This blog details how to setup multiplexed flow in Flume using Interceptor and Channel Selector. In addition, consolidation of events with HDFS sink is explained as well. The code (conf file) is available on github.
Pre-requisites
- This code is tested on my cloudera setup version 5.15. Explained in this blog.
- It uses data from
orders table in retail_db provided by cloudera. You can get this data from my github repo - Datasets
Scenario
In this exercise, we read through orders data, which has 4 fields, last field of the row is status column. The aim of the exercise is to read the data and send all orders with status as "COMPLETE" to one HDFS folder while all others go to another folder.
Input data looks like below, it is spread across multiple files and has ~68000 records.
1,2013-07-25 00:00:00.0,11599,CLOSED
2,2013-07-25 00:00:00.0,256,PENDING_PAYMENT
3,2013-07-25 00:00:00.0,12111,COMPLETE
4,2013-07-25 00:00:00.0,8827,CLOSED
5,2013-07-25 00:00:00.0,11318,COMPLETE
6,2013-07-25 00:00:00.0,7130,COMPLETE
7,2013-07-25 00:00:00.0,4530,COMPLETE
8,2013-07-25 00:00:00.0,2911,PROCESSING
9,2013-07-25 00:00:00.0,5657,PENDING_PAYMENT
Code Explanation
Initialize
- We create single source to read input data
- Two channels - one to flow "
COMPLETE" orders and other for everything else - Two Sinks - To store data from two channels separately
1,2013-07-25 00:00:00.0,11599,CLOSED
2,2013-07-25 00:00:00.0,256,PENDING_PAYMENT
3,2013-07-25 00:00:00.0,12111,COMPLETE
4,2013-07-25 00:00:00.0,8827,CLOSED
5,2013-07-25 00:00:00.0,11318,COMPLETE
6,2013-07-25 00:00:00.0,7130,COMPLETE
7,2013-07-25 00:00:00.0,4530,COMPLETE
8,2013-07-25 00:00:00.0,2911,PROCESSING
9,2013-07-25 00:00:00.0,5657,PENDING_PAYMENT
Create Interceptor
The interceptor, as the name suggests, intercepts each input event read from source and modifies it. We use regex interceptor to parse each line, read the status value for the line and then create a header field "status = {value}", where value is the actual status of the order. Example, if the status is COMPLETE, then the injected header will be "status = COMPLETE".
###
# Configure the spooldir source and create interceptor to insert header named "status"
###
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/skamalj/learn-flume2/orders_csv/
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
# Capture status , i.e last field in the comma separated input line
a1.sources.r1.interceptors.i1.regex = ^.*,([^,]+)$
#Captured data value is stored in header as "status=>s1".
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = status
- In lines 4-5, we set the source to read the input data for out directory
- In line 7, we set the interceptor as of regex type and then in line 8, we tell it to extract last field (
$ to hinge on the end of line) after comma. - In line 11-12, we set the name for this extracted value, which is
status.
- Hint to capture multiple values: If you have a regex to extract two fields say (.*),(.*), then you will set serializer as two fields "
s1 s2", and then also set the name for each one.
Setup Channel Selector
Look at the picture below to understand why we need selector:
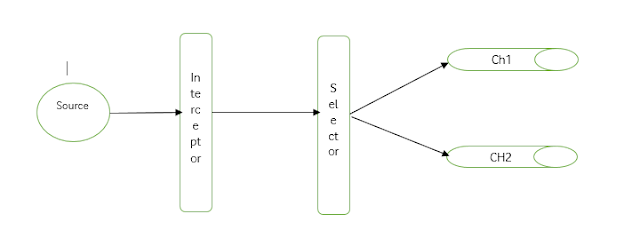
The source reads our csv input files and passes each line as event to interceptor. Interceptor reads the line and based on the value of last column, creates a header named "status" which holds the order status value. Since we have two channels and sinks, we need selector to decide as to which event should go to which channel. So selector is our "event router".
###
# Bind the source to the channels. Based on value fo "status"
# which is either 1 or 2 channel is selected. Any other value goes to channel 1
###
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = status
###
#If the status field value is COMPLETE then send the input to c1 else to c2.
###
a1.sources.r1.selector.mapping.COMPLETE = c1
a1.sources.r1.selector.default = c2
- In line 6 above, we tell selector to look at the value of "
status" in the header fields. - In line 10, we say if the value of status header is "
COMPLETE", then send the event to "c1". - Line 11 says, for everything else, send the event to "
c2".
Hint. You can modify the exercise to have 3 channels where c1 receives "COMPLETE" orders , c2 receives "PENDING" and c3 receives everything else or you can make simpler modification to send events with status COMPLETE and PENDING to c1 and rest to c2. (Add line a1.sources.r1.selector.mapping.PENDING = c1 below line 10).
HDFS Sink and Event Consolidation
Here, we setup hdfs sink for each channel, code for only one sink is shown below. Each sink consolidates 10000 events per file.
###
# Describe the sinks to receive the feed from channels
###
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/skamalj/learn-flume/orders/complete
a1.sinks.k1.hdfs.rollCount = 10000
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
- Here, lines 6-8 are important if events have to be consolidated. Consolidation can happen based on number of events (
rollCount), time interval to wait before creating new file (rollInterval) or size of the file (rollSize). - All 3 go together and to be specific, set the other values to "
0" to disable other conditions. So in our example, we roll to file when we have 10000 events. At the same time, we disable roll based on Interval and Size.
Rest of the code is just setting up another sink, linking the channels to sinks and configuring channels.
Execution
Run the code as below, from the directory where example.conf is placed, and check the output in the screenshot below.
Do make sure your input path is configured as per your system and hdfs path is also modified in the conf file.
flume-ng agent --name a1 --conf . --conf-file example.conf

So, here, you can see it creates two output directories, one for "COMPLETE" orders and the other for remaining orders. Each file holds 10000 records except the last one which will obviously have whatever number is left in the end.
All done, hope this was helpful.
History
- 21st January, 2019: Initial version

