String Type
Let’s continue our discussion by talking about the String type. The string is a very interesting type because it is really made up of a number of bytes. But the number of bytes is variable (depending upon the length of the string) and that is unlike the Number and Boolean types where the Interpreter knows the maximum number of bytes the data type will take up. We will see how this creates a significant challenge for the developers who create programming languages like JavaScript.
You can create a String with the following code:
var firstName = "robert";
console.log("firstName is a " + typeof firstName);
You can see this code and run it at jsfiddle:
As I said, strings are different, because each character in the string takes a byte to store, but the length of the string cannot be determined until the variable has its value set.
The Interpreter (and lower layers of technology, like web browser and the Operating System) still has the constraint that it must find contiguous memory to store the string in.
That means there is more work for the underlying layers to do to store your string.
Let's look at this a bit more closely by looking at the memory when you store a string with the following JavaScript:
var companyName = "Big House";
Take a look at Figure 7: string in memory.
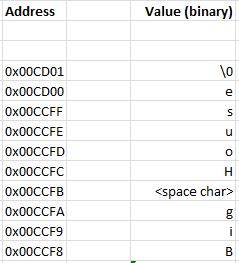
Terminating Character
First of all, notice that last odd character located at 0x00CD01. Since the string can be any length, there has to be a way to determine the last byte that is associated with the string so the Interpreter can determine where the string ends and not read other random bytes into the string from memory. In C and C++, they used a \0 (backslash followed by zero) to denote this. That could just be the ASCII Zero byte (ASCII value 0, aka Null byte). It's probably the same in JavaScript.
Or, it is possible that JavaScript automatically stores the length of the string in another associated address which contains a Number value. That would mean that Interpreter would first retrieve the address where the size of the string is and get the number of bytes and then it would retrieve the actual string.
VisualBasic used a type called a BString which used the first X bytes of the string to store its length. Of course, every time the string changes that value has to be updated.
The point to take away from this is that someone has to handle the issue that strings are of different lengths and the constraint that associated memory for a variable has to be contiguous.
What If the String Grows?
All of this should bring to mind the main problem. What if the string becomes longer, because you set it to a new string value?
For example, if later in the program, you store:
companyName = "Big House Crafts";
Suddenly, the program needs seven more contiguous bytes (one space plus six letters). But, what if the bytes past 0x00CD01 are already taken for use with other variables?
Strings are Immutable
This is exactly why strings are immutable in JavaScript (and most other languages). Immutable means they cannot be changed.
But that might seem odd that I'm saying that, because in the JavaScript code we did indeed set the companyName variable to one value and then we set it to another value later so it seems we have changed it.
However, it is underneath JavaScript where the string has not changed: in the actual memory where the program's data is stored.
It's a Whole New String
That's because when you change a string like we did in the previous code, it does not just change the value stored at the original address. Instead, the original address is cleared and removed from the internal lookup table.
Then, the Interpreter:
- calculates the amount of memory your new
string is going to take - goes out and finds enough contiguous bytes
- gets the new address
- stores the address in the internal lookup table
- and finally, sets the value of those bytes
You now have a whole new string -- a new address where the string is stored.
This also explains why adding characters to a string can be much slower (more processor intensive) than what is expected by the developer. There is much more work involved than just adding the new character to the end of the string.
That's all for this installment, but next time we'll dig a big deeper into strings and then talk about Reference types.
Keep on learning, keep on programming.
~Roger Deutsch
CodeProject

