Introduction
The prerequisites for this article are my previous article written in December 2017 related to neural patterns and an overview of the Hebbian Theory which generally states that the neurons that fire together wire together.
The purpose of this article is a closer look into differences between artificial neural networks and real nervous systems and understands why natural networks perform better.
The Problem
The human brain needs only few samples to learn about and recognize an object. An animal only needs an experience to record the danger and avoid it the next time. In the same time, a machine learning system may need a million samples to retain the image of a cat. What did we do wrong?
First, let's take a look at how we design a hand writing recognition system. We need to feed a deep learning algorithm several hundreds of samples (digits or letters) to obtain the character recognition.

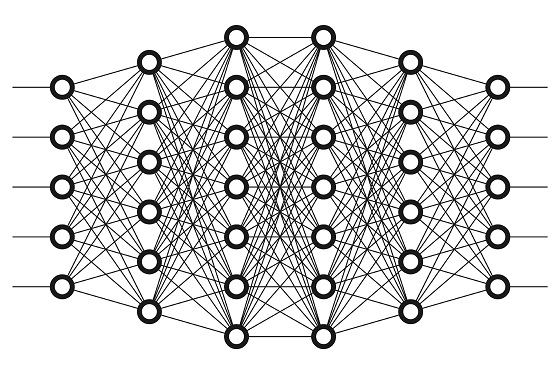
What Artificial Neural Networks Do
Based on numerous input samples, the deep learning network adjusts its internal parameters (the weights of perceptrons, which basically creates internal patterns similar to the brain) so the output will be the same for a similar input. It's somehow like a median of the inputs having the same shape. Even if we provide to the network a digit that is not in our input set, the system is still able to recognize it, if it is similar to one in input data. For each letter, the system builds (by mathematically adjusting its internal parameters) an area of tolerance around a shape in which the same output still triggers.
Basically, we provide enough samples until we map all input neurons inside the area of tolerance to the same output by creating artificial internal patterns.

What Natural Networks Do?
For a single input, a similar area of tolerance takes shape in the FIRST PASS because of the natural neurons design (see below). Similar neurons doing the same task are grouped in the same area in cortex, like mapping the view in front of the eyes into pixels of a monitor.
When an image is recorded, not only are the exact neurons mapped triggered but also they send signals to the nearby neurons which are put in excitability state but not sending the signal further (not enough synapses are made to overcome the threshold of the action potential). It’s like the chemical link is done towards a nearby neuron, but this one is not triggered because it is not mapped to an input neuron (a pixel in the existing image) and it is not excited enough to generate its own chemicals back. But if the signal comes from a similar image in future, this one may trigger and will find the chemical connection from the old nearby neuron while generating its own and will trigger an already existing output (part of the pattern of the old image).
The pattern initially generated is huge due to the number of synapses and less prone to changes due to its size.
Of course, the explanation is purely intuitive but it is obvious that there is this factor that contributes decisively to a faster learning.
The Proximity of the Neurons
And of course, their 3D design that makes this possible.
In current ANN design, a single sample creates a single pattern directly linked to exact input neurons. A second sample sent to the trained network is not recognized, even if it is very similar to the first one. Few common input neurons won’t trigger the same output.
The Solution
What we really need to is to redesign the neural networks so a single sample creates not a single internal pattern but a fuzzy area of tolerance around input and a set of patterns mapped to them that will trigger the same output for a similar sample.
Maybe instead of backpropagation, we need to take into consideration the graph theory or we need to focus more on 3D design and neuromorphic computing.
Current Design Drawbacks
If we take a look at the deep learning picture above, we can see an obvious flaw (not really a flaw but more like part of our evolutionary design). We can see that the neurons in the same level are not connected. This will not happen in any real network.
Also, the real networks are not layered at this level. There are layers of neurons indeed but not for their basic task. Even there are some advanced designs like recurrent neural networks (RNN) that wire perceptrons a bit differently, we are still not there. The current architecture is limited to narrow processing and require too many input samples. It needs to adjust more towards the real design and take proximity into account. Deep learning performs great but it is only part of the design evolution.
I am confident that this breakthrough will occur within 10 years, the snowball is already rolling.
Wrong Focus
While we have not understood or emulated the neural system of C-Elagans consisting of 302 neurons, we do the following:
- we design subsystems for AGI – consciousness or moral modules, personality, rules, etc.
- we create organizations to regulate cyborgs
- we get scared to death that cyborgs take our jobs
- we just put together billions of transistors like a human brain and we expect to behave like a person (please, no)
- we also train deep learning on billions of written pages and expect the system to think like a human (I will be back on this one)
- we create more and more chips that move current temporary models to hardware
- we are scared that machine learning is biased instead of being aware by the statistical results provided and how we use them. Biasing is a matter of usage, not of statistics.
Instead, we do not:
- study to exhaustion the C-Elegans nervous system
- emulate those 300 neurons until we obtain similar results (software and hardware)
- understand neurotransmitters and why they effect the full network – they are acting like an accelerator or they make the full network slower and different
- build millions of neuronal mathematical and topologic models until we fix the flawed design
- create mathematical models based on patterns, maybe shift math from sums and functions to graph theory
- focus on how to train different models on the same network
- focus on how to make thinking machines, reuse output and rewards for input
- make neural networks able to assimilate real concepts
- make a primitive language to extract or modify data in a neural network
- study how blind-deaf born persons can still understand the world and learn language
- and many more
We are in the bicycle age, we dream to reach for the moon but we haven't designed the rocket engine yet. Instead, we are trying to build a bigger bicycle or put more horns for this purpose.
What we do now on von Newman architecture is only research. From a practical point of view and usage is waste of resources. Complexity is part of the game, the more neurons we add, the better these systems will perform. And we really need a lot of them for highly intelligent systems.
It will take thousands of attempts and years of failures, because one single detail missing or in the wrong place may cause a totally different behavior (model vs brain). But in the end, we will get the same functionality.
Natural Language Processing (NLP)
Deaf born people still can learn to talk. They can still understand the world. Their brain is still able to build internal concepts and representation of real world objects.
If we feed a machine with billions of pages, will it ever be able to think? Imagine a deaf person seeing another person. The visual representation put together arms, body, head and all other body parts. Is there any page in the input data that describes this, so these concepts do not remain separate? Are there enough pages to put together all concepts that are linked through other senses and methods?
There are many questions here but it is obvious that words and words associations should be doubled by concepts, connections, memory, history, etc. to obtain more than automated answers. But for this, we need a thinking machine, we do not have the base yet.
AGI and Consciousness
Just like Dr. Robert Ford said in Westorld, there will be no inflection point where machines become conscious. Slowly, the communication with machines will reach high enough standards that we become empathetic with them and accept them as different beings. Think at today assistants. They will look stupid in the beginning but improve in time. Singularity will be related to NLP standards and new Touring tests like the ones imaginated by DARPA:
On stage, a woman takes a seat at the piano. She:
- sits on a bench as her sister plays with the doll.
- smiles with someone as the music plays.
- is in the crowd, watching the dancers.
- nervously sets her fingers on the keys.
There will be probably no AGI, only ASI, each subsystem we designed already performs better that the similar real. When put together, the system will be superior to humans in many fields.
Conclusions
I have tried to put in hyperlinks above some interesting lectures. I would also like to add one of the best efforts today to push things forwards, the videos of Lex Fridman at MIT.
Nobody knows if another AI winter is coming but certainly the things are not like 30 years ago. Until then, we need to focus on basics: make artificial neurons work like real ones.

