In this blog, we look at how scheduling and data dependencies work in oozie coordinator job. We create a coordinator job with 6 occurrences and datasets with 11 occurrences. Jobs have dependency on data being available. We test this by creating the requisite data manually to trigger the jobs.
First the prerequisites.
Prerequisites
- This is all tested on cloudera 5.15 setup on gcloud. This blog explains how to set this up.
- Mysql
retail_db database. Load it from here. (Not required if you are ok with failed jobs - individual success or failure of jobs do not matter in this exercise.)
- Oozie workflows are explained in separate blog - over here.
- Git installed.
- Get the code from my github repository.
- Now update the references to directories and cluster
namenode and resourcemanager in coordinator.xml, workflow.xml and job.properties files, then move the folder learn-oozie to your hdfs home dir.
All explanation below is in reference to coordinator.xml file.
Code for Reference
coordinator.xml
<coordinator-app name="myfirstcoordapp" frequency="${coord:days(2)}"
start="2018-06-10T00:00Z" end="2018-06-20T12:00Z"
timezone="UTC" xmlns="uri:oozie:coordinator:0.1">
<controls>
<concurrency>1</concurrency>
</controls>
<datasets>
<dataset name="trigger_hiveload" frequency="${coord:days(1)}"
initial-instance="2018-06-10T00:00Z" timezone="UTC">
<uri-template>hdfs://cloudera-master.c.liquid-streamer-210518.internal:8020/
user/skamalj/learn-oozie/coord_input/${YEAR}-${MONTH}-${DAY}</uri-template>
</dataset>
</datasets>
<input-events>
<data-in name="datatrigger" dataset="trigger_hiveload">
<start-instance>${coord:current(-1)}</start-instance>
<end-instance>${coord:current(0)}</end-instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>hdfs://cloudera-master.c.liquid-streamer-210518.internal:8020/
user/skamalj/learn-oozie/coord_job</app-path>
<configuration>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>table</name>
<value>${table}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Schedule & Datasets
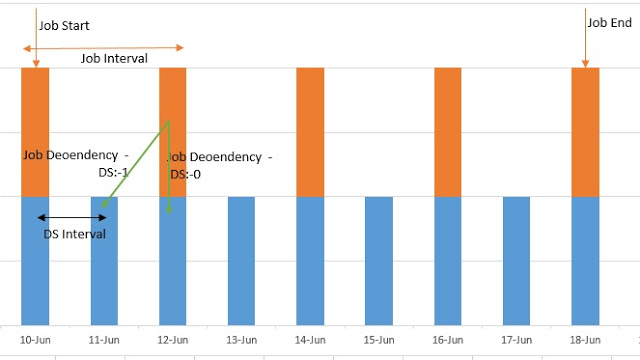
- Lines 1-3 coordinator-app<coordinator-app> <coordinator-app>tag defines the scheduling of the job or workflow. Here, the frequency is defined every two days. Identified by orange bars in the diagram.
- Lines 7-11 define the datasets, which has location and frequency of each dataset input-events. We define this as every day for our input dataset. This is blue bar in the picture, see that first job does not have any DS(-1) dataset available.
- Lines 13-15, define dependency of job on previous two datasets using
<input-events> tag <input-events>. Dataset 0 is the one that immediately precedes the job scheduled time, i.e., for job which is scheduled to start on 12th dataset requirement is of dataset from 12th and 11th. This is shown with green lines in the picture.
Dependency
First, initiate the coordinator job and check its status.
[skamalj@cloudera-master coord_job]$ oozie job
-oozie http://cloudera-master:11000/oozie -config job.properties -run
job: 0000000-180811114317115-oozie-oozi-C
[skamalj@cloudera-master coord_job]$ oozie job
-oozie http://cloudera-master:11000/oozie -info 0000000-180811114317115-oozie-oozi-C
This command sets up 5 jobs but none is running. Screenshot below:

Reason being, we have defined job dependencies on dataset "trigger_hiveload" in lines 13-15. These also define that job needs two datasets (-1 and 0) which immediately precede job nominal time (time at which the job is supposed to run not the time of actual run).
Check the Dependency and Trigger the Job
Run the below command to check the dependency for second job in the list.
oozie job -oozie http://cloudera-master:11000/oozie -info 0000000-180811114317115-oozie-oozi-C@2
This will show which dataset the job is waiting for. Screenshot below (see last line).
The above command shows only one dependency, but in hue you can check all dataset dependencies. See screenshot.
Trigger the Job
Now let's create the requisite directory and files and trigger the job.
[skamalj@cloudera-master coord_job]$ hdfs dfs -mkdir
-p /user/skamalj/learn-oozie/coord_input/2018-06-12
[skamalj@cloudera-master coord_job]$ hdfs dfs
-put _SUCCESS /user/skamalj/learn-oozie/coord_input/2018-06-12
[skamalj@cloudera-master coord_job]$ oozie job
-oozie http://cloudera-master:11000/oozie -info 0000000-180811114317115-oozie-oozi-C@2
Output will be as below, notice that now dependency has moved to previous day.
Create that dependency as well (use same commands as above with this new date) and you will see that job starts to run.
All done! So now you know how to create oozie jobs with data dependency and set schedule and then trigger them.

