In this article, you will see how to use machine learning algorithms to train network models to recognize patterns and trends reflected in Bezier curve trajectories of student academic performance.
Visit Part 1: Data-Visualizations-And-Bezier-Curves
Introduction
I enjoy working with longitudinal data. This is the second article in a series about using Bezier curves to smooth large data point fluctuations and improve the visibility of the patterns unfolding. This current article focuses on using machine learning algorithms to train network models to recognize patterns and trends reflected in Bezier curve trajectories of student academic performance.
Background
This demonstration features ALGLIB, one of the better available numerical analysis libraries for C# programmers that offers several easy-to-use machine learning methods. (Later in this series, we will examine MS CNKT for C# routines.) ALGLIB for C# is available and licensed appropriately as a free, single-threaded edition for individual experimentation and use or as a commercial, multi-threaded edition for purchase. For this demonstration, I will explain at some length how to download and build the free edition as a class library that will need to be included as a reference for the demonstration program to work. For reference, you can go to the ALGLIB Wikipedia page for a description and history, the ALGLIB website for download information and an excellent on-line User’s Guide, and to the download itself for a detailed User’s Manual in .html format.
Working with ALGLIB
The first thing to do is visit the ALGLIB website, examine the news and User’s Guide (particularly the chapter about “Data analysis: classification, regression, other tasks”), and download the free edition of ALGLIB 3.14.0 for C# (released 6/16/2018) as a ZIP file. Unzip and open the application folder which should be entitled “csharp.” Among the list of contents of this folder is a file entitled “manual.csharp.html.” This contains detailed narrative, method descriptions, and example code snippets useful to anyone who wishes to utilize this library. A second item of interest in the csharp folder is a subfolder named “net-core” which contains an alglibnet2.dll library and another subfolder named “src” containing source codes. Individual parts of ALGLIB can be extracted for direct inclusion into programs (to save space, etc.). I prefer building my own complete library from the sources. To do that, follow this walk-through:
- Open Visual Studio and open a new Class Library (.NET Framework) C# project.
- Name the project ALGLIB314; select a location for saving the project folder; set the framework to be .NET4.7; click Create Directory for Solution checkbox; and click the OK button.
- When the project opens, in the Solution Explorer, right-click on the Project Name and select the Add: Existing Item options.
- In the Add Existing Items window, locate the downloaded csharp folder; open it; open the net-core subfolder and its src subfolder. There, select all of the .cs files listed and click ADD to bring copies of these into your new
ALGLIB314 project. - Next, in Visual Studio, select Release and Any CPU and then use the menu bar to choose the Build: Build Solution option to build a complete ALGLIB314.dll library.
- NOTE: The previous step will fail, yielding two errors in the output ERROR LIST pane referring to lines 11 and 12 in the project’s AssemblyInfo.cs file. To correct this, click on one of the error lines to open that file and simply comment out those two lines and save that file. (This is because the very same information is provided already in the alglib_info.cs file).
- Now, click the Build: Rebuild Solution menu option again to create a release version of the ALGIB314.dll file. This time, the process will succeed.
- Finally, change Release to Debug and click Build Solution again.
- Now you have both Release and Debug versions of the complete ALGLIB314.dll library (and its associated .pdb file for debugging) in your project’s BIN folder. This library can be added later to other projects as a reference.
- Save your class library project and close the solution.
- This would also be a good time to copy the manual.csharp.html file in the csharp folder and paste that copy into the top level of your new ALGLIB314 project folder for future reference.
Data Characteristics
The previous article in this data visualization series, entitled Data Visualizations And Bezier Curves, was about modeling data with Bezier curves. We looked at curve-fitting, time-domain point evaluation and plotting, and differentiation. You may wish to review that article. Again, it should be emphasized that here, we are discussing longitudinal data that moves from a starting point (along a Time or X axis) to an ending point, without loops, cusps, or backtracks. Once again, as examples, we will use student academic performance over time from grades 6 through 12. In this current article, we will discuss building machine learning classification models and using those to recognize various patterns, such as trajectories that identify students who appear to be doing well or are likely to be at-risk.
Here, we will use another small sample (N=500) of school marking period grade point average (MPgpa) student performance histories in core coursework. MPgpas are bounded from 0.00 to 4.00 on the grading scale. This is a simulated sample drawn from a MonteCarlo version of a large multi-state, multi-school district, thoroughly de-identified research database. (See the previous article for a fuller description of the data source.) In that research, a much larger sample of student histories (from the point of entry into middle school through the end of the 8th grade) were individually modeled by Bezier curves using a curriculum timeline, examined, and classified to form a large data set for machine learning.
Each curve was classified either as:
- indicating a relatively successful academic history up to the status estimation point (9.0, end of middle school) on the curriculum timeline;
- as possibly at-risk due to a falling MPgpa pattern below 2.0 on the grading scale;
- still at-risk but exhibiting a rising MPgpa pattern toward or slightly above 2.0; or
- seriously at risk of academic failure, a pattern trending below 1.0.
Our small demonstration data set was built by selecting pre-classified student histories at random, while insuring a balanced set of demo data representing each status group. (Actual data is not "balanced" this way. Fortunately and typically in public schools, there are several times more students who appear "academically successful" than student who appear "at-risk.")
Using the Code
In this “BezierCurveMachineLearningDemo” project written in C# using Visual Studio 2017 and .NET 4.7, we first read a data file and construct student histories, defined as lists of DataPoint tuples (time, MPgpa). The collection of data records is then shuffled randomly.
From each student history, a sub-history (from the time point of entry into middle school through the status estimation point of 9.0 marking end of 8th grade) is extracted. Associated with each sub-history is a pre-classified status value.
Next, a Bezier curve is fitted to model each student sub-history. That smooth Bezier curve itself is modeled by extracting a list of 24 MPgpa values at equal time intervals from the starting point to ending point, inclusive. 24 points appear to be sufficient to model these Bezier curves of academic performance which seldom exhibit more than two or three frequency cycles over the curriculum timeframe.
ALGLIB machine learning methods require data to be in the form of a double[,] array of rows of features, followed by a label. The 24 points describing a Bezier curve pattern form the features in this demonstration. The pre-classified status value (0, 1, 2, or 3) becomes the label (because in ALGLIB, labeling starts at 0). The data then is divided into training and validation data sets (based on a user-defined allocation percentage) for ready access.
Download the project and open the solution file in Visual Studio. In the Solution Explorer, right-click on the project references folder and delete any existing reference to the ALGLIB314.dll library. Then use the Add References option to locate and add the release version of ALGLIB314.dll library (that you created above) to the project. Then click Start to build and run the application. The solution requires three packages (MSTest.TestAdapter.1.2.1, MSTest.TestFramework.1.2.1, and System.ValueTuple.4.3.1) which should download and restore automatically.
A WinForm should open with a listbox, a chart, a datagridview, and a few buttons. The listbox will tabulate the machine learning process as it unfolds. The chart shows this unfolding process as a visualization. When network training completes, a brief summary is provided in the listbox and a more detailed cross-tabulation of training results is presented in the datagridview. For this demonstration, menu options are provided to select the type of network model to be trained (a neural network or a decision forest), the percentage of the data used for training, and whether the labels will be binary (0, 1) or tertiary (0, 1, 2, 3). Other controls on the form are used for starting the training process, running the validation test, saving the form image, saving the trained model, and closing the application.
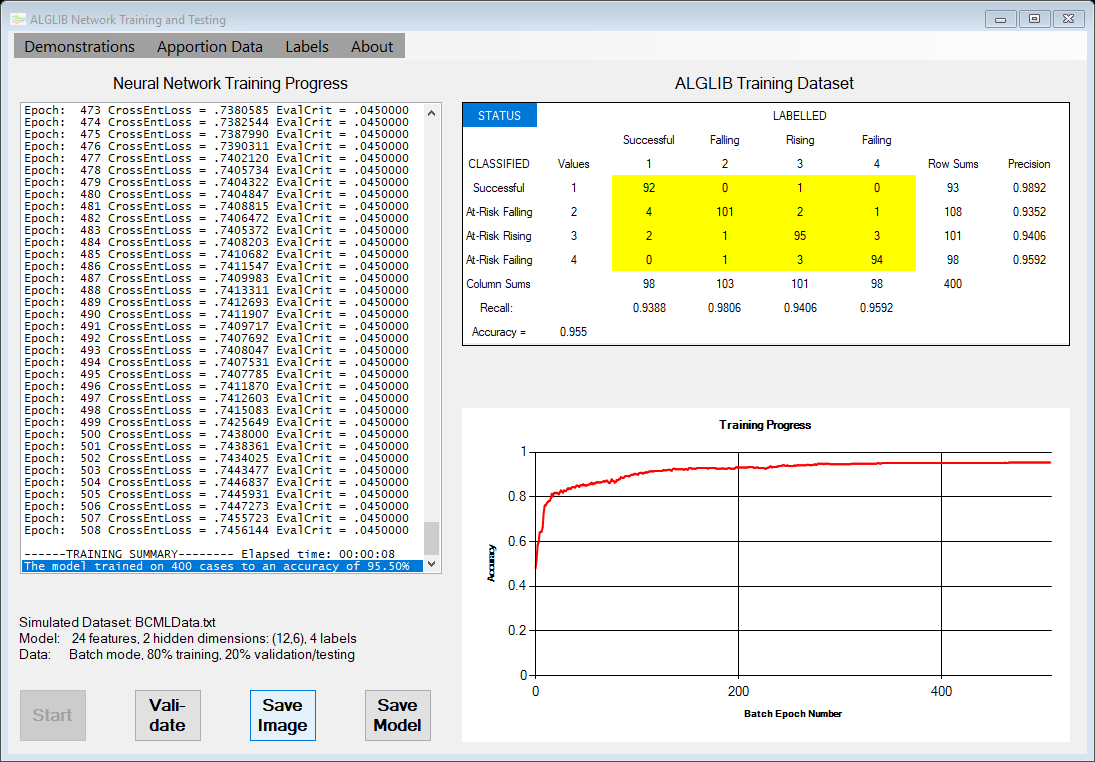
Points of Interest
The application provides a Demonstrations menu with two options: one selects a neural network to be trained as the classification model. The other illustrates training a decision forest model for the same purpose. Select a model and click the Start button to run a new analysis.
Much if not most of the code is unremarkable, for building the form and the demo User Interface and for creating and manipulating the dataset. However, the most important methods are those that call the actual machine learning processes implemented by ALGLIB. The ALGLIB API is very similar for both types of model. For instance, this is the NeuralNet code block in the demo that defines and implements a (24:12:6:4) neural network that has been shown to be adequate for classifying Bezier curves representing academic performance.
class NeuralNet
{
private static alglib.multilayerperceptron network;
private static alglib.mlptrainer trainer;
…
private static double relclserror;
private static double accuracy;
public static void RunExample1()
{
int Nfeatures = Form1.rdr.NofFeatures;
int Nlabels = Form1.LabelCategories == LABEL.Binary ? 2 : 4;
…
alglib.mlpcreatetrainercls(Nfeatures, Nlabels, out trainer);
alglib.mlpsetdataset(trainer, Form1.rdr.GetTrainingData, Form1.rdr.NofTrainingCases);
alglib.mlpcreatec2(Nfeatures, 12, 6, Nlabels, out network);
alglib.mlpsetdecay(trainer, 1.0E-3);
RunStepTrainer();
TrainingSummary();
PredictStatus(Form1.rdr.GetTrainingData);
}
…
}
As you can see, a trainer is defined by the number of features and number of label values, one of which might appear in each case record. A training set of records forms the dataset presented to the trainer. A network is defined, in this case by a 24 node input layer for the 24 points describing a Bezier curve, two hidden layers – the first with 12 nodes and the second with 6 nodes, and an output layer with 4 or 2 nodes for tertiary or binary classification. ALGLIB then offers several run modes. One of those simply “autoruns” to completion before producing output.
private static void RunAutoTrainer()
{
…
alglib.mlptrainnetwork(trainer, network, 1, out alglib.mlpreport rep);
accuracy = 1.0 - rep.relclserror;
ShowReport(rep);
}
There is also a “step-wise” run mode that does produce intermediate output. This is the run mode used by this demonstration to update the tabular listbox information and the Training Progress chart visualization.
private static void RunStepTrainer()
{
int epoch = 0;
alglib.mlpstarttraining(trainer, network, true);
while (alglib.mlpcontinuetraining(trainer, network))
{
avgce = alglib.mlpavgce(network,
Form1.rdr.GetTrainingData, Form1.rdr.NofTrainingCases);
ssqerror = alglib.mlperror(network,
Form1.rdr.GetTrainingData, Form1.rdr.NofTrainingCases);
rmserror = alglib.mlprmserror(network,
Form1.rdr.GetTrainingData, Form1.rdr.NofTrainingCases);
relclserror = alglib.mlprelclserror(network,
Form1.rdr.GetTrainingData, Form1.rdr.NofTrainingCases);
accuracy = 1.0 - relclserror;
Charts.ChartAddaPoint(epoch++, (float)accuracy);
…
}
}
Once the model is trained, it is a simple matter to save it as a disk file and to reload that model into a different program for classifying new data records. ALGLIB provides network serialization and deserialization functions for this purpose, e.g.:
public alglib.multilayerperceptron network;
…
public static void SaveTrainedNeuralNetwork(string pathname)
{
alglib.mlpserialize(network, out string s_out);
System.IO.File.WriteAllText(pathname, s_out);
}
and:
public static void SaveTrainedNeuralNetwork(string networkPathName)
{
if (!File.Exists(networkPathName))
throw new FileNotFoundException("Neural Network Classifier file not found.");
string text = System.IO.File.ReadAllText(networkPathName);
alglib.mlpunserialize(text, out network);
}
In the demonstration, however, we already have the trained network in memory and can apply it first to the training set and later to the validation set, like so:
public static void PredictStatus(double[,] rundata, bool validationFlag = false)
{
double[] results = new double[4];
List<int> status = new List<int>();
List<int> predict = new List<int>();
int NofMatches = 0;
for (int i = 0; i < rundata.GetLength(0); i++)
{
alglib.mlpprocess(network,
Support.VectorRow(ref rundata, i, 1), ref results);
int pred = Array.IndexOf(results, results.Max()) + 1;
int actual = Convert.ToInt32(
Math.Round(rundata[i, rundata.GetLength(1) - 1], 0)) + 1;
status.Add(actual);
predict.Add(pred);
if (actual == pred) NofMatches++;
}
if (validationFlag == true)
{
accuracy = (double)NofMatches / rundata.GetLength(0);
ValidationSummary();
}
Support.RunCrosstabs(predict, status);
}
The crosstabs.cs module contains methods to display actual and predicted classification results in a “confusion” matrix format in the datagridview control in the WinForm, along with various precision, recall, and accuracy statistics. Readers interested in using that routine for their own purposes are referred to another CodeProject article entitled Crosstabs/Confusion Matrix for AI Classification Projects that I wrote some time ago.
Training and using a decision forest with ALGLIB is a process very similar to the coding above and the demonstration includes a DecisionForest class module that implements that model. (With this small training set, the DecisionForest model uses 24 features, 2 or 4 labels, 10 trees, and an r-value of 60% for node-splitting.) The demo also has menu options to change the percentage of data allocated for training and validating the models from 50% up to 100%. Another menu option recodes the pre-classified status Label variable for binary, rather than tertiary, classification (i.e., either (0) apparent success or (1) possibly at-risk). Manipulating these options has the expected effects. More training cases and fewer label values lead to better results. In previous research, using a much larger data set (N>14,000) and 60%/40% for training/validation, stable validation accuracies >.98 for Bezier curves have typically been achieved using these classification models.
Conclusion
The principal conclusion drawn from the first demonstration in this series was that Bezier curves can be very useful models for noisy longitudinal data collected at varying time or X-axis points. A second inference was that if models are good, then inferences about such models may be good as well. That demonstration illustrated many different student performance trajectories through their respective public school curricula. A question was raised whether these are indicators of relative success, at the end points or at “current” or intermediate points of interest, such as the transition point at 9.0 from 8th grade middle school into 9th grade and high school.
By looking at the actual or the Bezier curve smoothed data, educators can make decisions about whether or not particular students may be academically “at-risk” (and thus may benefit from additional support services). This is how a pre-classified data set was constructed for this demonstration. However, suppose you need to make similar decisions about 100’s or 1000’s of students in real time (e.g., at each marking period) as each individual progresses through his or her curriculum? School counselors do that sort of thing every day, mostly without the availability or the use of such data. A machine learning model that could classify performance trajectories in various ways would surely be a beneficial tool for data-driven decision-making.
This article is an example of how to use machine learning algorithms to train classification network models to identify Bezier curve trajectory patterns reflecting student academic performance trends. The focus was on numerical methods provided by ALGLIB, but the same thing can be done using MS CNTK for C# or using TensorFLow or KERAS for Python. I think that kind of cross-model verification/validation is always an important and useful step. That next article in this series will look at that.
Schools and school districts constantly gather data using commercial student information systems (SIS). But this “raw” information is seldom accessible. Once a trained model is in hand, dashboards and other visualization methods can access that data, analyze it, and present educators with decision-making tools for individual or aggregated cohort analyses in real time. These perhaps are topics for future articles in this series.
Beyond that, this project presents a variety of useful techniques and methods for working with Bezier curves and for training machine learning models to recognize patterns and trends reflected by such curves that can be adapted for other similar projects.
History
- 22nd August, 2018: Version 1.0

