Introduction
C++ was originally designed to support only single thread programming. In every application, there is one default thread. The execution control would go straight to the main() function (entry point for default thread), the program would execute in a pretty much sequential manner (one computation would complete before the next starts) and end of the story. But yet, that’s the Stone Age talk. There comes the multi-processor and multi-core systems and our single threaded, sequential programs became un-optimized for them. So there’s a need to utilize the computational resource efficiently and that’s exactly where concurrent programming appears. Concurrent programming allows the execution of multiple threads and thus we can write highly efficient programs by taking advantage of any parallelism available in computer system. C++11 acknowledged the existence of multi-threaded programs and the later standards also brought some improvements. In this series of article, I will not only talk about what concurrent programming is but we’ll also be looking into the features that C++standards 11, 14 and 17 have brought to support concurrent programming. If you’re new to the concept of concurrent programming itself or just interested to know about how things are done in C++, both are my intended readers. So follow along and eventually, you’ll get the essence of it.
Note: This article assumes your knowledge, familiarity and comfort with C++.
Concurrency and Concurrent Programming
Concurrency refers to the idea of executing several tasks at the same time. This can be achieved in a time-shared manner on a single CPU core (implying ‘Multitasking’) or in parallel in case of multiple CPU cores (Parallel Processing).
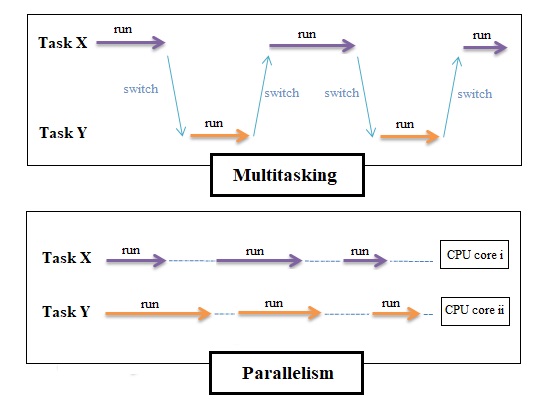
Concurrent program is a program that offers more than one execution path that run in parallel or simply saying a program that implements concurrency. These execution paths are managed by means of threads that execute concurrently and work together to perform some task.
Thread describes the execution path through code. Each thread belongs to a process (instance of an executing program that owns resources like memory, file handle, etc.) as it is executing the code of the process, uses its resources and there can be multiple threads being executed at the same time inside a process. Each process must have at least one thread that shows the main execution path.
Concurrency and Parallelization
When talking about computations and processing, concurrency and parallelism seem pretty similar. They are closely related as they can use the same software and hardware resource but yet different concepts so I feel the need to highlight the difference here.
Concurrency structures the program by allocating multiple control flows in it. Conceptually, these flows are executed parallel, although, in fact, they can be executed on a set of processors (cores) or on one processor with context switching (switching the CPU from one process or thread to another). This approach is otherwise known as multi-threading. Now the true parallelism is achieved through Parallel programming that aims at speeding the execution of a certain task up by means of using multiple equipment items (processors, cores, or computers in a distributed system). The task is divided into several subtasks that can execute independently and uses their own resources. Once all subtasks are complete, their results are merged. In practice, these two approaches can be combined to complement each other. For example, allocation of independent concurrent subtasks can help both structure a program and improve its performance.
Why Concurrency?
Speed: Up until 2002, making bigger and faster processors was the trend so the processor speed was increasing every 18 month as per Moore’s law. But since then, the paradigm shifted to slower processors put in groups (multi-core processors). Also GPU (graphics processing unit) were introduced which can range to hundreds even thousands of cores for a massively parallel architecture aimed at handling multiple functions at the same time. Now if we stick to old school programs that are not concurrent at all, only one core or thread is being used while rest of your CPU sits idle. That’s where we need to consider concurrent programming to utilize parallel hardware. Concurrent program make use of any parallelism available in computer system and thus makes the execution more efficient. Even in case of single CPU, concurrency prevents one activity from blocking another while waiting for I/O and thus can increase the speed dramatically.
Availability and Distribution: There can also be some external driving forces that are being imposed by the environment. For example, many things are happening simultaneously in real-world systems and so must be addressed in ‘real-time’ by software. This demands software to be reactive and respond to externally generated events at random times. Now it can be simpler to partition the system into concurrent pieces that can deal individually with each of these events.
Controllability: Concurrency also increases the controllability of the system as function can be started, stopped or can be interrupted by other concurrent function. This functionality is very hard to achieve when working with sequential program.
Now that we have developed basic understanding of what concurrency is and why we should be considering it, let’s move to some C++ specifics.
The Threading Library
As I mentioned earlier, C++ did not had any standard support for concurrent programming before C++ 11. You have to rely on libraries that were OS dependent like pthread for Linux or Windows API on windows. Though the concepts were the same, there was significant difference in how you implement them. The need for portable concurrent code was met by introducing the multithreading capabilities in standard C++11 that consists of two parts:
Standard Threading API provides you a portable way to work with threads using the <thread> header while memory model sets the rule that threads will follow when sharing data in memory.
C++14 did not bring a lot to the table but introduced Reader-Writer Locks to minimize the bottleneck. C++17 added more to the recipe and made most of the algorithms of the Standard Template Library available in a parallel version. Though, this was a brief overview of what C++ offers to support concurrent programming and let’s not forget synchronization, Atomic variable and high level asynchronous programming that we’ll be exploring later in the article. Let’s start seeing things in action beginning with multi-threading.
Note: There's no particular environment setup required to follow along the hands on part. You just need a text editor and C++ latest compiler supporting C++11, 14 and 17 functionality. The code is tested on both platforms, i.e., Windows with Visual Studio 2017 community edition and Linux (Ubuntu LTS18.04) g++ compiler. It would (should) work fine for you as well. You can also use any online compiler to test the code as well.
Multi-Threading
Thread is basically a lightweight sub-process. It is an independent task running inside a program that can be started, interrupted and stopped. The following figure explains the life-cycle of a thread.

More than one thread can be executed concurrently within one process (which refers to the idea of Multi-threading) and share the data, code, resources such as memory, address space, and per-process state information. Each C++ application has one main thread, i.e., main while additional can be created by creating objects of std::thread class.
void func() {
std::cout << "Concurrent execution in C++ " << std::endl;
}
int main() {
std::thread t1(func);
t1.join();
return 0;
}
Let’s break things down here. We created a simple function func that simply prints a line to the screen nothing fancy. std::thread t1(func) is going to launch thread that will execute our function while join() will make sure of waiting until t1 terminates. Let’s make a few changes to the above program to examine the workflow.
void func()
{
for (int i=0; i < 5; i++) {
std::cout << "Concurrent execution of thread in C++" << std::endl;
}
}
int main()
{
std::thread t1(func);
std::cout << "Main function thread executing..." << std::endl;
t1.join();
std::cout << "Main function exiting..." << std::endl;
return 0;
}
That’s what output of the above function looks like. Yours could be a little different. The main function thread execution could be in the beginning or anywhere. The reason is that there is no strict ‘sequence’ of execution, rather both threads execute at the same time (that’s what concurrency is about right!), but main function will always exit at the very end. join() makes sure that t1 terminates before main function exits.
Joining and Detaching Threads
When you create a thread, you need to tell the compiler what your relationship with it is going to be. Destructor for std::thread class checks whether it still has any OS thread attached to it and will abort the program if it has. Try experimenting with the above code by removing join() and though it will compile fine, it will abort when run. To avoid abortion, you must join a thread or detach from it.
join: waits for the thread to finish and blocks until the thread finishes execution.
detach: leaves the thread to execute on its own and no further involvement is required from you.
You can check if a thread is joinable or not by simply calling joinable() member function. This function returns true if the thread is joinable or false otherwise (a thread cannot be joined more than once or already detached). A simple check can be applied before joining the thread. Observe the following:
std::thread t1(func);
if (t1.joinable())
{
t1.join();
}
But why bother applying checks when you have another option available to make execution happen? Surely our examples would work fine if you replace join() with detach(). But here’s the catch. detach() make thread to run in background which can result in daemon thread (Linux terminology). You don’t know when a detached thread is going to finish so extra care is needed when using references or pointer (as things can go out of scope when a thread finishes executing). That’s the reason why join() is preferable in most conditions.
Other Ways of Creating Threads
Using function is just one way to creating and initializing thread. You can also use functor (function object of the class that overloads operator ()). This can be done as follows:
class functor_thread
{
public:
void operator()()
{
std::cout << "Thread executing from function object" << std::endl;
}
};
Now all we need is to initialize thread by passing an object of our above defined class to the thread constructor.
int main () {
functor_thread func;
std::thread t1(func);
if(t1.joinable())
{
t1.join();
}
return 0;
}
You can also use lambda expression (functional way) to achieve the same functionality.
std::thread t1([]{
std::cout<<"Thread executing from lambda expression…. "<<std::endl;
});
t1.join();
Identifying Threads
Now that we are working with multiple threads, we need a way to distinguish between different threads for the reasons of locking and debugging. Each std::thread object has a unique identifier that can be fetched using member function of std::thread class.
std::thread::get_id()
It is to be noted that if there’s no associated thread, then get_id() will return default constructed std::thread::id object and not of any thread. Let’s see an example that will clarify the idea.
void func()
{ }
int main()
{
std::thread t1(func);
std::thread t2(func);
std::cout << "Main Thread ID is " << std::this_thread::get_id() << std::endl;
std::cout << "First Thread ID is " << t1.get_id() << std::endl;
std::cout << "Second Thread ID is " << t2.get_id() << std::endl;
t1.join();
t2.join();
return 0;
}
Let’s stop here for a while and talk about std::this_thread. It is not a member function rather a namespace that contains global functions related to threading. Here are some functions that belong to this namespace.
get_id() | this_thread::get_id() Returns ID of the current thread |
yield() | Suspend current thread so that another may run |
sleep_for() | Thread will sleep for specified duration of time |
sleep_until() | Thread will sleep until the specified point of time |
priority() | Gets the priority of the current thread |
We’ve seen get_id() already in action. You can read more about the namespace here or else feel free to explore the namespace and work around other functions.
Passing Arguments to Thread
So far, we’ve just created threads using functions and objects but without passing any arguments. Is it possible to pass arguments to the threads? Let’s see.
void print(int n, const std::string &str)
{
std::cout<<"Printing passed number… "<< n <<std::endl;
std:: cout << "Printing passed string…" << str << std::endl;
}
We just created a function passing an integer as arguments to the function. Let’s try to call the function by invoking thread as we did before.
int main()
{
std::thread t1(print, 10, "some string");
t1.join();
return 0;
}
And it works. To pass arguments to the thread’s callable; you just need to pass additional arguments to the thread constructor. By default, all arguments are copied into the internal storage of the new thread so that it can be accessed without any problem. But what if we are to pass it by reference? C++ provides std::ref() wrapper to pass arguments by reference to the thread. Let me explain it with an example.
void func (int &n)
{
n += 1;
std::cout << "Number inside thread is " << n << std::endl;
}
int main()
{
int n = 15;
std::cout << "Before executing external thread, number is " << n << std::endl;
std::thread t1(func, std::ref(n));
t1.join();
std::cout << "After executing eternal thread, number is " << n << std::endl;
return 0;
}
Now it should be clear that if we don’t pass the argument by reference in the above case, the number would still be 15 even after the external thread execution. You can go ahead, try it and see for yourself.
Move Semantics (std::move())
Time for some extra sweet. Let’s compare the functions from our last examples.
void print(int n, const std::string &str)
void func (int &n)
Note that we passed our string literal in the first function by reference but we didn’t have to use std::ref() in order to access it while our approach with integer is different. The reason behind is that the string literal would be used to create a temporary string object which satisfies the needs for const reference while integer needs to be wrapped in std::ref() to be passed by reference.
Although it seems nice at first glance that we don’t need to use any kind of wrapper but creation of temporary objects is like an obstinate wart which tends to slow down the programs. C++ introduced move semantics to be used instead of coping the expensive objects with rvalue references (an expression is an rvalue if it results in a temporary object) and passing temporaries. For example, here’s a function that expects an rvalue reference to be passed.
void func(std::string &&str)
{
std::cout << "Moving semantics in action"<< std::endl;
}
And I can use it as follows:
std::string str = "Some String";
std::thread t1(func, std::move(str));
Now the call to move() is going to move the string str to the function rather than coping it. Here’s another interesting thing, std::thread itself is movable but not copy-able. It means that you can pass the ownership of OS thread between the std::thread objects but only one instance will own the thread at any one time.
std::thread t1(func);
std::thread t2 = std::move(t1);
t1 is executing our function func so now if I want to create another thread t2, the move() will move the ownership of thread t1 to t2 (t2 is now managing the OS thread). If you try assigning a thread that is already managing some OS thread, you’ll get an exception.
But How Many Threads Can We Create? (hardware_concurrency())
We’ve been talking about creating and manipulating threads but how many of them can be created specifically? That’s something known as hardware concurrency. You can get the numbers on your machine as follows:
std::cout << std::thread::hardware_concurrency() << std::endl;
The number displayed could be the cores on your machine as for me it is 4. But that’s wrong to ask. Hypothetically, you can create as many threads as the amount of memory on your machine but then the scenarios arise where your concurrent code would execute much slower than sequential so the right question is how many threads should you create. To answer this question, there’re number of factors to be considered. Bear with me a little theory.
Computation Intensive Program
If your code is number crunching and involves a lot of computations and processing huge amount of data, then the suggested number of threads should be less than or can be equal to the number of cores on your machine.
No. of threads <= No. of cores
IO Intensive Program
On the other hand, if your code is IO intensive, e.g., would be reading or writing a large amount of data, then the suggested number of threads are given as follows:
No. of threads <= No. of cores / 1- blocking factor
While blocking factor is the time a task will be spending being blocked. The reason I’m emphasizing this number is that if you exceed this limit, there is a greater chance that the performance of your program will go down. Just because you can create as many threads as you want does not mean you should.
What’s Next?
So far we’ve only seen how we can create and manipulate threads. But we haven’t talked about the part “Data is shared between the threads”. Simultaneous access to the same resource can give birth to a numbers of errors and thus create chaos. Consider a simple scenario where you want to increment a number and also output the result.
void f() {
++n;
}
Now when executing the above function concurrently, the threads will access the same memory location and one or more threads might modify the data in that memory location which leads to unexpected results and the output becomes un-deterministic. This is called race condition. Now the question arises of how to avoid, find and reproduce the above condition if already occurred. It’ll be picking up the things right from here in my next article of the series. Till then, feel free to explore and learn on your own.

