Introduction
This article is about the C# .NET implementation of the serverless OLAP engine that deals with an off-line data aggregation and processing. It is a Microsoft SQL Server dependent solution and based on that storage engine. The future work is targeting the flat data sources like the CSV files.
Background
The OLAP (Online Analytical Processing) is a well-known technique of performing an off-line processing of the information stored inside the database and aggregating of those data to be reported by the different parameters. It is explained on the following web page https://en.wikipedia.org/wiki/Online_analytical_processing. It is composed from the several parts:
- data extraction (E)
- data transformation (T)
- data loading (L)
- data aggregation and processing
- data reporting
This C# .NET dynamic class library is written in order to support the requested minimum for the successful data processing and reporting. For accessing the Microsoft SQL Server database schema, it uses the INFORMATION_SCHEMA in order to create "in-memory" database model. It collects the information about the tables, columns, primary and foreign keys, as also for the existing referential constraints. The DataCube functionality was tested on the Northwind sample database provided by Microsoft. The SQL script for populating this sample database is included in the project. This database contains the general information about the Products, Orders and Customers, as the main identities which are being processed. Please check the Northwind database schema below:
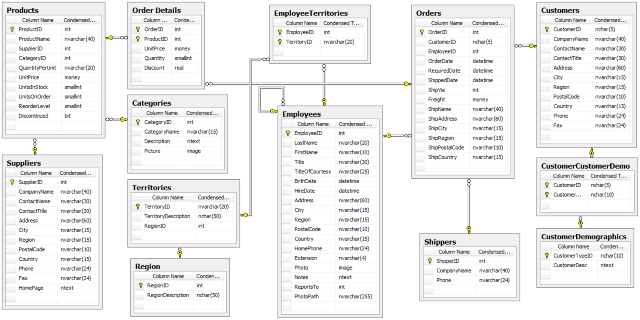
The DataCube Structure
The DataCube class library contains the following logical layers:
- database model
- multi-dimensional cube model
- data query module
Using the Northwind database as the test-case, here is how the DataCube library is used
(NOTICE: The DataCube.dll must be attached as the reference to the .NET project that is built.)
Modeling The Database
To create a DataCube object, use the following constructor:
DataCube.DataCube dataCube = new DataCube.DataCube
(@"NORTHWIND_DATACUBE", @"Server=localhost; Initial Catalog=NORTHWIND;
Integrated Security=SSPI", @"E:\\Firma\\NORTHWIND_DataCube\\", DataCubeType.DataCubeTypeMSSS);
The DataCube.DataCube constructor takes the following parameters:
- name of the datacube (
string) - database connection (
string) - server repository path (
string) - datacube type (enumerable of the
DataCubeType type - the only supported values for now is DataCubeType.DataCubeTypeMSSS)
Next, the following method is called in order to create an "in-memory" model of the database:
dataCube.Model();
Now, the database model is loaded into the memory and can be used for further data processing.
Modeling the Cube
The Cube is a multi-dimensional array that holds the pre-aggregated information from the database. It is made of the following:
- dimensions
- facts
- hierarchies
The Dimension is formed from the selected table from the database. In this example, we will create four different dimensions, please check the code below:
DataCube.Dimension dimensionCustomers =
new DataCube.Dimension("Customers", new string[] { "CompanyName" });
dataCube.Dimensions.Add(dimensionCustomers.Name, dimensionCustomers);
DataCube.Dimension dimensionEmployees =
new DataCube.Dimension("Employees", new string[] { "FirstName", "LastName" });
dataCube.Dimensions.Add(dimensionEmployees.Name, dimensionEmployees);
DataCube.Dimension dimensionProducts =
new DataCube.Dimension("Products", new string[] { "ProductID", "ProductName", "UnitPrice" });
dataCube.Dimensions.Add(dimensionProducts.Name, dimensionProducts);
DataCube.Dimension dimensionCategories =
new DataCube.Dimension("Categories", new string[] { "CategoryName" });
dataCube.Dimensions.Add(dimensionCategories.Name, dimensionCategories);
The DataCube.Dimensions object is a "named collection" - the .NET Dictionary object type. The DataCube.Dimension constructor takes the following params:
- name of the dimension (
string) - array of the columns (
string[])
The dimension name is the actual name of the table from the database. The array of the columns is the array holding the unique name of the columns from the same table. In the previous example, we have created the four dimensions: Customers, Employees, Products and Categories.
The Fact is formed also from the selected table from the database. In this example, we will create only one fact, please check the code below:
DataCube.Fact fact = new DataCube.Fact("Order Details");
DataCube.Measure measureQuantity =
new DataCube.Measure("Quantity", DataCubeFactAggregationType.DataCubeFactAggregationTypeSum);
fact.Measures.Add(measureQuantity.Name, measureQuantity);
DataCube.DerivedMeasure measureSales =
new DataCube.DerivedMeasure("Sales", DataCubeFactAggregationType.DataCubeFactAggregationTypeSum,
"UnitPrice * Quantity * (1 - Discount)");
fact.DerivedMeasures.Add(measureSales.Name, measureSales);
dataCube.Facts.Add(fact.Name, fact);
The DataCube.Fact object is created on the transaction tables "Order Details". This database table keeps track of the Products, of different Categories, sold to the Customers, by the Employees. Each DataCube.Fact object has a different DataCube.Measure objects that are being processed and calculated in the later steps. As the "Order Details" table has the Quantity and the UnitPrice, as also the Discount column, we create the exact measures we need.
The DataCube.Measure object constructor has the following params:
- name of the measure (
string) - type of the data aggregation (enumerable of the
DataCubeFactAggregationType type)
There are five basic aggregation functions supported: SUM, COUNT, MIN, MAX and AVG.
If there is a need to define a pre-calculated column, like we need a Sales column here, we should create the DataCube.DerivedMeasure object. The additional parameter in its constructor is the expression that is used to calculated its value, like here where the Sales = UnitPrice * Quantity * (1 - Discount).
For basic data processing, most of the work is finished here.
Processing the Cube
In order to get the desired data processing results, we need to have the data aggregated and processed. Please check the code below:
dataCube.Process();
As an output of the previous step, the repository will be filled with the corresponding XML files that represent the processed data.

Here is the inner structure of the generated XML file, Categories.xml:
This XML file has the schema written together with the data. The data is contained inside the elements which tag name matches the dimension name. It is easily loaded inside the .NET DataTable object for later processing. The original type of the data (the column data type) is saved inside the XML schema. All processed dimensions generate the identical output file. Also, the data inside the Fact is aggregated and calculated for every single Dimension value.
Here is the actual SQL query that is automatically generated:
And, here are the results from the execution of the upper SQL query:
At this point, we might want to save the created Cube for later processing.
Saving the Cube
In order to save the Cube, please check the code below:
dataCube.Save();
This action will generate the XML file at the repository by the name of the Model.xml. Here is the inner structure of this file:
This file keeps track of the dimensions and facts created inside the DataCube object. Once the Cube is saved, after processing of its dimensions and measures, it can be loaded again off-line. No connection to the database is needed any more.
Loading the Cube
To load the Cube, check the following code:
DataCube.DataCube dataCube = new DataCube.DataCube("NORTHWIND_DATACUBE", null,
"E:\\Firma\\NORTHWIND_DataCube\\", DataCubeType.DataCubeTypeMSSS);
dataCube.Load();
This constructor has already been explained, but this time, it is important to see that there is no more a database connection string provided. The Load() method will load the Cube from the repository, if there is an existing Model.xml file.
Querying the Cube
To perform a data analysis, we will have to query the data that is processed by the DataCube object. The DataCube.Query class has been written for this purpose. I have tried here to mimic the MDX query logic, and provide the actual data pivoting, in order to represent the data similar to the OLAP clients, like the Microsoft Excel is. So, from this point, we are processing and analysing the off-line data that is stored inside the XML output files generated from the processing of the dimensions and facts. Check the code below:
DataCube.Query query = new DataCube.Query("Test", new string[]
{ "Categories.Categories_CategoryName" }, null, new string[] { "Quantity", "Sales" },
"Categories_CategoryName IN ('Produce', 'Seafood')");
The DataCube.Query object constructor has the following params:
- name of the query (
string) - array of row dimensions (
string[]) - array of column dimensions (
string[]) - array of measures (
string[]) - condition (
string)
Here, we actually define what data to collect, by what criteria, and what calculations to perform. The dimensions can be placed on rows or on the columns. The measures are precalculated values from the processed dimension file outputs, and the condition is just a filtering criteria for this data. To actually execute the Query, use the following code:
dataCube.Execute();
If we run the Execute() method on the previously created and processed Cube, the following output XML file will be generated, by the name of Test.xml:
As the output file shows, we have got the Categories dimension data for the specific filtering conditions ('Produce' and 'Seafood').
Another, a more complex, example would be to get the [Products Sales By Year] data. We need here a so called "time hierarchy" to be engaged. Please check the following code:
DataCube.DataCube dataCube = new DataCube.DataCube
(@"NORTHWIND_DATACUBE", @"Server=localhost; Initial Catalog=NORTHWIND;
Integrated Security=SSPI", @"E:\\Firma\\NORTHWIND_DataCube\\", DataCubeType.DataCubeTypeMSSS);
dataCube.Model();
DataCube.Fact fact = new DataCube.Fact("Order Details");
DataCube.Measure measureQuantity = new DataCube.Measure
("Quantity", DataCubeFactAggregationType.DataCubeFactAggregationTypeSum);
fact.Measures.Add(measureQuantity.Name, measureQuantity);
DataCube.DerivedMeasure measureSales = new DataCube.DerivedMeasure
("Sales", DataCubeFactAggregationType.DataCubeFactAggregationTypeSum,
"UnitPrice * Quantity * (1 - Discount)");
fact.DerivedMeasures.Add(measureSales.Name, measureSales);
dataCube.Facts.Add(fact.Name, fact);
DataCube.Dimension dimensionProducts = new DataCube.Dimension
("Products", new string[] { "ProductID", "ProductName", "UnitPrice" });
dataCube.Dimensions.Add(dimensionProducts.Name, dimensionProducts);
DataCube.Dimension dimensionOrders = new DataCube.Dimension
("Orders", new string[] { "OrderID", "ShippedDate" });
dataCube.Dimensions.Add(dimensionOrders.Name, dimensionOrders);
DataCube.DimensionGroup dimensionGroupProductsOrders =
new DataCube.DimensionGroup("Products_Orders", new string[] { "Products", "Orders" });
DataCube.DimensionGroupHierarchy hierarchyProductsOrdersYear =
new DataCube.DimensionGroupHierarchy("Products_Orders_ShippedDate_YEAR",
"Orders", "ShippedDate", DataCubeDimensionHierarchyType.DataCubeDimensionHierarchyTypeYear,
null, new string[] { "Products.ProductName", "Orders.ShippedDate" });
dimensionGroupProductsOrders.Hierarchies.Add(hierarchyProductsOrdersYear.Name,
hierarchyProductsOrdersYear);
dataCube.DimensionGroups.Add(dimensionGroupProductsOrders.Name, dimensionGroupProductsOrders);
dataCube.Process();
dataCube.Save();
Here, we create the necessary dimensions (from the "Products" and "Orders" tables) as also the facts (from the "Order Details" table) with the corresponding measures (Quantity and Sales). Next a "dimension-group" is created. The constructor for the DataCube.DimensionGroup object takes the following params:
- name of the group (
string) - array of dimensions from the group (
string[])
Processing of the created group generates the following SQL query:
And the results that are obtained are the following:
This group should be processed on the yearly base, so we create the time hierarchy for this group using the DataCube.DimensionGroupHierarchy class. Please check the constructor params for this object:
- name of the hierarchy (
string) - name of the table (
string) - name of the column (
string) - hierarchy type (enumerable of the
DataCubeDimensionHierarchyType type) - parent hierarchy object (
DataCube.DimensionGroupHierarchy type) - array of tables and corresponding columns (
string[])
Processing of the created group, with the yearly based hierarchy, generates the following SQL query:
Also, the results we get are:
Next, we should create a Query object and execute it, so check the following code:
DataCube.DataCube dataCube = new DataCube.DataCube
("NORTHWIND_DATACUBE", null, "E:\\Firma\\NORTHWIND_DataCube\\", DataCubeType.DataCubeTypeMSSS);
dataCube.Load();
DataCube.Query query = new DataCube.Query
("Test", new string[] { "Products.Products_ProductName" }, new string[]
{ "Orders.Orders_ShippedDate_YEAR" }, new string[] { "Quantity", "Sales" },
"Orders_ShippedDate_YEAR IN ('1996', '1997', '1998')
AND Products_ProductName IN ('Chai', 'Chocolade')");
dataCube.Queries.Add(query.Name, query);
dataCube.Execute();
Finally, the following XML output file is generated at the repository:
Here, it should be noted that a multi-level data pivoting is supported, on rows, as also on the columns.
Also, please check the provied examples in the test project for the correct naming convention of the generated XML files, etc.
Points of Interest
This was a very challenging project for me, and I am sure someone will find this class library useful.
History
DataCube v1.0 - August, 2018

