Introduction
Recently, I was working on implementing a RandomForest algorithm in C++. If you are not familiar enough with Machine Learning, that's ok; this is quite a simple algorithm. I get a few binary trees, 200 in my case, that are all referring to a vector of values. Each node in the tree has an index to that vector and a threshold to compare to, if the value at that index in the vector is above the threshold, we walk the right edge of the node, if not we walk the left one. All of the leaves are values, usually 1 or 0. In the end, we average all of the values we get from all of the 200 trees and compare it to a detection threshold.
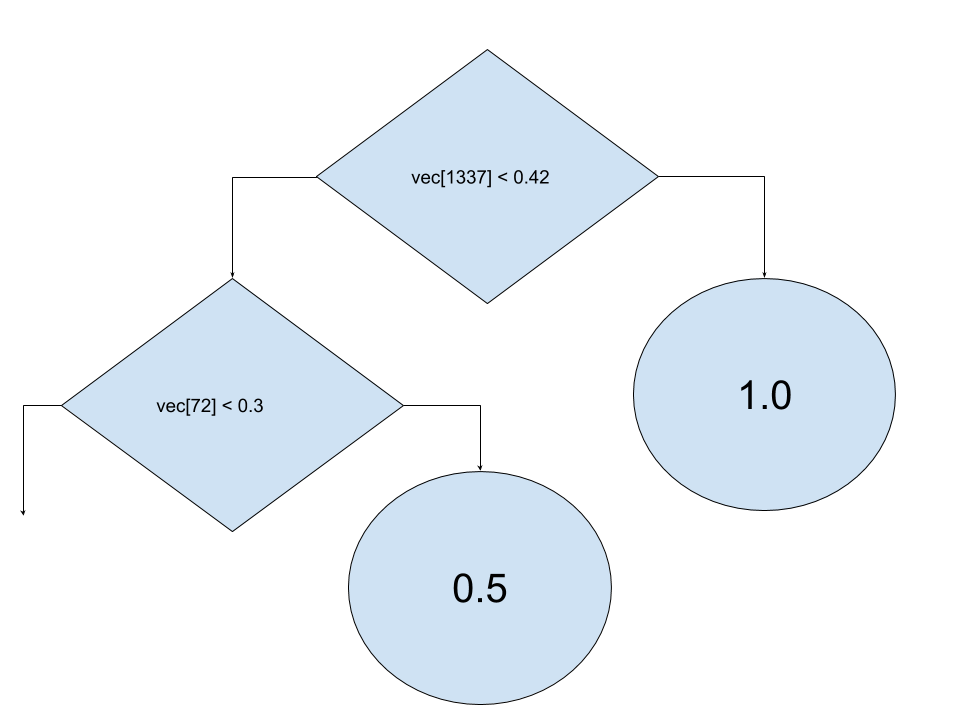
Pretty simple, isn't it?
In this post, I'll focus on the implementation of it in C++. I won't talk about the Machine Learning part of creating these trees in the first place, the process called training or learning, but I'll start from the point in which I have the trees encoded in some canonical ASCII way such as:
(<100,2.0>0.0|(<111,5.0>(<112,3.0>1.0|0.20000000298)|(<113,6.0>2.5|1.20000004768)))
Defined as:
(<vector index, value threshold>left node|right node)
At first, I decided to do some preprocessing of the trees using Python to convert it into some binary format that will be easier to load in real time and will require less parsing code in C++. I think it's good practice to avoid real-time parsing as much as possible. From my experience, code for parsing tends to be more prone to errors and security problems. I encoded the trees into the following format:
Byte: 0x01 - Tree start symbol
Byte: 0x02 - Node symbol
Uint32: Vector index
Double (64bit Floating Point): Threshold
Left Sub Tree...
Right Sub Tree…
Byte: 0x03 - Leaf
Double: Tree score
Byte: 0x0ff - End of data
Tip of the day: I created a reverse function to build the canonical form back from the binary form. I used it to validate that I get the exact same file as the input file to reduce the number of bugs drastically.
The C++ code for parsing that would simply build the trees into Vector of Nodes where Node is:
class RandomForestNode
{
public:
bool isLeaf;
uint32_t vectorIndex;
union {
double threshold;
double prob;
};
uint32_t left;
uint32_t right;
};
Apparently, this very straightforward naive approach is:
- Slow. Loading new trees on runtime took too much time
- Wasteful on memory
- Wasteful on disk space, the binary encoding on disk
So the very first improvement I made was to change the binary encoding into one I can load straight to memory with very little parsing.
uint32: number of trees
uint32: number of nodes in tree
uint16: is_leaf - [0, 1]
if not leaf:
uint16: vectorIndex
uint16: index of left node
uint16: index of right node
double: threshold
else:
uint16: 0
uint16: 0
uint16: 0
double: tree score
.
.
.
In C++, a node struct looks like:
struct RandomForestNode
{
uint16_t isLeaf;
uint16_t vectorIndex;
uint16_t left;
uint16_t right;
union {
double threshold;
double prob;
};
};
Now by simply reading the data of the tree into memory and just filling the vector of trees with pointers to different places in the data, I'm done with the loading of the trees.
But it still takes too much space on disk and memory, so I wanted to compact it.
I've created a lookup table for threshold and tree scores values. Many values, such as 0 and 1, repeated many times so using a 16 bits index to values table instead of 64bit double saved a lot of space.
The isLeaf has just two possible values, True or False, so 1 bit is enough for it. I've taken one bit off from the left index and one bit off from the right index and used it in order to tell if the left node is a leaf and if the right node is a leaf. Because the score value is now index that I'm able to encode in 15 bits, if the node is a leaf, the index could be of the value. That enables me to remove the leaf nodes entirely.
The new struct is as follows:
16 bits: vectorIndex
15 bits: leftIndex / scoreIndex
1 bit: isLeftLeaf
15 bits: rightIndex / scoreIndex
1 bit: isRightLeaf
16 bits: thresholdIndex
And it still stored on disk the same way it is stored in memory, so loading takes no time at all.
Next, I'm working on an algorithm to cut identical parts between trees and store them only once, but for now, it seems to be a rare case that is not worth the trouble.
If you have ideas on how to improve this struct farther, please do share.

