Introduction
Let's imagine you are working for a company that deals with big data collections and you must come up with the best data-structure, to handle billions of records. How we know which data-structure is the best is a challange that I tired to answer to it during this benchmarking. Before starting to read please take into your account the following ponts:
- The operating system is not a real-time operating system so I am presenting results in an avrage
- The BS (Binary Search) requres a sorting and this sotring time complexity is relaxed from my study as you can use any convinent sorting algorithm and add the complexity of your sorting algorithm on top of my results. For more information about the sorting time complexity see the link.
What is the Good Solution?
The good solution is a solution that gives you a Maximum-Speed and Capacity with a Minimum-Time cost. Obviously, I made deterministic distinguish out of the question because my working Operating System is not a Real-Time Operating System! but if we can come up with a more deterministic solution that's like Apple-Pie and Chevrolet.
Machines Specifications
The machine that will execute all unit tests has the following hardware and software configuration:
- CPU: Intel (R) Core (TM) i7-6650U @ 2.2GHz (4 CPUs), ~2.2GHz
- RAM: 8 GB
- O.S: Windows 10 Pro
- Visual Studio 2017
Background
In this article, I will do some performance benchmarking for dealing with big data collections in C# .NET language from the point of capacity, speed and time cost of view. My selected collections are Array, List, and Dictionary.
The managed code term coined by Microsoft and refers to executes the code under the management of a CLR, like the .NET or Mono. For more information about managed and unmanaged code, please follow the below links:
Execution of managed code could be not so deterministic because of the CLR interference, for this reason having a benchmark that provides a rough estimation could be very helpful. However, before considering the results of this benchmark, we would be good if we answer the following two questions:
- What is the maximum size of your big data collection?
- What is the data type? You will deal with what kind of data? Integer, Text, etc.
As you will see from the results, the performance of each collection highly depends on the size of the collection and the algorithms that are being used over the collection such as the Search.
Note 1: Please keep in your mind all test-beds are in none Real-Time Operating System. This means the results are not deterministic. To overcome this non-deterministic result, I have executed all tests for 100 times, thus what you will see is the average time of 100 iterations.
The operations that I have considered are creation and search because these are the two most expensive and important operations.
Search Operations
The following method presents a schema of the search tests, as you can see from the code I am considering always the worst case scenario, this means the item which I am looking for is almost at the end of the collection. The search algorithm is surrounded by the Monitor object which contains a clock and starts before entering the search body and stops immediately after finding the item in the collection:
[TestMethod]
[TestCategory("Owner [C'#' Array]")]
public void FindByForInArry()
{
try
{
string find = mocklbl + (capacity - 1);
Monitor.Reset();
for (int j = 0; j < iteration; j++)
{
string found = "";
Monitor.Start();
for (int i = 0; i < capacity; i++)
{
if (array[i] == find)
{
found = array[i];
break;
}
}
Monitor.Stop();
Assert.AreEqual(find, found);
}
Monitor.LogAvgElapsed("FindByForInArray");
}
catch (Exception ex)
{
Monitor.WriteLog(ex.Message);
throw ex;
}
}
Search Time Complexity
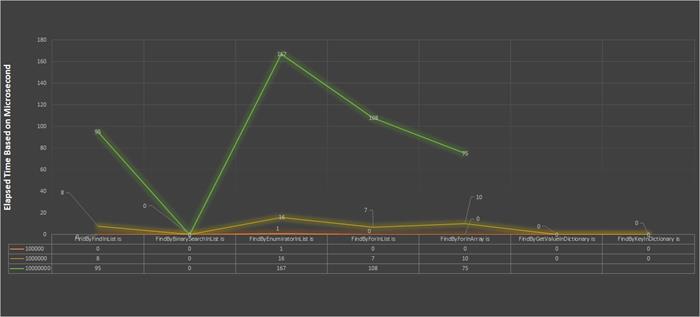

There are several interesting facts from the above chart which I would like to list:
- The Binary-search (the second column from the above table) always takes 0 milliseconds to find the item.
- The time variance between 1000000 (1 million) records and 10000000 (10 million) records deviates exponentially in all search algorithms (compare the green line with the yellow line).
- The dictionary data structure is not able to handle 10000000 (10 million) records (this is why the green line does not exceed from the
FindbyFindInArray). - The find by enumeration is the worst search algorithm (see the third column).
- The order of search algorithms over a list and array from the best to worst is: Binary-search, Find,
For loop, and the enumerator object. - Over 100000 (100 thousand) records, there is no significant difference between data structures and search algorithms.
- If there is no need for the key-value pair, then a list with the Binary-search is the best option.
The next chart will present the time complexity of creating and writing into the same collections (array, list, and dictionary). The below code represents a sample schema from these tests:
[TestMethod]
[TestCategory("Owner [C'#' Array]")]
public void FetchMockData(long capacity = 1000)
{
try
{
capacity = Monitor.BySize;
for (int j = 0; j < 100; j++)
{
Monitor.Reset();
Monitor.Start();
array = new string[capacity];
for (int i = 0; i < capacity; i++)
{
array[i] = mocklbl + i;
}
Monitor.Stop();
}
Monitor.WriteLog($"The creation of array took:{Monitor.AvgElapsedInMiliseconds}");
}
catch (Exception ex)
{
Monitor.WriteLog(ex.Message);
throw ex;
}
}
Creation Time Complexity
Following are the facts from the above chart:
- The same exponential complexity between 1000000 (1 million) records and 10000000 (10 million) records also appear in the creation time.
- The List data structure is almost beating the Array and knockdowns the Array after reaching the 1000000 (1 million) records size.
- Dictionary has the worst time complexity and should be used if and only if it is necessary.
Conclusion
Magically, the List data structure works so good and has better performance and with the combination of Binary-search can provide very significant performance optimization.

