
}
else
{
current_pan_tilt_.pan -= pan_step_;
}
}
else
{
current_pan_tilt_.pan = target_pan_tilt_.pan;
}
if(std::abs(target_pan_tilt_.tilt - current_pan_tilt_.tilt) > tilt_step_)
{
if(target_pan_tilt_.tilt > current_pan_tilt_.tilt)
{
current_pan_tilt_.tilt += tilt_step_;
}
else
{
current_pan_tilt_.tilt -= tilt_step_;
}
}
else
{
current_pan_tilt_.tilt = target_pan_tilt_.tilt;
}
publishJointState(current_pan_tilt_);
head_control::point_headFeedback feedback;
feedback.current_pan = current_pan_tilt_.pan;
feedback.current_tilt = current_pan_tilt_.tilt;
as_.publishFeedback(feedback);
}
}
}
}
The final function in the class is the helper function publishJointState. This function updates the position values in the joint state message and then publishes the message.
void HeadControlNode::publishJointState(struct position pan_tilt)
{
msg_.position[0] = pan_tilt.pan;
msg_.position[1] = pan_tilt.tilt;
msg_.header.stamp = ros::Time::now();
move_head_pub_.publish(msg_);
}
The package also includes a launch file in the launch folder. This file, test.launch, will launch all the nodes developed to move the head.
="1.0"
<launch>
<rosparam command="load" file="$(find pan_tilt)/config/config.yaml" />
<rosparam command="load" file="$(find head_control)/config/config.yaml" />
<node pkg="pan_tilt" type="pan_tilt_node" name="pan_tilt_node" output="screen" />
<node pkg="rosserial_python" type="serial_node.py"
name="serial_node" output="screen" args="/dev/ttyUSB0"/>
<node pkg="head_control" type="head_control_node" name="head_control_node" output="screen"/>
</launch>
Action Client
Having included action servers in both our nodes, you would expect to have action clients to connect with them. This is definitely one method of communicating with the server. In a later part of the article, I'm going to introduce a ROS package which will allow us to create state machines and sub-state machines to control our robot missions. Using this package, it is possible to assign an individual state to be the action client and all the communication is done behind the scenes for us.
In order to test the system we have developed so far and to show how to write an action client, we will write two test nodes here which will include an action client in each one.
Our first node is a very simple node written in Python and will be used to test the face recognition node. The ROS package for this node is called rodney_recognition_test and is available in the rodney_recognition_test folder. The package contains all the usual ROS files and folders.
All the code is contained in the rodney_recognition_test_node.py file in the src folder.
The code initialises our node and creates an action client. Note that the name passed to the SimpleActionClient, in our case 'face_recognition' must match the name given to the action server.
We then call wait_for_server, the code will wait here until it is able to make contact with the server. We then create a goal, which in this case contains no data, and send the goal to the server.
In our simple example, we then wait until the result is returned and the node finishes by printing the id and names of any faces recognised and returned in the result.
import rospy
import actionlib
from face_recognition_msgs.msg import scan_for_facesAction,
scan_for_facesGoal, scan_for_facesResult
rospy.init_node('face_recognition_client')
client = actionlib.SimpleActionClient('face_recognition', scan_for_facesAction)
client.wait_for_server()
goal = scan_for_facesGoal()
client.send_goal(goal)
client.wait_for_result()
result = client.get_result()
print(result.ids_detected)
print(result.names_detected)
In our next package to test the head_control node, we will write a slightly more complicated node, this time written in C++.
Our ROS package is called rodney_head_test and is available in the rodney_head_test folder. The package contains all the usual ROS files and folders.
The include/rodney_head_test and src folders contain the C++ code for the package. For this package, we have one C++ class, RodneyHeadTestNode and a main routine contained within the rodney_head_test_node.cpp file.
The main routine informs ROS of our node, creates an instance of the class for the node and passes it the node handle, logs that the node has started and hands control to ROS with the call to ros::spin.
int main(int argc, char **argv)
{
ros::init(argc, argv, "rodney_head_test");
ros::NodeHandle n;
RodneyHeadTestNode rodney_head_test_node(n);
std::string node_name = ros::this_node::getName();
ROS_INFO("%s started", node_name.c_str());
ros::spin();
return 0;
}
The constructor creates an instance of our action client, ac_, and passes it the name of the action server which in our case is head_control_node. This must match the name we gave to our action server when we created it in the HeadControlNode constructor.
We then read the config parameters to limit the movement of the servos.
We are going to use a keyboard node which is available from https://github.com/lrse/ros-keyboard, to interact with the system. In the constructor, we subscribe to the topic keyboard/keydown and call the function keyboardCallBack when a message is received on that topic.
The call ac_.waitForServer will wait in the constructor until our action server is running.
RodneyHeadTestNode::RodneyHeadTestNode(ros::NodeHandle n) : ac_("head_control_node", true)
{
nh_ = n;
key_sub_ = nh_.subscribe("keyboard/keydown", 100,
&RodneyHeadTestNode::keyboardCallBack, this);
nh_.param("/servo/index0/pan/max", max_pan_radians_, M_PI/2.0);
nh_.param("/servo/index0/pan/min", min_pan_radians_, -(M_PI/2.0));
nh_.param("/servo/index0/tilt/max", max_tilt_radians_, M_PI/2.0);
nh_.param("/servo/index0/tilt/min", min_tilt_radians_, -(M_PI/2.0));
ROS_INFO("RodneyHeadTestNode: Waiting for action server to start");
ac_.waitForServer();
moving_ = false;
ROS_INFO("RodneyHeadTestNode: Action server started");
}
The function keyboardCallBack checks the received message and runs a test dependent on the key pressed.
It creates an instance of our action goal, sets the goal parameters and passes it to the action server with a call to ac_.sendGoal. With the call, we pass three callback functions:
doneCB which is called when the action is completedactiveCB which is called when the action goes active andfeedbackCB which is called when the feedback on the progress of the action is received
The action can be pre-empted, so if the 'c' key is pressed and moving the head is in progress, we will cancel the action with a call to ac_.cancelGoal.
void RodneyHeadTestNode::keyboardCallBack(const keyboard::Key::ConstPtr& msg)
{
head_control::point_headGoal goal;
if((msg->code == keyboard::Key::KEY_1) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = true;
goal.pan = max_pan_radians_;
goal.tilt = max_tilt_radians_;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_2) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = true;
goal.pan = min_pan_radians_;
goal.tilt = min_tilt_radians_;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_3) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = true;
goal.pan = 0.0;
goal.tilt = 0.0;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_4) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = true;
goal.pan = 0.0;
goal.tilt = -0.785398;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_5) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = false;
goal.pan = 0;
goal.tilt = -0.174533;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_6) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = false;
goal.pan = 0.349066;
goal.tilt = 0;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
if((msg->code == keyboard::Key::KEY_7) &&
((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0))
{
goal.absolute = false;
goal.pan = -0.349066;
goal.tilt = 0.174533;
ac_.sendGoal(goal,
boost::bind(&RodneyHeadTestNode::doneCB, this, _1, _2),
boost::bind(&RodneyHeadTestNode::activeCB, this),
boost::bind(&RodneyHeadTestNode::feedbackCB, this, _1));
}
else if((msg->code == keyboard::Key::KEY_c) &&
((msg->modifiers & ~RodneyHeadTestNode::SHIFT_CAPS_NUM_LOCK_) == 0))
{
if(moving_ == true)
{
ac_.cancelGoal();
}
}
else
{
;
}
}
The callback function activeCB is called when the action goes active, here we log the fact and set a member variable indicating that movement is taking place.
void RodneyHeadTestNode::activeCB()
{
ROS_INFO("RodneyHeadTestNode: Goal just went active");
moving_ = true;
}
The callback function feedbackCB is called when feedback on the progress of the action is received. If you remember, our feedback includes the current position of the servos on their way to the target position.
void RodneyHeadTestNode::feedbackCB(const head_control::point_headFeedbackConstPtr& feedback)
{
ROS_INFO("Feedback pan=%f, tilt=%f", feedback->current_pan, feedback->current_tilt);
}
The callback function donCB is called when the action is completed. In this case, the result data is empty.
void RodneyHeadTestNode::doneCB(const actionlib::SimpleClientGoalState& state,
const head_control::point_headResultConstPtr& result)
{
ROS_INFO("RodneyHeadTestNode: Finished in state [%s]", state.toString().c_str());
moving_ = false;
}
Using the Code
In this article, we will test the two nodes individually. In Part 4, we will put the two together so that the robot can scan a room within its head movement range looking for faces it recognises.
As previously when testing the code, I'm going to run the system code on the Raspberry Pi and the test code on a separate Linux workstation. The Raspberry Pi will also be connected to the Arduino nano which in turn is connected to the servos and running the sketch from part one of the article.
Note that to distinguish between the Pi and the workstation in the instructions below, the code is in a folder (workspace) called "rodney_ws" on the Pi and "test_ws" on the workstation.
Building the ROS Packages on the Pi
If not already done, create a catkin workspace on the Raspberry Pi and initialise it with the following commands:
$ mkdir -p ~/rodney_ws/src
$ cd ~/rodney_ws/
$ catkin_make
Copy the packages face_recognition, face_recognition_msgs, head_control, pan_tilt and servo_msgs into the ~/rodney_ws/src folder and then build the code. As a little tip, I don't copy the code into the src folder but create a symbolic link in the src folder to the code location. That way, I can have a number of workspaces using the same code files.
$ cd ~/rodney_ws/
$ catkin_make
Check that the build completes without any errors.
Building the ROS Test Packages on the Workstation
You can build and run the test packages on the Raspberry Pi but I'm going to use a Linux workstation which is on the same network as the Pi.
Create a workspace with the following commands:
$ mkdir -p ~/test_ws/src
$ cd ~/test_ws/
$ catkin_make
Copy the packages face_recognition, face_recognition_msgs, head_control, pan_tilt, servo_msgs, rodney_recognition_test, rodney_head_test and ros-keyboard (from https://github.com/lrse/ros-keyboard) into the ~/test_ws/src folder and then build the code with the following commands:
$ cd ~/test_ws/
$ catkin_make
Check that the build completes without any errors.
Tip
When running ROS code and tools on a workstation and the Raspberry Pi, there can be a lot of repeat typing of commands at a number of terminals. In the next section, I have included the full commands to type but here are a few tips that can save you all that typing.
On the Raspberry Pi to save typing "source devel/setup.bash" I have added it to the .bashrc file for the Raspberry Pi.
$ cd ~/
$ nano .bashrc
Then add "source /home/ubuntu/rodney_ws/devel/setup.bash" to the end of the file, save and exit.
When running test code and tools on the workstation, it also needs to know where the ROS master is so I have added the following to the .bashrc file for the workstation.
alias rodney='source ~/test_ws/devel/setup.bash; \
export ROS_MASTER_URI=http://ubiquityrobot:11311'
Then by just typing "rodney" at a terminal, the two commands are run and a lot of typing is saved.
Running the Code
First, we will test the face recognition node. Use the launch file to start the nodes with the following commands on the Raspberry Pi:
$ cd ~/rodney_ws/
$ source devel/setup.bash
$ roslaunch face_recognition test.launch
With the nodes running on the Raspberry Pi, I'm going to use a Linux workstation on the same network to run some test.
Note: As we will use our user defined topics, the code also needs to be built on this workstation. You can, if you wish, run the tests on the same Raspberry Pi running the system nodes.
At the workstation, run the following to check that the nodes are running and connected to the correct topics. You can see the name of master in the output from running roslaunch. As I'm using the Ubiquity ROS Ubuntu image and have not changed the name, my master is ubiquityrobot.
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ rqt_graph
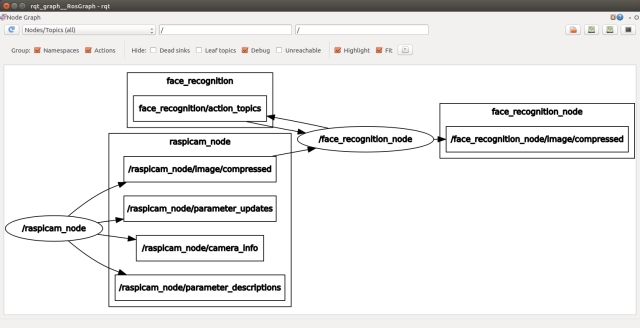
If any topics have been misspelt in one part of the code, then it will be obvious from the graph as the nodes will not be joined by the topics.
In another terminal, enter the following in order to be able to view the images.
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ rqt_image_view
In the Image View GUI, you can select the topic /raspicam/image/compressed to view the current camera image. For the test, I'm going to select the topic /face_recognition_node/image/compressed, the image will currently be blank but when we request a face recognition operation, we will be able to view the result.
In a new terminal, run the test node to conduct the face recognition process on an image from the camera.
$ cd ~/test_ws
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ source devel/setup.bash
$ rosrun rodney_recognition_test rodney_recognition_test_node.py
You can rerun the process by just entering the last line again in the same terminal. The result of each run will be shown in the rqt_image_view window and output in the terminal.
When I ran the test without anyone in view of the camera, the image viewer displayed an image of the room and the terminal reported empty results with:
()
[]
When run with myself in view of the camera, the terminal and the image viewer displayed the following:
(1,)
['Phil']

When testing with two people in the image, it's trained for both these subjects, I got the following results:
(1, 2,)
[Phil, Dave]
---
You can close down each terminal on the workstation and the Pi by entering Ctrl-C in the terminal.
Next we will test the head control node. With the Arduino connected to a USB port of the Pi, use the launch file to start the nodes with the following commands:
$ cd ~/rodney_ws/
$ source devel/setup.bash
$ roslaunch head_control test.launch
When the code starts, the head will move to the default position.
Next, I'm going to use rqt_graph and our test code to test the system. On the workstation, run the following commands to start the keyboard node:
$ cd ~/test_ws
$ source devel/setup.bash
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ rosrun keyboard keyboard
On the workstation in a second terminal, run the following commands to start our test node:
$ cd ~/test_ws
$ source devel/setup.bash
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ rosrun rodney_head_test rodney_head_test_node
In a third terminal, run the following commands to start rqt_graph:
$ cd ~/test_ws
$ export ROS_MASTER_URI=http://ubiquityrobot:11311
$ rqt_graph
From the graph, you should see the nodes under test and the test code running. You should also see the nodes linked by the topics. Any broken links is an indication of misspelt topics in the code.
The workstation should also be running a small window whose title is "ROS keyboard input". Make sure this window has the focus and then press a key for the following tests. During a scan head movement, you can press the 'c' key to cancel the action.
- Key '
1' - The head will move to the maximum pan and tilt position (left and down) - Key '
2' - The head will move to the minimum pan and tilt position (right and up) - Key '
3' - The head will move back to zero pan and tilt position - Key '
4' - The head will tilt to up to the 45 degrees position - Key '
5' - The head will move up from the current position by 5 degrees - Key '
6' - The head will move anti-clockwise (left) from the current position by 20 degrees - Key '
7' - The head will move clockwise (right) from the current position by 20 degrees and down by 10 degrees
Points of Interest
In this part of the article, we have added the face recognition and control of the head to the code from part 1 to complete our Design Goal 1.
In the next article, I'll give Rodney facial expressions and speech to complete Design Goal 2.
A short video showing Rodney running a test of the combined Design Goal 1 and 2.
History
- 18th August, 2018: Initial release
- 7th October, 2018: Version 2: Slight change to what the next article will cover and changed chapter, section and sub-section to match part 1
- 11th January, 2019: Version 3: Now using compressed images, the ROS standard units of radians and actions for both face recognition and head control nodes

