This blog picks up from an earlier blog where we downloaded files from BSE website. This article takes it further and adds another function to read these files and load them into Datastore.
Solution
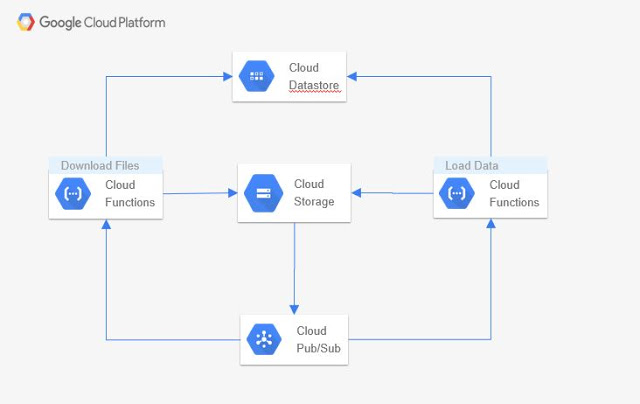
In the previous article, all components were added except the "Load Data" function. This is added and executed in this blog.
We first execute the code and then look at the explanation.
Setup
All that is required was setup in the previous blog, the only thing we need to do is download the function code and upload it to Google cloud and link to pubsub topic.
git clone https://github.com/skamalj/gcloud-functions.git
cd gcloud-functions/load-bhavcopy-data
gcloud functions deploy load_bhavcopy_data --trigger-topic bhavcopy-messages --source .
--runtime python37
Cleanup and Execute
If you have followed the earlier blog, you might have data entity "RecievedFiles" created in Datastore. This needs to be deleted - from datastore admin console.
The code will download and overwrite files in cloud storage, so there is no need to delete files from the bucket.
Now trigger the execution by adding a dummy file to cloud storage bucket like in the earlier blog.
You can see your data in datastore as below:

Code Explanation
The main function reads the event and passes the received filename to lock_and_load function.
lock_and_load
- The function uses transaction -line 5 - to ensure multiple processes do not upload the file and adds a status field to the entity with value "
Datastore'. - Another important point is the use variable -
load_data'. The process to load the data is - Read and lock the filename from "RecievedFiles" entity and then load the data into 'DailyBhavcopy' entity. It involves multiple entities and datastore does not support multiple entities in one transaction. So external variable is used, which can be set in the transaction scope - line 11- for locking and then use its value - line 12 - after coming out of transaction.
def lock_and_load(fname):
client = datastore.Client(project='bhavcopy')
load_data = False
try:
with client.transaction():
key = client.key('RecievedFiles', fname)
row = client.get(key)
if (row is not None) and ('status' not in row):
row['status'] = 'Datastore'
client.put(row)
load_data = True
if load_data:
store_data(fname)
logging.info('Data loaded in datastore for ' + fname)
else:
logging.info('No database entry for file or it is already loaded: ' + fname)
except Exception as e:
logging.info("Cannot start transaction for loading file "+ fname + ".Recieved error:" + str(e))
Store_data - Bulk Insert to Datastore
- This function parses the filename and then reads the file from storage and also unzips it. This piece of code is not shown in code block.
- Header columns are inferred from the first row in the file and also adds "
File_Date' column - In this function, we first load all the data in-memory:
- Line 1 below creates and empties array
- From Line11-17, we create single row
- This row is then appended to the array - Line 20
- So when the loop exits, we have all the data from file turned into entity rows in an array.
- We do this to avoid performance and contention issue due to high volume of single row puts.
- Instead we use
put_multi - Line25:27 - to insert 400 rows at a time, this is efficient. Max supported value is 500.
bhavcopy_rows = []
# First line of each file is header, we collect column names from this line and then for each
# subsequent row entity is created using file header fields as column names.
for line in data:
if not header_read:
headers = line.split(',')
header_read = True
else:
row_data = line.split(',')
bhavcopy_row = datastore.Entity(client.key('DailyBhavcopy',row_data[1]+'-'+extracted_date))
bhavcopy_row['FILE_DATE'] = file_date
for i in range(12):
if i in (1,2,3):
bhavcopy_row[headers[i]] = str(row_data[i]).strip()
else:
bhavcopy_row[headers[i]] = float(row_data[i].strip())
# Do not use extend() function, it changes the entity object to string.
bhavcopy_rows.append(bhavcopy_row)
logging.info('Collected '+str(len(bhavcopy_rows))+' rows from '+fname)
# Bulk insert has limied to maximum 500 rows, hence this block
for i in range(0,len(bhavcopy_rows),400):
client.put_multi(bhavcopy_rows[i:i+400])
logging.info(fname+": "+ "Storing rows from " + str(i) +" to "+ str(i+400))
History
- 21st January, 2019: Initial version

