Introduction
In an earlier article, I described how you may add a logging framework to your ESB solution, and I created a tiny application to illustrate the components of the ESB. I did not however dig into basic principles or best practices or naming conventions or just how little you may need, to get to a workable ESB.
In this article, I will illustrate with a Minimum Viable Product for a truly tiny, yet efficient ESB, just how little you need, to implement the basic principles of the ESB, and I will discuss the routing part and suggest some workable guidelines. I will also touch upon the subscription and transformation but keep a deeper discussion for another time.
Requirements
The main functionality of an ESB is to enable systems to publish messages, for other systems to subscribe to these messages and to have them delivered in a suitable format. The functional requirements or principles may be formalised as:
- ESB is real-time integration
- ESB implements the publish-subscribe pattern
- ESB flows are asynchronous
- ESB flows are one-way
I think it is a common misunderstanding of the ESB concept to let the source system have opinions about where the published messages should go. The ESB is not a post office. Published messages do not have an address. The core concept of the ESB is that source systems publish data without knowing what systems will subscribe to it - it is an abstraction mechanism that ensures that both publishers and subscribers may change without ever impacting each other.
How may this be achieved? The main trick is to publish data in a predefined, consistent format. This may be achieved either by the source systems publishing data directly according to a specification, or as is the case in some implementations (i.e., BizzTalk) by transforming received messages into an internal, canonical format, which is then consumed and transformed for the needs of individual destination systems.
In any case: The format is the contract - not where it is coming from or where it is going.
Architecture
In more architectural terms, the ESB must offer:
- a receiving location
- a routing mechanism
- a transformation mechanism
- a delivery mechanism
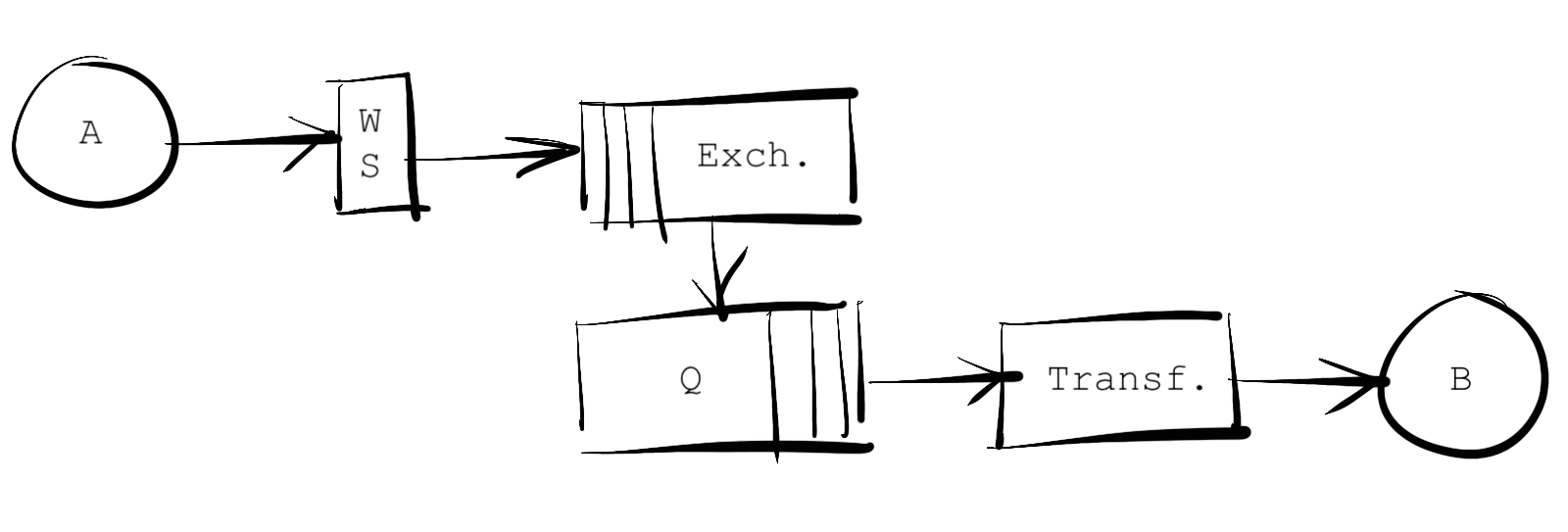
ESB components
The figure above illustrates the components in the tiny demo application: the receiving location is a web service implemented in Go, the routing is a message queue - I will use RabbitMQ, and the transformation and delivery is a Go application.
I will assume that the delivery protocol is HTTP, but this of course is a simple implementation question.
For the publish-subscribe pattern, the key requirement is the ability to subscribe to certain messages, qualifying which messages you want to receive - the routing.
For the ESB implementation, the key requirement is the ability to deliver the messages in a suitable format - the transformation.
Routing
To facilitate the subscription, messages should be accompanied by descriptive metadata upon which the subscription filtering may be built. It is my experience that the most important metadata are the source system and the message type, but all kinds of other qualities of the messages may be interesting for a subscriber, like the message age, subsystem information or even more specific metrics.
It may sound strange that the source system is an interesting property, but while source systems should not care or know where their messages go, it is very common for consuming systems to care about where their messages come from: Integrations are often driven from the destination end, out of their need to know what is going on in another system. Thus the natural language message filter is often similar to “what is it and where does it come from?”.
Although it may sound so, this does not conflict with the abstraction. The abstraction is instituted by the message type always looking the same - so orders coming from two different stores should have the same format. (As mentioned, the ESB may preprocess messages to obtain this, but this is beyond the scope of this article). From an operational point of view, the source system events often define the interest of the destination system - and therefore is key in the routing. More on this later.

Example showing multiple subscribers to the same message
In my experience, ESBs are often created to distribute data between business systems like the CRM and ERP systems, ecommerce systems, manufacturing systems (MES), etc., and data warehouses. The message types often reflect significant business process events, like the creation of orders, payments, customers, products (SKUs), etc.
The events described here could be understood as being either master data events or transaction events. Typically, the later (orders, payments) are much more common than the former (customers, products), and this may be an indication of which flows to create first. It may be a pragmatic approach to align master data manually first and then implement the transactional flows. Then later, it may be evaluated if it is worth implementing master data flows.
You may argue that the message type is a far too crude quality and that you need something more distinctive to determine if you want the message or not. Maybe you would like to know if for instance the order message is a new order, an order change or an order cancellation. This may well be so and of course needs to be considered in each case. My experience is, that often you will either get the entire order in the message or you will have to go get the entire order anyway, and the order will tell you if it is one you already know (by checking the unique order_ID), if it is cancelled (often by some order_status) and if neither of these are the case, it is a change - often best handled by deleting the existing order (if possible) and creating a new one.
One interesting pattern is to let the message be just an event notification consisting of the event type and the ID of the entity or entities involved. Then the granularity is the event type. However, this pattern will cause all consumers to fetch relevant data from the source system, which may cause excessive traffic (at least this should be considered if the source system is a SaaS application with limited traffic quotas).
In my experience, it makes for a simpler management (especially in large installations) to route on only the message type and do a further filtering in the consumer.
Keeping the subscription simple also may help make the implementation self-explaining: If i.e., as in our case, the routing is handled by RabbitMQ, you could have one exchange per source system, routing keys equaling message types and queues identifying source, destination and message type. So for instance, if you have orders issued in your web store and you are consuming these by your SAP ERP system, you would have an exchange called “webstore”, routing key being “order” and a queue called webstore-sap-orders.
Looking at the queues list in RabbitMQ would give you a very good idea about who is using data from where.
Transformation
Messages can take all kinds of forms and shapes, but the most common formats are JSON and XML. Similarly, the transport methods are many, but the overwhelmingly most common transport these days are HTTP - or HTTPS.
For a production scale system, you will probably want to add a version number to your API. You may want to allow varying levels of validation of payloads or even introduce radical changes to your architecture. With a version number, you allow yourself to do all of this.
Example
I will use the considerations about metadata or routing keys above in a radical design of the web service methods. I will have it define a method that is called through a URL according to the following pattern:
HTTP://<domain>/<sourcesystem>/<routingkey>
Basically, it will allow POST calls of the following type (the service running locally):
The URL is self-explanatory - or should be. The body of the message will contain the actual message, the quote, invoice, payment detail, etc. The service will send the message onto an exchange in RabbitMQ, named after the source system (so salesforce, zuora, netsuite, sap in the examples) and add the routingkey as given in the URL (that is quote, invoice, payment and order in the examples).
The main point to doing this is that many SaaS systems implement some sort of event system, but not all of them are able to add header fields - which would be the natural place for the routing keys. Most systems are able to define a web hook address though - and possibly set up authentication, and with this schema, the routing becomes part of the web hook URL.
You could argue that the abstraction could be taken a little further, by letting the sourcesystem be represented in the scheme by its type, i.e., ERP, CRM, etc., so that the URL could be like: http://localhost/erp/payment or http://localhost/store/order. This would allow more similar systems to use the same exchange, for instance, if you have multiple web stores, they could deliver orders on the same exchange. This way, you could add a new source system without having to change the subscription filters. My experience is that it is of great importance to easily monitor message activities system by system and I cannot recommend this abstraction.
It will also allow many source systems/publishers to send messages to the same end-point:
To allow the source system to add more routing keys, a service responding to an API call according to this pattern could be implemented:
HTTP://<domain>/<sourcesystem> + a routing key header: “routingkeys”:”routingkeys string”. For simplicity, the header routing keys string might assume the same format as used by RabbitMQ: keywords separated by dots, max length 255 characters.
Using the Code
In the attached application files, you will find an implementation of the web service and a simple consumer that does not do any transformation. I will return to the message format and transformations in a later article. With a vanilla RabbitMQ installation on your computer, it should be simple to run the two go applications and see exchanges and queues get created with incoming messages, as well as the consumer actually retrieving the message from the queue.
I’m sure both go scripts can be optimised, so there is still plenty to do!

