Introduction
In my earlier article, I discussed the ESB routing mechanism, showed how to create a simple reporting framework for an ESB, and created the components needed in an ESB to demonstrate how much, or little, you need to get an ESB running. The intention is to do a pragmatic discussion of all parts of an ESB and uncover some of the factors that should guide your choices when you implement or refactor your implementation.
In this article, I will discuss the messages, their format and transformation. In a later article, I intend to do a broader discussion of homegrown vs. commercial implementations.
Messages
Messages in this context obviously are messages flowing from one system to another, or more specifically, messages that are somehow published from one system, and transformed to be consumed by one or more other systems. So as can be seen, there are already more than one messages in play to describe the same “transaction” and several factors should guide what these messages should, consequently, look like.
Formats
Messages may take all kinds of formats. Usually, however, the application designers of the source systems have chosen some standard to adhere to, to make things easier for themselves when creating messages, and not least easier for the consumers, who may know the format specification and thus may know what to expect. It takes a lot of selfesteem to do like, i.e., SAP and define your own format (idoc) and it is very difficult to see the benefits of doing so. In any case, the format of the published data is often defined by the limitations of the publishing system.
In most cases, systems are either able to produce json or XML formatted messages, and until something even better comes along, I would strongly recommend using one of these for transactional messages, and to stay away from custom formats if at all possible. Json and XML, both have the huge benefit of being self-explanatory and explicit in the sense that they are readable and readily understandable, both with respect to what the data is (if values have been given sensible names) and what types they are.
In other contexts, like more batch oriented integrations where large numbers of uniform messages are moved at regular intervals, the overhead of explicit formats like json and XML may not make sense, and a more compressed, less explanatory format like CSV files may be preferable - but this is not in scope for this discussion.
Similarly, the common methodology for a consuming system is to expose an API, a number of web services - SOAP or REST or both - and to have the body of these API calls be either json or XML. It is my impression that json is gaining significant way in the SaaS world at the moment. Some offer the choice between the two.
Json and XML are not equal, and while the discussion of choice between them have often taken a kind of religious twist, there are differences that are worth considering.
First and foremost, XML may be accompanied by a definition of the particular message type through an XSD, that is: a description defining the context in which the message should adhere to the definition, the structure of the message, which individual fields that may or must be there, their cardinality and datatypes and any additional properties. This is a definition created by the producer of the data, a description of what is delivered so to say. Based on this, it is possible to do a very strict validation of the message at hand. To some applications, XML is not valid if it is not accompanied by at least a namespace - an XML document/message type is uniquely defined by its namespace and its root element name. XML may however well be used in a more relaxed, namespace-free manner.
Json does not have any of this. It is leaner - a fact that may be the reason for its popularity - and it is very easy to read. However, it may still be possible to create a schema to describe what the json should look like. This sort of contract may be described in a RAML file, but in contrast to XML, this is often set up by the receiver of a message, to ensure that there are rules to what received messages should look like, and provide a means to reject messages that do not comply to the format.
Secondly, XML has standard tools to traverse, query and transform messages. XPath, XQuery and XMLT are each in their field very strong standard tools. In an ESB context, the XSLT transformation tool is of course of particular interest.
I think it is fair to say, that each of these tools have several, equally effective counterparts in the json world, but they are not standards, meaning that most developers will have a learning curve to negotiate, and if you hit a problem, there is often only limited knowledge out in the otherwise big Google world to help you.
Transformation
I guess that it sounds, at this point, as if I am an advocate for XML. I am not. I find json to be very nimble - its close resemblance to Java objects and easy transformation to Java and JavaScript objects, makes json very compelling in many contexts. In an earlier article, I have shown how you can use json at all points in a slim ESB implementation, and how to use a template based transformation tool, to do the transformation. This implementation is only rudimentary and mainly meant as inspiration, but it does outline a principle, and the use of a template tool may well be matured to enterprise level.
But I do think it is worth considering the strong points of these formats and how they relate to the ESB:
Json is simple and is widely supported (it's hard to find a programming language that does not implement some sort of json support), it is not necessarily tied to a format specification, yet it may be validated at the receiving end - in short, it lends itself well to the API/front end of an ESB.
XML on the other side, is extremely strong in transformation context. There is a standardised language to identify and find elements (XPath) and to transform entire documents (XSLT).
To make things even more interesting, there are lots of libraries out there to do completely generic transformations from json to XML (and vice versa). I think there is an interesting case in providing an API that receives json and translates this into XML. Then, from there, consumers may use XSLT to extract/transform into a relevant document, and if necessary, this document may be translated back into json before delivery.
(Notice that one of the structural challenges in translating XML to json - tag attributes - may be totally avoided in the scheme described).
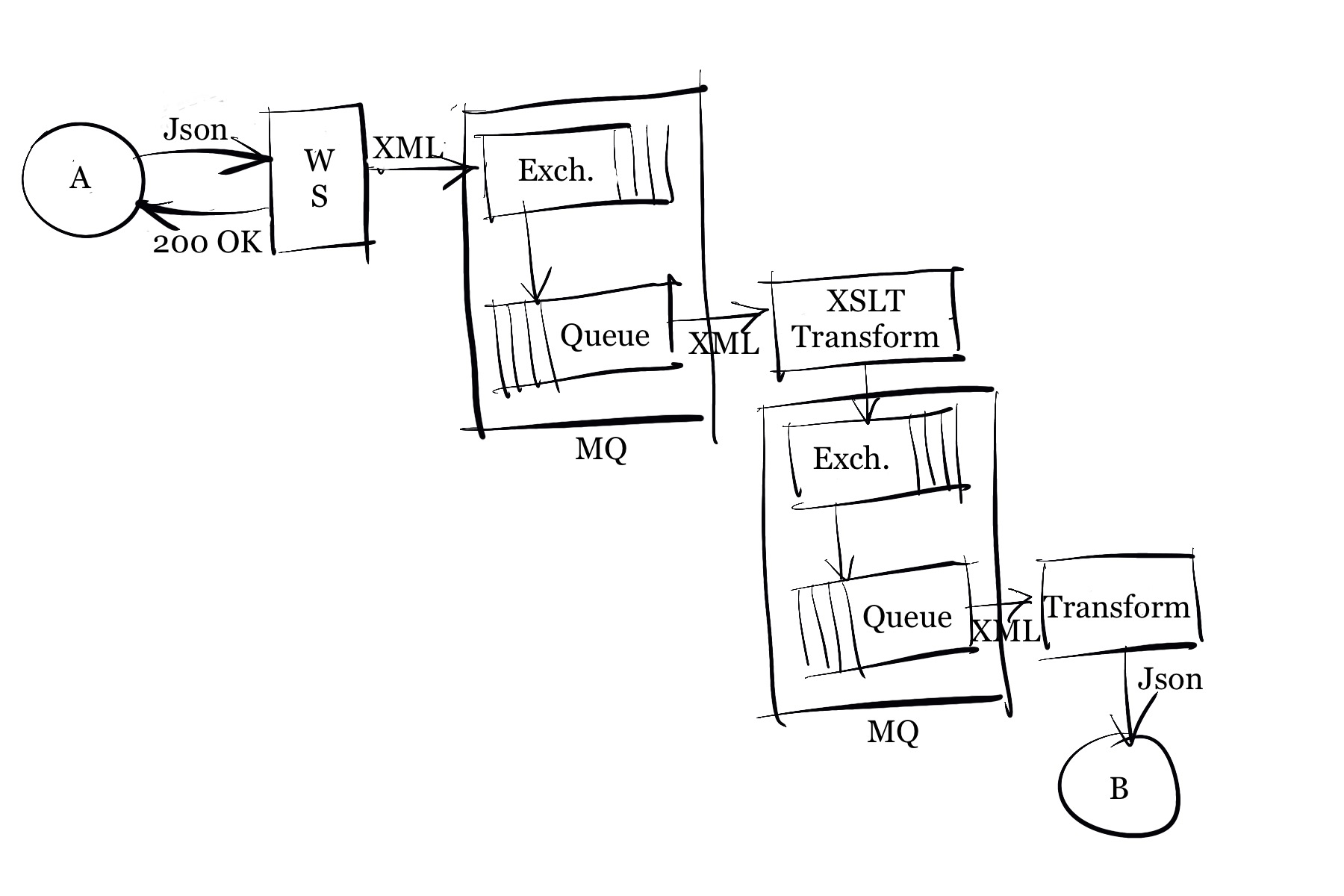
This, of course, was just a thought experiment, but I think one that has a lot to offer. It also implies that the developers are proficient in handling both json and XML though. The proposition however also touches on another common requirement: the need to have more steps in the processing of a single message. In the scheme described, all incoming messages would be translated into XML, then posted to the routing mechanism, i.e., to one or more exchanges in a Rabbit MQ. Each consumer would then translate the relevant (subscribed to) messages by means of XSLT. Finally, the XML document might be translated into json to deliver it to the destination system.
The simple thing to do to create these steps, is to post the message to the routing mechanism between each step. This gives an overhead of queues or channels or whatever, but it also gives a good insight into where things may be failing, and it provides excellent debugging opportunities.
A beauty about this entire design is that all components may be completely generic: The web service to receive the json messages and translate them into XML. The transformation is all the same, only the message and the XSLT are different, so this should be configurable in the instantiation of the consumer. And finally the translation from XML to json may again be generic.
Another interesting aspect is that each of the components could be considered an entirely separate application. Thus each application could be written in its own language (i.e., to leverage language specific libraries) and they could run on separate servers. For scalability, individual consumer instances might even run on separate servers, all it requires is that these servers have access to the message queue.
With these last comments, I’m approaching a different kind of discussion: the technology choice and configuration. I will address this in a later article.

