This article is about the humble elementary school multiplication algorithm, which is the fastest algorithm in some cases. Showing ideas to work with high level language, assembler and C implementation and comparison, some about testings, some thoughts about faster algorithms.
This article is part of a series of articles:
Multiple Precision Arithmetic: A recreational project
Teaching the Long Multiplication Algorithm to a Digital Computer
This is the third part, we will teach our computer the long multiplication. In this article, we will focus on naive elementary school algorithm.
Many different algorithms exist for long multiplication, the simplest of them all is the elementary school algorithm, which is very important to do right on the computer, because despite big O tells us it's a O(n2) algorithm, each of its primitive parts are very fast, does not require extra memory allocation, so it has advantage over all "fastest" algorithms for small values of n (let's say less than hundred of 64-bit words):
Better algorithm exists, but there is a threshold for which the elementary school algorithm is faster than any other. Using another perspective to say the same: any faster algorithm is going to be slower than this when n below a given threshold: as a consequence, it is useful to hybrid asymptotically faster algorithms with "elementary school" when n below an accurately selected threshold; on source code, you will find that Karatsuba algorithm is faster when used in conjunction with this algorithms.
So this algorithm besides being the humblest, is worth the highest grade of optimization, you are probably going to use it at leaf levels of any divide and conquer algorithm, that means it is going to be used a lot.
I hope to be able to write something on faster algorithms soon.
Ok, said that, let's remember how to do it manually, then port it to computer. This chapter is divided into three parts: on the first, we will find a primitive operation, then we'll analyze the algorithm, finally we will discuss something about implementation on hardware.
1 . Simple Multiplication Using Positional Notation, Base 10
Let’s start with “simple multiplication” (or primitive multiplication, you name it), the multiplication of pair of numbers A and B, where A and B have exactly one digit, this is going to be the primitive upon which we will build our long multiplication.
To compute simple multiplication, you could repeat sums, for example 3x4 can be computed as 3+3+3+3 (4 times).
…or just lookup pre-calculated b-base Pythagorean table.
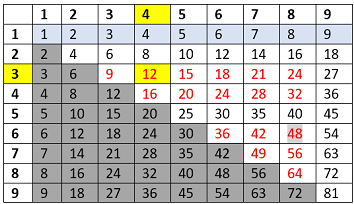
Example: 3x4 using Pythagorean table, base 10: search intersection between row 3 and col 4, the result is 12.
Multiplying a single digit number by a single digit number may return 2 digits numbers (never more).
Now we have a primitive operation to build the long multiplication, we call it "simple multiplication", we will use Pythagorean table when doing manually and CPU MUL instruction (or equivalent) on computer hardware.
2 . Long Integer Multiplication
The long multiplication algorithm is the following, you have a string of digits A, a string of digits B, foreach position i, j of strings A and B, multiply A[i] * B[j] then write the partial result at position i+j, finally sum partial results.

3 . Long Integer Multiplication and the Digital Computer
We revised the algorithm using pencil and paper with decimal digits. The CPU version is exactly the same. We use the analogy that a CPU register is like a decimal digit and that instead of Pythagorean table lookup, we use an equivalent hardware instruction, which is the multiplication instruction.
There are implementations using base 2 (because 1-bit Pythagorean table is quite simple) but my conjecture is that approach is inefficient (unless implemented in hardware).
I try now to show why using biggest CPU registry is better than using smaller registers or worse single bits: for example, I'll compare multiplication on base 4 and on base 16.
Consider the multiplication of hex E * D (decimal result is 182).
On base-16, we do single simple multiplication: ExD=decimal 182
On base-4, the same multiplication is 32*31, thus we have to compute: (1*2),(1*3),(3*2),(3*3), get their respective results, put partial results in a matrix then compute the long sum.
Conjecture: The moral of the story is: doubling the bits, we can reduce by a factor 4 (at least) the algorithm work for bigger numbers.
Corollary: 64-bit CPU makes our algorithm do at least 4 times less work than a 32-bit CPU (on large numbers).
Corollary: Even if each single 64-bit multiplication costs 4 times more than 32-bit (not, it costs more electricity but not 4x the time) we should still have big gain using 64-bits, because less long sums are needed and less inner loops iterations, not to say about base 2.
Corollary: To multiply 32-bit numbers, better to use 32-bit operation, because single 32-bit operations cost less than 64-bit operation.
Corollary: Any base-2 implementation cannot compete with any n-bit software long multiplication.
Disclaimer: The above conjecture is not evidence based.
The Algorithm
The basic algorithm is the same we learned at school, it is applicable both to computer and to pencil/paper, as usual here I provide a high level overview of the algorithm. It have a big advantage in comparison to other faster algorithms: it's memory requirements are easily predictable, requires no extra allocation than the result array.
Some Consideration Before You Turn This Into Software
To turn the algorithm into a program, we have to think a little about how to effectively implement it.
On sum and subtraction things were easy, but now need more support by our high level language to efficiently use hardware. My conjecture is that the bigger the registry we use, the faster the multiplication is going to be. To falsify that hypothesis, we need to check 2 variants of the code, one using all the CPU power, the other working on what the language we use could provide.
Let me clarify a bit: suppose, to be working on a 64-bit computer: not all high-level languages have a multiplication function that returns two 64-bit values from a single multiplication (as 64 bit CPUs usually do) nor they all have a 128-bit integer type.
We must choose a strategy between two extremes:
- Sacrifice portability, write machine specific to use fastest instruction for each specific machine
- Sacrifice performance and use whatever your higher-level language provides
My initial intention was to go for option 2: we just want to know how it works, MP libraries created by real experts do exist if you want better throughput, after I decided to use just a little bit of assembler because of some restriction on int size with my compiler, I'm not really using "fastest machine instructions" but neither a pure high level language solution.
Let’s start with an algorithm that is portable, I’ll use constructs that are easily available on a high level language (the C Language, for instance) and try to keep the algorithm as simple as possible. There is only a tiny part of the code that needs to access "secret" hardware feature (multiply two register sized ints and return 2 register ints) because my compiler doesn't let me use 128 bit integer types.
Using the code Understanding the Code
Note to the reader: Here, I explain how I decided to implement the thing, this is not the only way.
If we had a compiler supporting 128 bit integers, I'd do something like the following: I'd be using two unsigned integer datatypes provided by the language: one we’ll call “word type”, then we need another unsigned type, twice as big, that we’ll call “double word”. The ideal, as per the conjecture I made on previous paragraphs, is that the word type has maximum CPU register size.
Some languages provide union type, using union make things simpler, otherwise we use bit shift to get the upper word of the multiplication result.
On this article, I will use union, a decent starting point could be something like (pay attention to endianness):
typedef uint32_t _word_t;
typedef uint64_t _dword_t;
typedef union
{
_dword_t dword;
struct
{
_word_t L;
_word_t H;
} Pair;
} _word_struct;
But, I have to fight against the fact that my VC++ compiler doesn't (or did not) have a 128 bit type, but my machine is x64 machines, that forces me to use 32 bit word type (on multiplication), and that's not ideal.
As a compromise, I came up with this solution: write a single algorithm, then have the Pythagorean lookup be delegated to another function, that can be written in C or maybe in assembler (the assembler routine will not be called inline probably, but it's probably faster than the downgraded multiplication of half-words).
The result is the following:
#include "BigIntSimple.h"
#include <assert.h>
typedef reg_t (*_mul_func)(reg_t A, reg_t B, reg_t* Hiword) ;
EXTERN reg_t cpu_multiply(reg_t A, reg_t B, reg_t * high);
#ifdef NO_DWORD_INTS
static reg_t c_multiply(reg_t A, reg_t B, reg_t * high){ ... }
#else
static reg_t c_multiply(reg_t A, reg_t B, reg_t * high){ ... }
#endif
static numsize_t LongMultiplicationPortable
(reg_t *A, numsize_t m, reg_t *B, numsize_t n, reg_t * R, _mul_func mfunc)
{...}
numsize_t LongMultiplication(reg_t *A, numsize_t m, reg_t *B, numsize_t n, reg_t * R)
{
return LongMultiplicationPortable(A, m, B, n, R, cpu_multiply);
}
numsize_t LongMultiplicationNoAssembly
(reg_t *A, numsize_t m, reg_t *B, numsize_t n, reg_t * R)
{
return LongMultiplicationPortable(A, m, B, n, R, c_multiply);
}
and this is the small x64 assembler version of the Pythagorean lookup, which (as we'll see later) make the C code runs 2,5 times faster.
.code
cpu_multiply proc
mov rax, rdx
mul rcx
mov qword ptr[r8], rdx
ret
cpu_multiply endp
end
Here is the complete C listing for one of the LongMultiplicationPortable function, on source you find different versions.
static numsize_t LongMultiplicationPortableV2
(reg_t *A, numsize_t m, reg_t *B, numsize_t n, reg_t * R, _mul_func mfunc)
{
numsize_t outBuffSize = m + n, k;
reg_t hiword, loword;
int carry;
for (k = 0; k < outBuffSize; ++k)
R[k] = 0;
for (numsize_t j = 0; j < m; j++)
for (numsize_t i = 0; i < n; i++)
{
k = i + j;
loword = mfunc(A[j], B[i], &hiword);
R[k] += loword;
carry = R[k] < loword;
++k;
R[k] += hiword + carry;
carry = (R[k] < hiword) | (carry & (R[k] == hiword));
while (carry)
{
R[++k] += 1;
carry = R[k] == _R(0);
}
}
while (outBuffSize > 0 && R[outBuffSize - 1] == 0)
outBuffSize--;
return outBuffSize;
}
Some more notes to let you understand the above code: A and B are input long numbers, the reg_t type is sized to the machine register size, m is size of A and n the size of B, also we receive a pre-allocated R number (the caller should allocate it by considering that it could contain up to n+m digits). No input checking, no precondition checking, no clean data structure, plain and raw, this must not be an API, this is a primitive that an API will wrap and will also be used by the long division algorithm, so we don't want to do costly stuff at that level.
Remember that A and B numbers have least significant digit at index 0 and most significant digit at index A[m-1] and B[n-1].
Most significant digit of A and B is supposed to not be 0 but the algorithm works anyway, it’s just a waste of time and memory.
I also created in a rush an assembler x64 version, which I somewhat tested and looks like it's working, then I was not happy and created a new version that is a little bit better and I pasted it here below, any x64 expert will do better than that, just for reference:
.data
.code
LongMulAsmVariant_1 proc
xor rax, rax
test rdx, rdx
jz immediate_ret
test r9,r9
jz immediate_ret
push rbp
mov rbp, rsp
push r12
push r13
push r14
push r15
mov r10, rdx
mov r11, [rbp + 60o]
add rdx, r9
xor rax,rax
_reset_loop:
mov [r11+rdx*8], rax
sub edx, 1
jns _reset_loop
xor r12, r12
_outer_loop:
cmp r12, r10
je _outer_loop_end
xor r13,r13
mov r15, [rcx + r12 * 8]
_inner_loop:
cmp r13, r9
je _inner_loop_end
lea r14, [r11 + r12 * 8]
mov rax, [r8 + r13 * 8]
lea r14, [r14 + r13*8]
mul r15
add rax, [r14]
adc rdx, [r14+8]
mov [r14], rax
mov [r14+8], rdx
jnc _inner_loop_continue
lea r14, [r14+8]
_carry_loop:
lea r14, [r14+8]
mov rax, [r14]
add rax, 1
mov [r14], rax
jnc _carry_loop_ends
jmp _carry_loop
_carry_loop_ends:
_inner_loop_continue:
inc r13
jmp _inner_loop
_inner_loop_end:
_outer_loop_continue:
add r12,1
jmp _outer_loop
_outer_loop_end:
lea rax, [r11 + r10 * 8]
lea rax, [rax + r9 * 8]
_compute_size_loop:
cmp r11, rax
jg _end_compute_size_loop
sub rax, 8
mov r10, [rax]
test r10, r10
jz _compute_size_loop
_end_compute_size_loop:
add rax, 8
sub rax, r11
shr eax, 3
pop r15
pop r14
pop r13
pop r12
mov rsp, rbp
pop rbp
immediate_ret:
ret
LongMulAsmVariant_1 endp
end
Testing the Implementation
Without having to dig too much into details, we basically need some tests to verify correctness of any implementation, in source code, you will find some of those tests. Here I list some possibilities:
- Checkout that A * B = B * A, commutative property
- Check that A * 1 = A. (one is identity element)
- Check that A * 0 = 0. (that's trivial)
- If you already implemented SUM, checkout that the series An = (An-1+An-1) = A1*2n . I give you an example algorithm for that:
- start with A1 = 5, set also An=5.
- repeat, say 7, times An=An+An, successive values for An are (5,10,20,40,80,160,320,640) at the end, An value is 640.
- then execute Temp=A1*27 which is 5*128 = 640, finally check that Temp= An
- Check associative property: (A*B)*C=A*(B*C)
- Checkout that (A*B MOD m) = (A MOD m) * (B MOD m), if you choose modulo 9 on base 10 this is called "casting out nine test", on 32 bits number, an easy one is 232-1. Casting out nines (in our case casting out 232-1s) is easy to do since you just need to sum all the single digits to compute modulo: an example on base 10.
53 * 31 = 1643 -> 1+6+4+4 = 14 -> 1+ 4 = 5, so 53*31 MOD 9 = 5.
53 -> 5 + 3 -> 8, so 53 MOD 9 = 8
31 -> 3 + 1 -> 4, so 31 MOD 9 = 4
8 * 4 = 32 -> 3 + 2 = 5, so (53 MOD 9) * (31 MOD 9) = 5
The 2 moduli on bold text have the same value, so far so good.
On source code, I provide algorithm for compute A MOD 264-1, this test is not bulletproof but if it says "your algorithm is wrong", then the algorithm is definitely wrong.
- Compare implementation against each other, if one of them is wrong, you will notice it, if both are wrong, you have a good chance to notice it unless they have the same error.
- Do tests on peculiar input numbers for which the output is well known.
- Also do tests on some manually crafted numbers so that you are sure to trigger some part of your code: for example, if you have optimization for when you get a zero digit, you better create a number having some zeroes inside otherwise your branch will have a low chance to be ever executed on random tests.
- We should have some tests for handling the possibility that an implementor will mess up the carry detection algorithm, that's difficult to do so I didn't do it, just be extremely careful and test the carry detection part thoroughly in a separate project, because this is a kind of error very unlikely to be caught doing random number tests.
By having a routine passing all of the above tests, we may have a good confidence on implementation correctness. Of course, we have to test it against some well crafted sumbers and then run some tests on randomly chosen numbers having any possible different length.
Proofing Correctness Using Math
If you want to achieve better confidence, besides adding more and more tests, you can always proof your implementation using mathematical techniques which are beyond what I am able to do, but more or less it is something like: for each line of code, build a proof that the program state after execution of instruction is correct (respects assertions), for example.
carry = ((operand + operand2 + carry) < (operand + carry)
To proof correctness of this instruction, first you need to have some assertions about the state of the program like: after execution, carry value will be 1 if operand + operand 2 + carry overflows, then you should proof that for each possible input state (result, operand, operand2, carry) that you know because you had a proof for all the previous instructions, the output state respects your assertion.
For example in this case, suppose that your computer works on base 10, so result, operand and operand2 are base 10 digits and carry can be only 1 or 0.
We can then say that the instruction is not respecting assertion if we have operand = 9, operand2 = 0 and carry = 1:
carry = (9 + 0 + 1) < (9 + 1)
so:
carry = 10 < 10
and since we working modulo 10:
carry = 0 < 0
thus:
carry = 0
But we had overflow because 9 + 0 + 1 does not fit a base 10 digit.
So did I prove that the instruction is not correct? Depends on what we proved about input state, if we can prove that operand will never be 9, then the instruction is correct...
That's just the idea, things are more profound but maybe you liked the idea and will dig into it.
Aftermath
Note that the proposed algorithm requires much more work than the Long sum.
There are three nested loops, the second of those is using multiplication, a relatively expensive op, but on modern hardware, it is expensive on terms of power consumption and transistors rather than time.
In general, a multiplication is many times more expensive than a sum, but less expensive than a division... because the division runs many multiplications so multiplication algorithm performance will affect directly division performance.
The division will be the last part of the series. Since the algorithm complexity is O(N^2), the test I made is on 4KB*2KB numbers (10K iterations per run) if I keep 512KB numbers as I did for sum it runs for too long.
The above results were produced by VS 2017 C++ on i7 processor yr2011. (The algorithm is not parallel so using 1 core.)
Anyway, I think I demonstrated that the 32 bit version of the algorithm (the one on the yellow bar, which corresponds to the LongMultiplicationNoAssembly func) runs over two times slower than the version using native 64 bits CPU MUL, as it should be in theory, would be nice to have a good C version able to use 64 bit registers.
I re run the tests after removing the supposed "optimization" of skip loop when we have one of the digit operands be zero: I started thinking about the probability to get a full 64 operand at zero... well in base 10 could be smart to improve a case that is going to happen 1 in 10 times, but in base 64 is a really bad idea to write some code to handle a case that is going to happen 1 in billion-billion times, the above gray assembler procedure already ignores that "optimization" and it's a lot faster than the other, let's make the other algorithm do the same so we can do a fair comparison.
Here are the updated stats, improvements are small but measurable:
The above results were produced by VS 2017 C++ on i7 processor yr2011. (The algorithm is not parallel so using 1 core.)
A final thought, we should get a better idea of which is the speed limit we could aim in finding better implementations:
What I achieved here on best implementation is to run 180 million of word multiplications per seconds per core, if I'm not wrong, check out my calculation:
My 3GHZ CPU spent then, if Windows performance counter is correct, average 16 cycles of clock per word multiplication, it is maybe possible to do better using this algorithm.
Below, some new results were produced by VS 2022 C++ on i9-10900 processor. (the algorithm is not parallel so using 1 core).
History
- 2017: Started writing
- 6th February, 2019: Almost ready to publish
- 20th March, 2019: Added new implementation to try to demonstrate my conjecture
- 9th June, 2020: Added suggestion to test for implementation correctness
- 11th June, 2022: Online

