Visit Part 1: Data Visualizations and Bezier-Curves
Visit Part 2: Bezier Curve Machine Learning Demonstration
Visit Part 3: Bezier Curve Machine Learning Demonstration with MS CNTK
Introduction
This article is Part 4 in a series. Previous articles examined techniques for modelling longitudinal data with Bezier curves and utilizing machine learning algorithms to train network models to recognize patterns and trends reflected in the trajectories of such curves. However, once you have trained and validated one or more suitable classification models, you want to deploy those models efficiently in production runs.
Typically (at least in my limited experience), the classification step, where the model is applied to a new feature data record and a result is returned, is a very fast, quite “short-running” process. However, also typically, in production (where 1000s of cases are being examined), that process may be rather deeply embedded in a much more time-consuming “long-running” data-processing step. This may involve all sorts of manipulations to collect, model, and shape “raw data” into records ready to classify. It may then have additional steps (which simply include the classification result as one more variable) to shape the data further for descriptive or predictive analytics and/or visualization, etc.
When that is the case, it is natural to think about parallel processing. Unfortunately, often the functions that apply the model to the data are not thread-safe. As examples, those for ALGLIB neural networks and decision forests as well as those provided for MS CNTK neural networks are not thread-safe. This article demonstrates one technique for deploying trained models safely and concurrently embedded in an otherwise thread-safe process running inside a Parallel ForEach loop in C#.
Background
For context, in previous articles, we looked at student academic performance over time from grades 6 through 12, modelled using Bezier curves. We demonstrated machine learning classification models that could be trained to recognize various patterns, such as longitudinal trajectories that identify students who appear to be doing well or likely to be at-risk.
Here, in this standalone "ConcurrencyDemo" console app project, we will use the same data set from the previous “BezierCurveMachineLearningDemoCNTK” project that was presented in Part 3. That project demonstrated various ways to train different types of networks and allowed them to be saved for later use in production runs. This project includes 3 trained models (a CNTK neural network and ALGLIB neural network and decision forest networks) that were generated by the previous project.
When this ConcurrencyDemo project is downloaded and opened in Visual Studio, the required CNTK 2.6 Nuget package should be restored automatically and included as a reference. Then, configured as x64 builds for Debug and Release, the demonstration of concurrency using CNTK models should run well. However, to test ALGLIB models, you will need to have downloaded and built successfully the free edition of ALGLIB314.dll. A detailed walk-though to do that was presented in Part 2. When this is added as a reference and the appropriate section of the demo code is un-commented, you will be able to test those models as well.
I think this article can be read and understood alone. Reviewing the narrative in Parts 1 through 3 would set the stage for understanding better. CNTK trained models are NOT thread safe and here is a good reference: Model Evaluation on Windows. Parallel operations and concurrency are NOT simple topics and I admittedly am not an expert. Here is a very good refresher reference for that from Microsoft: Patterns for Parallel Programming: Understanding and Applying Parallel Patterns with the .NET Framework 4.
Trained Model Deployment
Part 3 of this series provided code to experiment with training, validating, and saving various classification models using ALGLIB and CNTK. Let’s assume you have done that and you have three saved trained model files: an ALGLIB neural net, an ALGLIB decision forest, and a CNTK neural net. Assume as well you have a new data set consisting of features (in this case, vectors of 24 equally time-spaced values from a starting point to an ending point representing Bezier curve trajectories). Each case will be presented to a classifier as a double[] data array. The classifier should then return a list of classification probabilities and the index of the largest (and therefore, most likely predicted) classification.
There are at least several ways to run trained models successfully concurrently. However, the best and simplest method I have found (following an excellent tip from CodeProject contributor, Bahrudin Hrnjica, who certainly knows CNTK well) involves the use of ThreadLocal class methods. Here is part of the code for the ClassifierModel.cs module used in this demonstration:
using CNTK;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading;
namespace ConcurrencyDemo
{
public enum EstimationMethod { ALGLIB_NN = 1, ALGLIB_DF = 2, CNTK_NN = 3 };
public interface IClassifier
{
int PredictStatus(double[] data);
(int pstatus, List<double> prob) PredictProb(double[] data);
int GetThreadCount();
void ClearThreadLocalStorage();
void DisposeThreadLocalStorage();
}
public class MLModel : IClassifier
{
private IClassifier _IClassifierModel;
public MLModel(EstimationMethod mychoice, string applicationPath)
{
switch (mychoice)
{
case EstimationMethod.ALGLIB_NN:
_IClassifierModel = new ALGLIB_NN_Model(Path.Combine
(applicationPath, "TrainedModels\\TrainedALGLIB_NN.txt"));
return;
case EstimationMethod.ALGLIB_DF:
_IClassifierModel = new ALGLIB_DF_Model(Path.Combine
(applicationPath, "TrainedModels\\TrainedALGLIB_DF.txt"));
return;
case EstimationMethod.CNTK_NN:
_IClassifierModel = new CNTK_NN_Model(Path.Combine
(applicationPath, "TrainedModels\\TrainedCNTK_NN.txt"));
return;
}
throw new Exception("No status estimation method was provided");
}
public int PredictStatus(double[] array)
{
return _IClassifierModel.PredictStatus(array);
}
public (int pstatus, List<double> prob) PredictProb(double[] array)
{
return _IClassifierModel.PredictProb(array);
}
public int GetThreadCount() { return _IClassifierModel.GetThreadCount(); }
public void ClearThreadLocalStorage() { _IClassifierModel.ClearThreadLocalStorage(); }
public void DisposeThreadLocalStorage() { _IClassifierModel.DisposeThreadLocalStorage(); }
}
public class CNTK_NN_Model : IClassifier
{
private readonly CNTK.Function _clonedModelFunc;
private ThreadLocal<CNTK.Function> _cloneModel;
public CNTK_NN_Model(string networkPathName)
{
if (File.Exists(networkPathName))
{
CNTK.Function CNTK_NN = Function.Load(networkPathName,
DeviceDescriptor.UseDefaultDevice(), ModelFormat.CNTKv2);
_clonedModelFunc = CNTK_NN;
_cloneModel = new ThreadLocal<CNTK.Function>(() =>
_clonedModelFunc.Clone(ParameterCloningMethod.Share),true);
}
else throw new FileNotFoundException("CNTK_NN Classifier file not found.");
}
public CNTK_NN_Model(Function CNTK_NN)
{
_clonedModelFunc = CNTK_NN;
_cloneModel = new ThreadLocal<CNTK.Function>(() =>
_clonedModelFunc.Clone(ParameterCloningMethod.Share), true);
}
public int PredictStatus(double[] data)
{
(int pstatus, List<double> prob) = PredictProb(data);
return pstatus;
}
public (int pstatus, List<double> prob) PredictProb(double[] data)
{
CNTK.Function NN = _cloneModel.Value;
Variable feature = NN.Arguments[0];
Variable label = NN.Outputs[0];
int inputDim = feature.Shape.TotalSize;
int numOutputClasses = label.Shape.TotalSize;
float[] xVal = new float[inputDim];
for (int i = 0; i < 24; i++) xVal[i] = (float)data[i];
Value xValues = Value.CreateBatch<float>(new int[] { feature.Shape[0] }, xVal,
DeviceDescriptor.UseDefaultDevice());
var inputDataMap = new Dictionary<Variable, Value>() { { feature, xValues } };
var outputDataMap = new Dictionary<Variable, Value>() { { label, null } };
NN.Evaluate(inputDataMap, outputDataMap, DeviceDescriptor.UseDefaultDevice());
var outputData = outputDataMap[label].GetDenseData<float>(label);
List<double> prob = new List<double>();
for (int i = 0; i < numOutputClasses; i++) prob.Add(outputData[0][i]);
int pstatus = prob.IndexOf(prob.Max()) + 1;
return (pstatus, prob);
}
public int GetThreadCount() { return (_cloneModel.Values).Count(); }
public void ClearThreadLocalStorage()
{
_cloneModel.Dispose();
_cloneModel = new ThreadLocal<CNTK.Function>(() =>
_clonedModelFunc.Clone(ParameterCloningMethod.Share), true);
}
public void DisposeThreadLocalStorage() { _cloneModel.Dispose(); }
}
Sorry for the long code block, but it is not difficult to explain. Assume we know the names of and full paths to the trained model disk files. In this demo, those are:
applicationPath + "Trained Models\\TrainedALGLIB_NN.txt"
applicationPath + "Trained Models\\TrainedALGLIB_DF.txt"
applicationPath + "Trained Models\\TrainedCNTK_NN.txt"
Then we begin by selecting a model for the production run using the Enum EstimationMethod, like this. Then later on, maybe deep in some other data processing step, we will apply our model to a feature data vector, like this:
MLMODEL myModel = new MLMODEL(EstimationMethod.CNTK, myApplicationpath);
…
int pred = myModel.PredictStatus(someFeatureDataVector);
…
First, we define an ICLASSIFIER interface. That interface is illustrated here to allow the user to add and switch between multiple types of trained models. (It would not be needed if only one type of model is of interest). In the code above, only the CNTK model is illustrated. Next, we have a MLMODEL class and a constructor that loads the selected trained model data file and creates a new ICLASSIFIER object containing that model. Since both inherit from ICLASSIFIER, both must implement several methods: PredictStatus() and PredictProb(), plus a couple of other useful properties related to the ThreadLocal class. We call the myModel object’s methods and they in turn call the same methods in the ICLASSIFIER object it defines. There, the model is applied to the data and the return values are passed back up the chain to the calling process.
The new ICLASSIFIER object constructor receives the path to the model disk file and loads the model into this variable:
private readonly CNTK.Function _clonedModelFunc;
It then creates its own ThreadLocal<T> object where T is the trained model type, like this:
private ThreadLocal<CNTK.Function> _cloneModel;
...
_cloneModel = new ThreadLocal<CNTK.Function>(() =>
clonedModelFunc.Clone(ParameterCloningMethod.Share), true);
Then, later on somewhere else in the code, while running on some thread, the myModel.PredictStatus(datavector) or myModel.PredictProb(datavector) method is called. The first thing that happens is that the method calls on the ThreadLocal object to obtain the unique cloned model "Value" to be used on that particular thread and applied to a data record, resulting in a classification.
CNTK.Function NN = _cloneModel.Value;
...
... evaluate
...
return (pstatus, prob);
THREADLOCAL<T>
The most interesting thing about the MLMODEL class and the ICLASSIFIER object it creates is the use of a ThreadLocal object and some assorted properties and methods for it. Here again is the issue: CNTK trained models and associated methods are NOT thread-safe. The same also is true for ALGLIB network models. The remedy is to create cloned models to be used for concurrent processing.
If you are running serially (on the application’s main thread), you need only one model. If you are running parallel concurrent processes, you will need multiple cloned copies. At the very minimum, you need one copy for each logical processor your hardware provides. For example, if you have 2 CPUs offering hyperthreading, then you have 4 logical processors. (In a Parallel ForEach loop, for instance, you can use PLINQ’s WithDegreeOfParallelism method to control this.) Much of the time, System.Threading methods use data partitioning schemes and allocate a single thread to each logical processor. But still often, load balancing and so forth may result in several threads running on the same processor.
Creating those clones is a time- and memory-consuming process and not something to be done “on-the-fly,” so to speak. ThreadLocal<T> handles all this for us, creating and storing one new clone for each new processor thread and supplying that particular clone to events occurring on that particular thread. The place to do that is in the ICLASSIFIER network object constructor.
When the model is running entirely on the main thread, only one clone value is stored and only one copy is ever used. But if you have multiple logical processors and are running a classification method concurrently, you will have multiple values stored in ThreadLocal storage. Several useful methods are provided to check up on that.
GetThreadCount() gets the number of copies that have been stored. It is a good idea to clear and recreate the ThreadLocal object prior to each parallel code block that might involve classification in your program. ClearThreadLocalStorage() does that. Finally, you should always dispose of that storage before exiting your application. DisposeThreadLocalStorage() does that.
So the CNTK_NN object in the code above always knows which cloned model element to use for each data partition and each logical processor, ThreadID. This allows the MLMODEL object to create and run a thread-safe ICLASSIFIER object successfully in a concurrent process.
Using the Concurrency Demonstration Code
So now, we come to the ConcurrencyDemo at hand. Download and unzip that project (maybe on the desktop). This step should result in a folder named ConcurrencyDemo which contains the ConcurrencyDemo.sln file plus other files. Open that solution file in Visual Studio. Check the Configuration Manager to insure that Debug and Release builds for all projects in the solution are set to x64. Next, build both the Debug and the Release versions. If all seems to have gone well so far, choose ConcurrencyDemo as the StartUp project and click Start to build and run the console application. Output similar to the image below should appear in the console window:
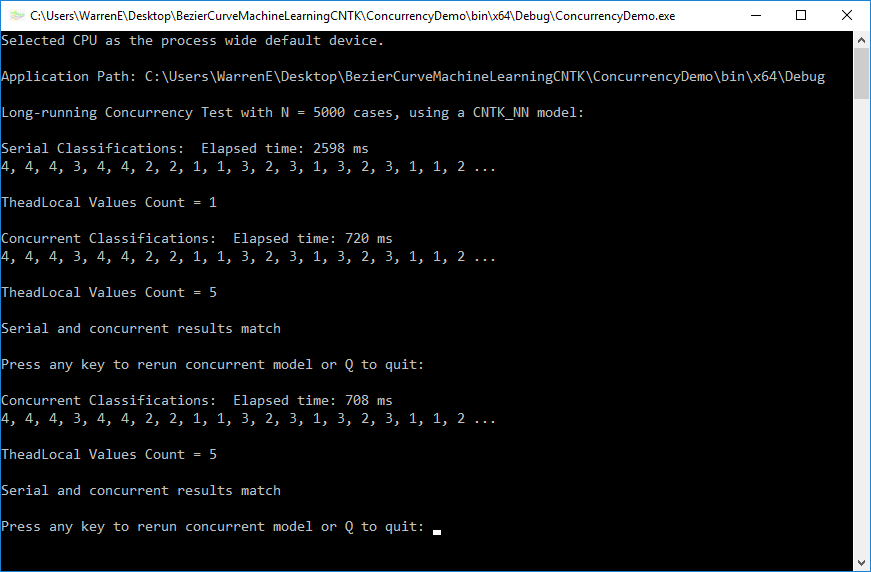
The demo comes with the ALGLIB neural net and decision forest classes commented out. (The lines in the MLMODEL constructor for these classifiers are also commented out.) To demonstrate that they also can be run concurrently successfully, a last setup step would be to expand the ConcurrencyDemo project folder in Solution Explorer, right-click on the References folder there, and use the Add References option to add the ALGLIB314.dll library (which you would have built in Part 2 of this series) to the ConcurrencyDemo project as a reference by clicking its checkbox and the OK button. Then uncomment the commented sections in the ClassifierModels.cs module and change the Enum value in the Program.cs module.
Points of Interest
The philosophy here is that most of the benefit to be derived from a CodeProject “demonstration,” is supposed to come from examination of the code. Readers are certainly encouraged to do that (any suggestions for improvements will be appreciated). This article is probably too long already and the code in the program.cs module is pretty much self-explanatory.
What we do is load the entire sample data file (N=500) using the DataReader object. Once we have that in memory, for fun, we duplicate that 10 times, and reformat it as a dictionary of double[] values accessed by an ID key. Next we create a local process that will classify all of that data using a MLMODEL for CNTK data. There is an option to make those “short-running” operations more realistically “long-running.”
First, we run and time this local process being called repeatedly by a simple loop executing serially on the main thread and save the results (an (ID, Classification) tuple) in a list. Next, we use a Parallel ForEach loop and run and time that, storing output in a ConcurrentBag which we eventually sort by ID and store in a second list. Finally, we compare the two lists to ensure that they match perfectly. That, of course, is the most important test of all.
From the console output, we can see that the serial and parallel classifications did match and the concurrent method was more than twice as fast. We also can notice that ThreadLocal<T> worked as expected, containing only one entry and using just one model copy for serial processing and for that particular parallel processing run using perhaps 5 or 6 cloned models running on 4 logical processors. (Note there is an option for running the concurrent process repeatedly to see how resources change. If you have Diagnostic Tools open, you can see that almost 100% of CPU processor resources are used each time you rerun the concurrent process.)
Conclusion
The principal conclusion drawn from this demonstration is that CNTK and other models trained using various machine learning techniques can be run concurrently safely in production environments, either directly called or deeply embedded in some (otherwise thread-safe) data processing loop.
History
- 1st October, 2018: Version 1.0

