Contents
Introduction
Generally, partition problem is the task of deciding whether a given set of positive integers with count of N can be partitioned into k subsets such that the sum of the numbers in each subset is equal. In real life, the exact equality of the sums is usually unattainable, so we will operate with an optimization version of the partition problem, which is to partition the multiset into k subsets such that the difference between the subset sums is minimized. A typical example of its application is the distribution of a set of independent works, each with different execution time, in several concurrent threads. If each thread runs on a separate core, we would like to be confident in the uniform load of each core in the CPU node.
The partition problem is NP-complete, while the optimization version is NP-hard. Practically, that means that when N is more than ~20 and the k is more than ~3, the full enumeration method becomes overload.
Although it is noted that in practice, the optimization version can be solved efficiently, when I faced this task in my job, I did not find any reliable ready solution. It forced me to find a solution on my own.
Algorithm
Terms
We will evaluate the quality of the partition by the difference between the maximum and minimum sums of numbers in the subsets. Let me call this difference absolute inaccuracy, or simply inaccuracy. Accordingly, the maximum difference of sums as a percentage of the average sum will be called relative inaccuracy.
There is a certain inconsistency in the use of the term perfect partition. In some publications, perfect implies a partition to the basic statement of the problem, in others, both the basic and optimization ones. For greater certainty, we will use the term perfect (without quotes) to denote a partition with zero inaccuracy. With the term ‘perfect’ (in quotes), we will denote solutions to the optimization version, that is, the partition with a possibly minimum inaccuracy.
Admitted Greedy
The well-known heuristic approach, this way the problem is usually solved by children. It iterates through the numbers in descending order, assigning each of them to whichever subset has the smaller sum. This approach has a running time of O(n log n).
Alternative
Another heuristic approach is based on a simple idea: the more numbers are already distributed over the subsets, the easier it is to evenly distribute the remaining small numbers, compared to the large ones. Thus, we should try to ram each subset beginning with the largest numbers, and ending with the smallest ones.
The algorithm is as follows: first, the average sum of numbers in all subsets is determined. Then it iterates through the numbers in descending order, assigning each of them to the first subset until their sum does not exceed a certain threshold, defined as the average sum plus delta. If the addition of the next number exceeds this threshold, it iterates through the remaining numbers in descending order, looking for the first one fulfilling this limiting condition. When such numbers for the first subset no longer remain, the procedure is repeated for the next subset.
In this form, the algorithm has a serious drawback: since the subsets are filled successively according to the only criterion of the proximity of their sums, last subsets can remain empty, especially in the case when N is less than ~2k, corresponding to a maximum possible inaccuracy. To eliminate this flaw after the completion of the entire cycle, the unfitted numbers are distributed into subsets according to the Greedy method. But this is done only if their number does not exceed k/2, which is a compromise approach. Otherwise, the whole process is repeated again with delta increased by its initial value. It should be noted, however, that such an adjustment still does not guarantee the filling of all subsets in the extreme case of N≈k.
Assignment initial delta value is an important point. If it is too small, the number of iterations (and the total time) increases excessively, while too big value may cost bad (high inaccuracy) partitions. Since there are no mathematical criteria for calculating this value, it was chosen based on testing equal to 1/20 of the smallest input number, but no less than 1. This heuristic value, along with the above condition for completing the iterations, provides satisfactory inaccuracy in a single pass in all test measurements.
I called this algorithm Sequential stuffing Greedy, SGA. Within one iteration, its complexity is also O(n log n). In general, it competes with Greedy both in terms of the quality of the result and the speed, but the presence of heuristic constants and conditions, as well as the lack of guarantees for filling all subsets, are weak points of this method.
Simple
It is interesting to propose a simpler and, importantly, faster approach, for the purpose of comparison. It iterates through the numbers in descending order, assigning each of them to the next subset and changing the order of subset traversal when reaching the last one or the first one. This approach has a running time of O(n). Let me call it Unconditional Greedy algorithm, UGA (though the ‘stupid greedy’ would be also suitable).
This approach is the fastest indeed, but its partition quality, as a rule, is predictably the lowest (as is shown in the figure).
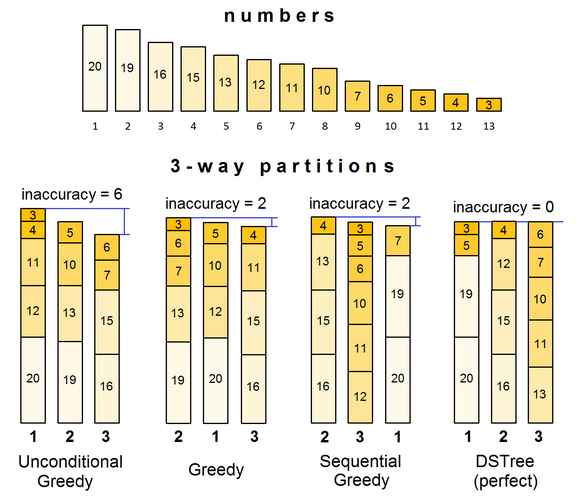
The partition quality of greedy algorithms is like rolling bones. To achieve reliable ‘perfect’ result, we must use brute force. It is implemented through a dynamic search tree, in which each node is assigned a number and a subset. Again, all numbers are pre-sorted in descending order. The node sequentially searches the remaining unallocated numbers and decides whether to add each number to the assigned subset, or to the next one. Both of these choices create a new node; this is one sense of the word ‘dynamic’. The node with the last assigned subset is the final, that is, the ‘bottom’ of the tree. It assembles the last subset by filling it with all the remaining unfitted numbers.
Thus, the depth of the tree is limited by the number of initial integers, but the number of branches of each node is not predetermined. We can only say that it is limited by the number of currently unallocated integers.
Such a solution takes into account the commutativity of addition, but does not control the frequency of combining for different subsets. In other words, the variations {n1, n2} and {n2, n1} are guaranteed excluded, but two subsets {n1, n2} and {n3, n4} can be repeated on different routes in different order. Such redundancy is a consequence of the relative simplicity of the algorithm. It is largely offset by the use of the pre-term completion adjustment (see below).
The complexity of such algorithm is O(n!), which is extremely time-consuming. In order for the execution time to be acceptable, it is necessary to ensure the fulfillment of four key requirements: speed maximization, self-tightening accuracy selection, pre-term completion and time limitation.
Speeding Up
An obvious condition for achieving the highest possible speed is to avoid memory allocation on the heap during the iteration. The solution is to build a dynamic tree on the stack by using a recursive procedure. Each specific tree route lives on the stack until reaching the lowest point or until it ceases to pass the accuracy criterion, from then on giving way to the next one. This is another sense of the word ‘dynamic’. During iterations, only a checkup of the belonging of a number to a particular subset is carried out, the actual dynamic memory allocation for all subsets is performed by reaching the end of all iterations. The number of input integers as the depth of recursive calls is completely acceptable for the practical tasks.
Self-tightening Accuracy Selection
The point is the same as in SGA method: selection of input numbers for a subset, if their sum does not exceed some upper threshold. The difference is that this time, it is all the unallocated numbers that we are looking for. This filtration drastically reduces the number of possible tree routes, as shown in the conventional figure, and accordingly decreases execution time.

Again, the question arises about the magnitude of this threshold, or the value of delta. This time, it is initially assigned to be 1 (if the average sum exceeds the largest number, otherwise, the value will be their difference increased by 2). However, there is a possibility, especially with a small number of N, that combinations satisfying this condition do not exist at all. In this case, the same method of repeating the full search is applied, this time with the doubled delta. The routes with an extremely tight inaccuracy are sparse and short, so such iteration can be performed fast. However, successive doubling of the delta quickly leads to a significant increase in the total route length. To resolve this contradiction, delta is made dynamic: for each final variation its actual value is checked, and if it is less than the current stated value, it becomes current, and the achieved result is stored as a standby. Otherwise, the result is ignored. Thus, in the process of iterations, the delta can decrease, exhibiting ‘self-sinking’.
In addition, this time not only ‘delta above’ is used (the maximum allowable excess of the average sum), but also the ‘delta below’ (the maximum allowable understatement of the average sum). Both values are assigned synchronously, so the initial acceptable inaccuracy is 2. Generalizing, there is a selection according to dynamic permissible inaccuracy.
Pre-term Completion
The constraint of enumeration is based on the fact that as N and k grow, the count of ‘perfect’ combinations also increases. We are satisfied with the first one found. If average sum has no fractional part, we can expect the perfect partition, but not necessarily. The first such result found interrupts further search. Otherwise, the best possible is a partition with inaccuracy=1, and again the first such result cancels execution.
Limitation
In general, we cannot say whether the current solution found is ‘perfect’. A partition with inaccuracy=1 may not exist at all, or be searched for a long time, so we have no choice but to limit the total execution time (or number of iterations, with is the same in essence), and be satisfied with the best result found during this period.
Specifically, the number of iterations is limited by heuristic value of 1,000,000. This value provides a result worse than some of the greedy algorithms giving only in 6 test measurements out of 168, while the algorithm execution time does not exceed ~0.5 second for the hardest case of distribution of 1000 integers. (see Testing for more details). Increasing this limit slightly improves the partition quality. For instance, doubling the limit reduces the number of worst test attempts to 3, but incidentally doubles the run-time. As the limit decreases below 1 million, the quality of DST partitioning begins to deteriorate markedly. Thus, this value can be considered the best compromise. After all, the number of iterations can be managed by a multiplier given to the class constructor as a parameter. Multiplier value of 1 is established as a default.
With lucky circumstances, greedy algorithms can provide a good result (see Testing). And since the time taken to complete them is measured in from one to hundreds of microseconds, there is no reason not to try the luck.
The combined solution includes all four algorithms, which are run alternately: UGA-GA-SGA-DST. Each turn, the best result is kept as final. Result with ultimate low inaccuracy (0 or 1) interrupts further calculations. UGA is not rejected from the chain mainly for receiving an extremely fast response in the degenerate case N/k ≤ 2/3.
A developer has the opportunity to choose the ‘quick’ option (without invoke DST method), when the partition quality is not guaranteed, but an execution time does not exceed some really low level (roughly, about 0.1 millisecond on 2.5 GHz machine).
The code below is on C++. Without documentation comments and timing/testing inserts, it takes about 500 lines. The only data container exploited is std::vector. I did not use C++11 (and later) amenities such as auto specifier, lambdas, functors and type alias instead of typedef, mainly do not restrict the compiler version. In code ‘bin’ is equivalent to ‘subset’. In order to prevent questions about classes vs structures: I use structures in cases where objects of this type live only in container. This is just a matter of convention.
The solution is implemented in a single class effPartition. Input numbers are marked with identifiers, the resulting partition is a collection of subsets, which in turn are the collections of number IDs.
Initially, the type definitions are given:
typedef unsigned short numb_id; typedef unsigned int numb_val; typedef unsigned char ss_id; typedef unsigned long ss_sum;
The input number is represented by a public IdNumber structure:
struct IdNumber
{
friend class Partition;
friend struct Subset;
friend class IdNumbers;
friend struct Result;
private:
ss_id BinIInd; numb_id ID; numb_val Val;
...
public:
inline IdNumber(numb_id id, numb_val val) : BinIInd(0), Id(id), Val(val) {}
inline numb_val Value() const { return Val; }
inline numb_val ID() const { return Id; }
...
};
A public input numbers collection is just a vector of IdNumber with 7 additional private methods:
class IdNumbers : public std::vector<IdNumber>
{
...
}
The last public structure Subset defines a partition data:
struct Subset
{
friend class Partition;
friend class effPartition;
private:
ss_id id; ss_sum sumVal; numb_ids numbIDs;
void TakeVal(const numb_it& it, ss_id binInd)
{
sumVal += it->Val;
it->BinIInd = binInd;
}
void effPartition::Subset::ElimVal(const numb_it& it)
{
sumVal -= it->Val;
it->BinIInd = 0;
}
...
public:
inline ss_id ID() const { return id; }
inline ss_sum Sum() const { return sumVal; }
inline const numb_ids& NumbIDs() const { return numbIDs; }
};
Class effPartition has three constructors excepting IdNumbers, vector of numb_val, or C-array of numb_val. In the last two cases, identifiers are assigned to integers automatically by their ordinal number. By analogy with RAII idiom, partition is performed in a constructor. Actually, all the work is done by an object of a special private class Partition, which is created in the effPartition constructor, and automatically releases all the temporary variables at its completion. Thus, after initialization of the effPartition object, it keeps only the final result as a vector of subsets, and its inaccuracy, with public access to them.
For brevity, I will not give the obvious code of greedy algorithms. Here is the Partition class with DST method only:
class Partition
{
static const UINT minCallLimit = 1000000; static const BYTE limFlag = 0x1; static const BYTE perfFlag = 0x2;
const float avrSum; const bool isAvrFract; const ULLONG callLimit; ULLONG callCnt; ss_sum minSum; ss_sum maxSum; ss_sum sumDiff; ss_sum lastSumDiff; ss_sum standbySumDiff; BYTE complete; effPartition::Result& finalResult; effPartition::Result currResult; effPartition::IdNumbers& numbers; effPartition::IdNumbers standbyNumbers; ...
void DSTree(effPartition::numb_it currnit, ss_id invInd)
{
if(complete) return;
effPartition::numb_it nit;
const ss_it sit = currResult.Bins.end() - 1 - invInd;
if(++callCnt == callLimit) RaiseComplFlag(limFlag);
if(invInd) { for(nit=currnit; nit!=numbers.end(); nit++) if(!nit->BinIInd && nit->Val + sit->sumVal < maxSum) { sit->TakeVal(nit, invInd); if(nit+1 != numbers.end()) DSTree(nit+1, invInd); if(sit->sumVal > minSum) DSTree(numbers.begin(), invInd-1); sit->ElimVal(nit); }
}
else { for(nit=numbers.begin(); nit!=numbers.end(); nit++)
if(!nit->BinIInd) sit->sumVal += nit->Val;
if(SetRange(currResult)) { standbyNumbers.Copy(numbers); lastSumDiff = standbySumDiff = sumDiff; if(IsResultPerfect()) RaiseComplFlag(perfFlag);
}
else if(currResult.SumDiff < standbySumDiff) { standbyNumbers.Copy(numbers); standbySumDiff = currResult.SumDiff;
}
sit->sumVal = 0; }
}
...
};
The full code with testing and timing procedures is applied.
Template
It seems tempting to write a generic version, because for this it would be sufficient that the operations of addition, subtraction and comparison were defined over the numbers. However, in this case, Pre-term completion requirement becomes unfeasible. In reality, in most cases with N less than 50, it is this requirement that provides a very short lead time to work out the algorithm. In addition, arithmetic operations on float numbers (and other non-integer types) are a bit slower. Thus, while partitioning floats, it is more efficient to round them down to integers and use this solution: the quality of the result will not change, while execution time remains at an acceptable level.
Testing
Testing was performed on a laptop with Intel Core i5 2.5 GHz. The code was compiled with maximize speed option.
From 10 to 1000 random integers in the range of 50-500 were distributed between different number of subsets in the range from 2 to 10 (first 4 series) and from 10 to 100 (last 2 series). Each partitioning was performed 3 times with different RNG seed value, then these results were averaged and plotted as inaccuracy and run-rime graphs.
Every algorithm was tested independently. Thus, in total, 168 measurements were performed.
Results in Summary
From the statistics represented in the table below, the series with N=10 are excluded as a rather low alternative.
|
| UGA
| GA
| IGA
| DSTree
|
| average relative inaccuracy, %
| 19.23
| 3.04
| 3.41
| 1.13
|
| number of best cases among the greedy
| 10
| (7%)
| 61
| (43%)
| 78
| (55%)
|
|
|
| number of best cases among all
| 4
| (3%)
| 10
| (7%)
| 3
| (2%)
| 133
| (94%)
|
| number of cases with inaccuracy=0
| 0
| 0
| 0
| 12
|
| number of cases with inaccuracy=1
| 0
| 2
| 2
| 29
|
The sum of counts of the best cases relative to the total count of cases exceeds 100%, because sometimes two algorithms showed the same best result, which was counted for both of them.
Without taking into account the series with N=10, DST algorithm distributed the integers perfectly in 12 cases out of 16 potentially possible. However, it should be repeatedly stressed that the average sum of all integers without a fractional part does not necessarily mean that partition with zero inaccuracy does exist.
Finally, in these tests, the average relative inaccuracy of the combined solution was 1.004%. I have to emphasize that this statistic is purely relative.
Results in Details
Distribution of average partition absolute inaccuracy is shown in figure:
Last two cases are ‘hard’ and rather belong to the task of ‘containers and wagons’.
Here is an average execution time:
All algorithms correctly handle the degenerate cases of a single subset or an equality of the initial numbers.
Run Time: Managed Code vs Unmanaged One
30 random numbers in the range of 50-500 were distributed between 4, 6 and 8 subsets by C ++, C# and Java solution implementations. By launching the each program, the effPartition object was created 3 times, with different numbers of subsets. The results of averaging between 3 launches are given in the table:
| lang
| sub
sets
| UGA
| GA
| SGA
| DSTree
|
| time, ms
| times
| inacc
| time, ms
| times
| inacc
| time, ms
| times
| inacc
| time, ms
| times
| inacc
|
| C++
| 4
| 0.0003
| 1
| 72
| 0.0004
| 1
| 38
| 0.0006
| 1
| 39
| 0.006
| 1
| 0
|
| C#
| 1.4
| 4491
| 1.9
| 4762
| 1.2
| 1873
| 2.8
| 491
|
| Java
| 0.68
| 2184
| 0.22
| 551
| 0.44
| 686
| 0.81
| 143
|
| C++
| 6
| 0.0003
| 1
| 205
| 0.0005
| 1
| 31
| 0.0008
| 1
| 45
| 0.01
| 1
| 0
|
| C#
| 0.005
| 18
| 0.007
| 16
| 0.013
| 17
| 0.047
| 5
|
| Java
| 0.036
| 125
| 0.074
| 158
| 0.10
| 136
| 0.30
| 30
|
| C++
| 8
| 0.0003
| 1
| 142
| 0.0006
| 1
| 55
| 0.0009
| 1
| 38
| 44.9
| 1
| 2
|
| C#
| 0.002
| 6
| 0.005
| 10
| 0.011
| 12
| 104.0
| 2
|
| Java
| 0.03
| 101
| 0.08
| 139
| 0.12
| 126
| 100.8
| 2
|
The bold font shows the relationship of execution times for each subset, where C ++ is taken as 1.
The first obvious question is why there is such a big difference in the methods execution time between the first creation of effPartition object and the subsequent ones in case of .NET, and less Java. It is clear that the CLR allocates a data segment on the heap before calling the methods measured by the stopwatch. Obviously, the garbage collector is never called. The peculiarity is that all partition methods actively refer to the collection of initial numbers. And all methods, except UGreedy, also actively refer to a temporary Result object (but actually request dynamic memory only once, at the end). Rapid experimenting has shown that the most likely reason for the ‘reverie’ of the methods first calls is setting residence these objects in the CPU’s cache (C#) or in the cash map (Java). In this case, the difference in run time of the first and subsequent partition method calls in C# and Java can be explained by the difference in efficiency of these caching strategy.
The second question concerns only twice the run time of the managed DST method implementations over the unmanaged one in case of 8 subsets, contrary to 4 and 6. To achieve this result, the method was invoked twice a million times, with doubled delta=2 and 4, while for the 4 and 6 subsets, it turned out to be enough only 247 and 487 calls respectively. With such a big number of recursive calls, the time required to initialize managed data memory becomes irrelevant. Most likely, such a slight time difference between managed and unmanaged code is explained by two effects: faster iteration through the collection by using iterators (C++) compared to indexes (C# and Java), and also direct access to the element of collection (C++) contrary to access by reference (C# and Java).
A detailed analysis of the influence of managed memory features is beyond the scope of the topic. The main thing is that execution time of even C# and Java solution does not exceed 0.7 seconds for the hardest tests N=1000 and k≤100.
Back to my initial application task, it concerned in silico treatment of a genome library. Each chromosome has a unique size, directly proportional to the processing time, and is treated independently. The table below shows the obtained maximum idle time of each of 4, 6 and 8 cores with a total time of mouse genome parallel processing of 10 minutes. Using the ‘perfect’ solution option (DST method), in the first 2 cases all processors shut down almost simultaneously. In the last case, the idle time is about half a minute; but it must be borne in mind that the better partition of 22 very different big integers into 8 subsets most likely does not exist at all.
| subsets
| 4
| 6
| 8
|
|
| 'fast'
| 'perfect'
| 'fast'
| 'perfect'
| 'fast'
| 'perfect'
|
| relative inaccuracy, %
| 3.03
| 0.016
| 11.52
| 0.23
| 20.52
| 5.66
|
| run-time, msec
| 0.007
| 22
| 0.009
| 35
| 0.01
| 110
|
| total 10 min; diff time, sec
| 18.2
| 0.1
| 69.1
| 1.4
| 123.1
| 33.9
|
It cannot be argued that this combined solution always gives a ‘perfect’ result. However, in a practical sense, it does. At least, it is the best compromise between quality and speed of number partitioning.
I am grateful to Oleg Tolmachev (University of Greenwich, UK) for his invaluable assistance in refining the language of this paper.

