In this article, we will demonstrate how to create a Python web-application using Flask and PostgreSQL server, and run it in Docker virtualization platform environment
Note: You can evaluate the ready-to-use web-application being discussed in this article by visiting http://ec2-18-191-184-232.us-east-2.compute.amazonaws.com/.
Introduction
In this article, we will demonstrate how using Docker will help us to create and deploy a simple web application, using Python programming language and Flask development framework. The application we’re about to discuss in this article, performs a simple visualization of data, stored in PostgreSQL server database. In particular, as an example, we will create an application designed to perform an indexed search of persons and their phone numbers specific data, by a partial match, stored in the phonebook database. To create the following application, we will use Microsoft Visual Studio 2017 Python development tools. Later on, we will “dockerize” the following web application by running it in the Docker’s virtual environment.
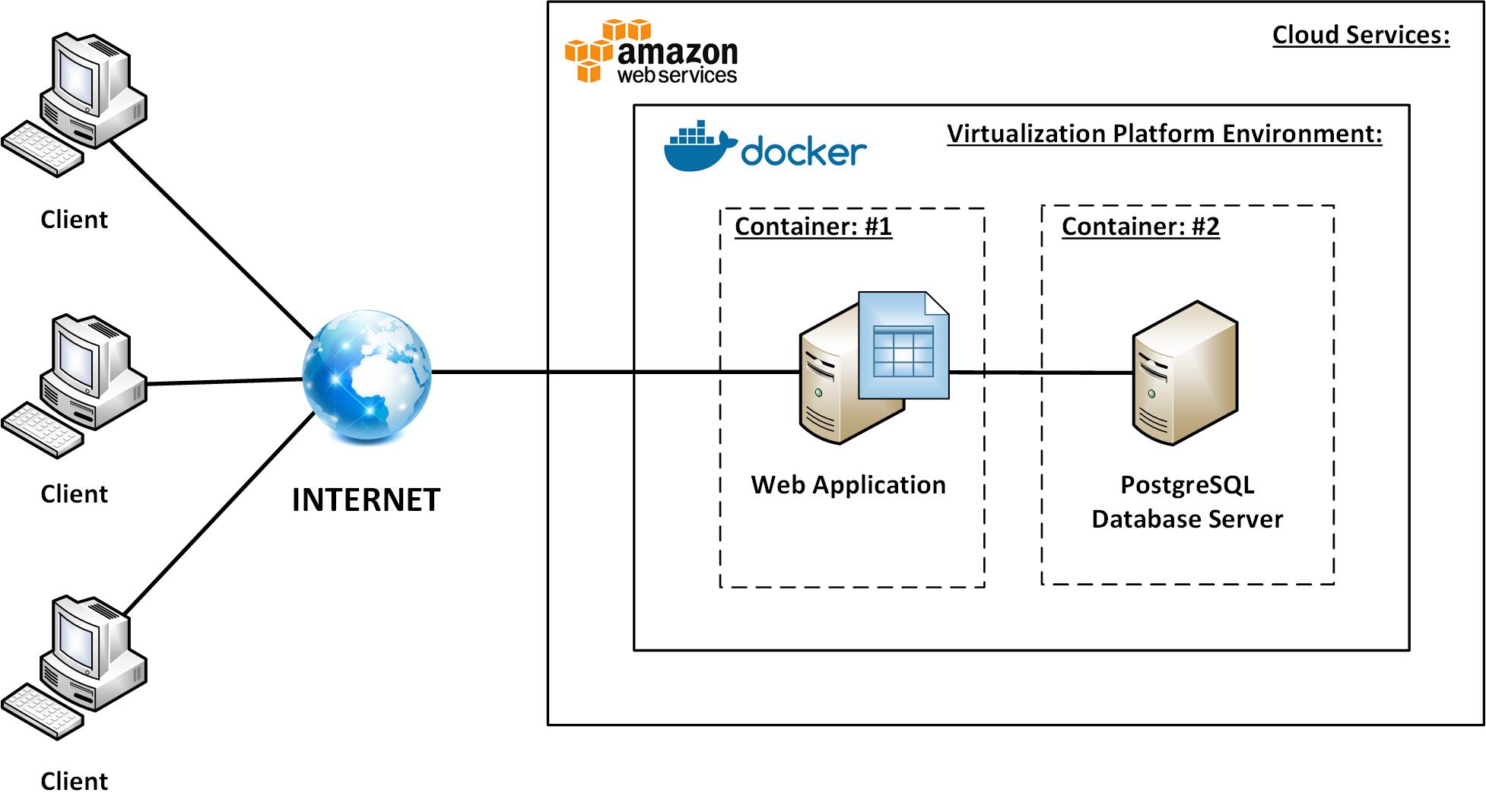
Throughout, in this article, we will provide the useful guidelines to setup and configure the Docker’s virtualization platform, and, then, use it to deploy various business-critical applications, providing services for the large number of customers over the Web. In particular, the audience of this article’s readers will find out, specifically, how to deploy an existing web application being created, running it in the Docker’s virtualization platform environment.
What’s Docker…
Docker is a SaaS-oriented operation-system-level virtualization platform, that allows to quickly and easily create and deploy various business web applications without either a deep expertise and knowledge of the virtualization technology (VT), or a large cloud services (CS) deployment experience. According to its architecture, Docker’s virtualization platform allows to deploy and use various applications as separate ‘containers’ running under a single MobyLinuxVM virtual machine instance, inside the Microsoft Hyper-V hardware virtualization platform:

The main idea of using containers (e.g., ‘containerization’) is that each service or application deployed in Docker’s virtual environment is running isolated, in its own container.
A ‘container’ is actually a minimalistic virtual machine hosting Windows or Linux operating system, normally used to deploy a particular application or network service, such as HTTP-, FTP-, NTP-, DNS-, database and others. In turn, Docker’s infrastructure provides repositories for creating containers running a specific service or application, from templates, making it possible to deploy those services and applications faster and easily. The using of container templates ensures that we’re deploying a virtual machine host already running a particular application or service without spending time for accomplishing infrastructure-specific maintenance tasks, such as installing host’s operating system, setting up and configuring an application or service daemons, creating virtual networks, monitoring performance, etc. This makes it easy and convenient to deploy various basic and even more advanced services and applications from ‘scratch’.
As we’ve already discussed, by using Docker’s virtualization platform, unlike the other IaaS-based cloud services and platforms such as Amazon EC2, Microsoft Azure, or OpenStack, the developers might no longer take care of accomplishing IaaS-specific application maintenance tasks. In the other words, the entire infrastructure-specific configuration process is very simple, since it’s wrapped up by the Docker’s virtualization platform. Specifically, each container within Docker’s environment is connected to a single network, providing the communication between the containers hosted and running in Docker’s environment. For example, a business application written in Python and running in its own container can access the data in PostgreSQL server database instance, running in the other container, over the Docker’s pre-configured virtual network. Also, while creating Docker’s containers, we no longer need to perform the initial configuration of each container, such as setting up the amounts of virtual system memory used by a virtual machine being created, the number of CPUs, virtual network adapters configuration, etc.
Specifically, in this article, we will learn how to:
- install and configure Docker’s virtualization platform on a host machine
- migrate the existing Python web application, introduced in this article, to Docker virtualization environment by creating separate Docker container
- deploy the other services such as PostgreSQL server instance to Docker from the specific template
- build the web application created and run it detached, as the Docker’s background service
Finally, we will learn how to deploy Docker virtualization platform environment, hosted by Amazon Linux AMI virtual machine instance, in the Amazon EC2 cloud, to provide a public access to the web application created.
Background
In this section, we will thoroughly discuss the process of dockerizing the indexed search web-application, introduced in this article.
Installing and Configuring Docker Virtualization Platform
The first thing that we have to do, before we deploy web-application to Docker, is to install and configure Docker virtualization platform. In this article, we will harness the capabilities of Amazon EC2 cloud services to install and run Docker hosted by Amazon Linux AMI virtual machine instance.
For that purpose, we must create an Amazon EC2 account and log in to create an instance of Amazon Linux AMI virtual machine, as it’s shown in the figures below:
During these steps, we must create Amazon EC2 account, log into the AWS Management Console and launch the Amazon Linux AMI instance. To create an instance of Amazon Linux AMI, we must make sure that we pass the following steps:
Step 1: Choosing Amazon Virtual Machine Image
Step 2: Choosing an Instance Type and Launch an Instance
Step 3: Creating an RSA-Key Pair to Establish a Secure SSH-Connection to the Running Instance
Step 3: Launch Amazon Linux Configured Instance
Step 4: Configuring the Running Amazon Linux Instance Security Group
To make sure that our web application being deployed accepts traffic by listening on a specific TCP-port, we must properly configure the security group by adding the specific inbound rule (e.g., HTTP-80 port) to the following security group as it's shown in the figures below:
Step 5: Connecting to the Running Amazon Linux Instance using PuTTY Terminal App
As you can see in the figure shown above, the running instance of Amazon Linux AMI was successfully created and Public DNS (IPv4) hostname has been generated. Later, we will use this hostname to connect to the running instance's SSH-console by using PuTTY terminal application.
To do this, we have to download and install PuTTY and generate a specific *.ppk file from the key-pair *.pem file previously created during the instance configuration phase:
For that purpose, we will use PuTTYGen utility as it's shown in the figure above:
After we've created and save a new key-pair *.ppk file, let's now make our first connect to the running Amazon Linux instance console by using PuTTY terminal as it's shown below:
To connect to the running instance of Amazon Linux, we will use the following credentials, for example: hostname: ec2-18-191-184-232.us-east-2.compute.amazonaws.com, and *.ppk key-file previously generated:
Step 6: Installing and Configuring Docker
Since we've already launched and configured Amazon Linux AMI virtual machine and connected to its SSH-console, the next step is to deploy Docker's virtualization platform to the running instance of Amazon Linux. To do this, we need to use the following commands in SSH-console.
Before we begin, let's make sure that we're logged onto the SSH-console as a super-user or root. To enable root account, we have to use the following commands such as sudo passwd root and enter a root password. After that, log in to the console as 'root' by entering the following short command: su.
To install Docker, we must enter the following sequence of commands:
[root@ip-172-31-20-4 ec2-user]# yum update -y
[root@ip-172-31-20-4 ec2-user]# yum install -y docker
The entire Docker installation process is illustrated in the figures below:
After we've successfully installed Docker, we need to make sure that it will be running as services after the next boot. For that purpose, we need to enter the following commands:
[root@ip-172-31-20-4 ec2-user]# chkconfig docker on
[root@ip-172-31-20-4 ec2-user]# service docker start
After that, we must reboot our instance of Amazon Linux AMI to make sure that Docker will run automatically at the next boot. To do this, just type in: shutdown -r now.
Finally, we must ensure that the Docker virtualization environment works as just fine. To do this, we must run a hello-world Docker application from the repository:
[root@ip-172-31-20-4 ec2-user]# docker run hello-world
Step 7: Creating PostgreSQL Service Container
To deploy our web-application, the first thing that we must do is create a Docker container of pre-configured instance of PostgreSQL server from a template. To do this, we have to perform the following steps: create a container for PostgreSQL datastore by entering the following command:
docker create -v /var/lib/postgresql/data --name PostgresData alpine
Next, we have to create a container of pre-configured PostgreSQL server:
docker run -d -p 5432:5432 --restart=always --name postgresql_ec2
-e POSTGRES_PASSWORD=12345 -d postgres
As an alternative, we can assign a static IP-address to the running PostgreSQL container by executing the following commands:
To create a custom Docker's virtual network, enter the following command:
docker network create --driver=bridge --subnet=178.17.0.0/24
--gateway=178.17.0.1 postgresql_ec2_nw
To run the PostgreSQL container in the custom virtual network created, use the following command:
docker run -d -p 5432:5432 --name postgresql -it --network=postgresql_ec2_nw
--ip=178.17.0.2 --restart always --publish 5432:5432
--volume /srv/docker/postgresql:/var/lib/postgresql \
--env 'PG_TRUST_LOCALNET=true' --env 'PG_PASSWORD=12345'
--env 'DB_USER=postgres' --env 'DB_PASS=12345' --env 'DB_NAME=phonebook' postgres
Finally, to make sure that the PostgreSQL container is running, let's enter the following command:
docker ps -a
Step 8: Phonebook PostgreSQL Database Maintenance Steps
After we've successfully setup the PostgreSQL database server container, we must import a ready-to-use database to the PostgreSQL server. To do this, we must additionally install vsftpd ftp-server on the running instance of Amazon Linux. After we've installed the ftp-server, we must copy the files shown in the figure below to the /home/ec2-user directory of our Amazon Linux instance:
After that, we must copy the phone_book.sql file to the PostgreSQL container. To do this, we have to use the following command:
docker cp ./phone_book.sql postgresql_ec2:/home/phone_book.sql
After we've successfully copied the following file to the PostgreSQL container, we must import the following dump to the database server and create the phonebook database with data. To do this, we must log into the container console by using the following command:
docker exec -it postgresql_ec2 /bin/bash
To import the existing database, we have to enter the following two commands:
psql -U postgres
, and then type in CREATE DATABASE phonebook; sql-statement, after which the new phonebook database is created.
psql -U postgres -f /home/phone_book.sql phonebook
After entering this command, the phone_book.sql dump file is successfully imported to the newly created phonebook database.
Step 9: Building and Running Indexed Search Web Application
After we've successfully maintained the PostgreSQL database server and imported the phonebook database with data, now, let's build and deploy our indexed search web-application. First, what we have to do is create an appropriate Docker file as follows:
FROM python:3
WORKDIR /eg_phonebook
ADD . /eg_phonebook
RUN pip install --trusted-host pypi.python.org -r requirements.txt
RUN pip install pystrich psycopg2-binary requests
EXPOSE 80
CMD [ "python", "./eg_phonebook.py" ]
In this file, we must specify the repository (e.g., FROM python:3) from which we will be downloading and importing python-packages. Also, we must provide a working dir of our application (e.g., WORKDIR /eg_phonebook) and python main application's filename (ADD . /eg_phonebook). Also, we will be using the RUN wrapper command to execute Python's pip utility that allows us to download and install additional Python-modules:
RUN pip install --trusted-host pypi.python.org -r requirements.txt
RUN pip install pystrich psycopg2-binary requests
Finally, we must provide a TCP-port on which the eg_phonebook app will be listening on. At the bottom of the Docker file, we must execute CMD command that is used to build our Python web-application by building a specific main application's file (e.g., CMD [ "python", "./eg_phonebook.py" ]).
Finally, after the Docker file has been created, we must enter the following commands to build our eg_phonebook web-application:
docker build -t eg_phonebook .
To run the application, we will use the following command:
docker run -d -p 80:80 --restart=always eg_phonebook
After executing this command, the following web-application will run as service at the background and listen on TCP-port 80.
Optionally, we can stop and remove the running containers by using these commands:
docker stop <container-id>
docker rm <container-id>
To verify if the applications works as just fine, let's go to the web-browser and enter the following URL-address:
http://ec2-18-191-184-232.us-east-2.compute.amazonaws.com:80/
As you can see in the figure above, the following web application has started and is ready to work.
Using the Code
As an example of the web-application deployed to be run in Docker virtualization environment, we've created an application that performs an indexed search of persons and phone numbers data stored in PostgreSQL database, by a partial match. The following application is intended to visualize the search results organized into a table rendered in the web-application main page.
The application's main web-page HTML-document is listed below. The following HTML-document renders a table of persons and phone number that exactly or partially match the search pattern, and is constructed dynamically by the app's main Python-script. The following HTML-document contains the fragment of JavaScript code that performs HTTP Ajax-requests to the applications web-server and retrieves data on persons and phone numbers based on the query transaction to PostgreSQL server database, performed by the app's main Python-script. The response normally contains the data organized as HTML-table, that, further, is dynamically emplaced and rendered as a portion of application's main web-page. Specifically, in the fragment of JavaScript code, we define doSearch() method inside of which we're performing an Ajax-request by creating XMLHttpRequest() object and defining the callback function to handle onreadystatechange event, fired after the request is completed. Inside the following function, we're obtaining the response text of the Ajax-request, and performing the emplacing of the HTML-table returned by the app's Python-script, to the app's main web-page, after the request has been processed. To send an Ajax-request, we normally construct a URL-string that consists of the application web-server address and a sequence of URL-parameters, such as /search?text=query_string. Specifically query_string value is retrieved from the editable text field by using document.getElementById("query").value property. After the URL-string has been constructed, we're invoking XMLHttpRequest().open method and pass the string being constructed as one of the arguments of this method.
The doSearch method is normally invoked as the result of onload, onkeyup, onclick events being fired by HTML-document's user input controls. For example, if a user starts typing a query string, the onkeyup event is fired and handled by doSeach function, obtaining the string value from the editable text field, sending an Ajax-request to the web-application's main Python-script being executed.
index.html
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script type="text/javascript">
function doSearch() {
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("result").innerHTML = xhttp.responseText;
}
};
xhttp.open("GET", "/search?text=" + document.getElementById("query").value, true);
xhttp.send();
}
</script>
</head>
<body onload="doSearch();">
<table border="0">
<tbody>
<tr><td align="center"><b>Docker's Indexed Search App v.1.00a</b></td></tr>
<tr>
<td>
<table border="0">
<tbody>
<tr>
<td>Search:</td>
<td><input id="query" type="text" onkeyup="doSearch();"
onpaste="doSearch();"></td>
<td><input type="submit" onclick="doSearch();"></td>
</tr>
</tbody>
</table>
</td>
</tr>
<tr><td><center><p id="result"></p></center></td></tr>
</tbody>
</table>
</body>
</html>
The application's main Python-script is executed every time the HTTP Ajax-request is sent by the specific JavaScript code embedded to the app's main web-page HTTP-document. During the following Python-script execution, we're instantiating the Flask and Redis objects and dispatch the app.run(HOST, PORT) method to launch the web-application on the server-side. While executing the following script, we're perform routing based on HTTP-requests being sent. Specifically, when processing the default route, we're constructing the HTML-document shown above as a string buffer returned by main_empty function. Otherwise, for the /search?text=query_string route, we're establishing connection to PostgreSQL databaser server, constructing and executing the query's SQL-statement such as SELECT person_id, person_name, phone FROM public.persons WHERE \ person_name ILIKE '%""" + search_pattern + """%' OR phone ILIKE '%""" + search_pattern + """%', the execution of which results in obtaining a set of rows that exactly or partially match the given search pattern. If the value of text-parameter of URL-string is empty, then we're executing another SQL-statement, that returns the set of all rows in the persons table.
After we've executed the SQL-statement, we're obtaining the resultant set of rows and generate an HTML-table, each row of which contains data on each particular person and phone number matching the search pattern. The HTML-contents being generated and stored into a string buffer, that, further, will be returned as a response to an Ajax-request being processed.
eg_phonebook.py
"""
This script runs the application using a development server.
It contains the definition of routes and views for the application.
"""
from flask import Flask
from redis import Redis, RedisError
from flask import request
import os
import socket
import psycopg2;
redis = Redis(host="redis", db=0, socket_connect_timeout=2, socket_timeout=2)
app = Flask(__name__)
wsgi_app = app.wsgi_app
@app.route('/')
def main_empty():
return "<html><head><script type=\"text/javascript\">function doSearch() \
{ var xhttp = new XMLHttpRequest(); xhttp.onreadystatechange = function() \
{ if (this.readyState == 4 && this.status == 200) \
{ document.getElementById(\"result\").innerHTML = xhttp.responseText; } }; \
xhttp.open(\"GET\", \"/search?text=\" +
document.getElementById(\"query\").value, true); \
xhttp.send(); } </script></head><body onload=\"doSearch();\"> \
<table border=\"0\"><tr><td align=\"center\"><b>Docker\'s \
Indexed Search App v.1.00a</b></td></tr><tr><td><table border=\"0\">\
<tr><td>Search:</td><td> \
<input id=\"query\" type=\"text\" onkeyup=\"doSearch();\"
onpaste=\"doSearch();\"></td>\
<td><input type=\"submit\" onclick=\"doSearch();\"></td></tr></table> \
</tr><tr><td><center><p id=\"result\"> </p></center>\
</td></tr></table></body></html>";
@app.route('/search')
def search():
search_pattern = request.args.get("text");
conn=psycopg2.connect(database="phonebook", user="postgres", \
host="172.17.0.2", password="12345")
cursor = conn.cursor()
pg_query_string = "\0";
if search_pattern != "\0":
pg_query_string = """SELECT person_id, person_name, phone \
FROM public.persons WHERE \
person_name ILIKE '%""" + search_pattern + """%' \
OR phone ILIKE '%""" + search_pattern + """%';"""
else: pg_query_string = """SELECT person_id, person_name, \
phone FROM public.persons;""";
cursor.execute(pg_query_string)
html = "<table border=\"0\">";
html += "<tr><th>#</th><th>Person Name</th><th>Phone</th></tr>"
row_id = 0
rows = cursor.fetchall()
for row in rows:
html += "<tr style=\"background-color:" + \
("#eee" if (row_id % 2) != 0 else "#fff") + "\">";
html += "<td>" + str(row[0]) + "</td>";
html += "<td>" + row[1] + "</td>";
html += "<td>" + row[2] + "</td></tr>";
row_id = row_id + 1;
html += "</table>";
return html;
if __name__ == '__main__':
import os
HOST = os.environ.get('SERVER_HOST', '0.0.0.0')
try:
PORT = int(os.environ.get('SERVER_PORT', '80'))
except ValueError:
PORT = 5555
app.run(HOST, PORT)
'phonebook' is a tiny database, containing just one table 'persons', having two fields of 'text' type such as 'person_name' and 'phone'. The SQL-dump of the 'phonebook' database, including constraints and data is listed below:
phone_book.sql
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
DROP DATABASE "phonebook";
CREATE DATABASE "phonebook" WITH TEMPLATE = template0 ENCODING = 'UTF8' _
LC_COLLATE = 'Ukrainian_Ukraine.1251' LC_CTYPE = 'Ukrainian_Ukraine.1251';
\connect "phonebook"
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
COMMENT ON SCHEMA "public" IS 'standard public schema';
CREATE EXTENSION IF NOT EXISTS "plpgsql" WITH SCHEMA "pg_catalog";
COMMENT ON EXTENSION "plpgsql" IS 'PL/pgSQL procedural language';
CREATE SEQUENCE "public"."person_id_seq"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
SET default_with_oids = false;
CREATE TABLE "public"."persons" (
"person_id" integer DEFAULT _
"nextval"('"public"."person_id_seq"'::"regclass") NOT NULL,
"person_name" "text",
"phone" "text"
);
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (1, 'John W. Smith', '+1(719)444-5555');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (2, 'Richard Stone', '+1(614)333-2211');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (3, 'Jeffry Wilkins', '+1(212)818-2236');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (4, 'William Travis', '+1(453)545-0390');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (5, 'Tony Creek', '+1(451)452-3311');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (6, 'Ronald Steward', '+1(718)959-4310');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (7, 'Collin Whitney', '+1(410)541-3456');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (8, 'Steven Cromb', '+1(461)553-4312');
INSERT INTO "public"."persons" ("person_id", "person_name", "phone") _
VALUES (9, 'Dave Blackstock', '+1(466)443-2228');
SELECT pg_catalog.setval('"public"."person_id_seq"', 9, true);
ALTER TABLE ONLY "public"."persons"
ADD CONSTRAINT "person_id_pk" PRIMARY KEY ("person_id");
Points of Interest
In this article, we've discussed an approach of creating and dockerizing a simple web-application, that can be also used to deploy the other applications, rather than the one introduced in this article.
History
- 21st August, 2018 - First version of article published

