This article completes our discussion we started in part 1. Previously, we discussed a few use-cases of streaming and, with the help of an example, showed some performance issues. We had seen how mal-implemented streaming pipeline can trigger memory consumption off the charts. Furthermore, we visualized the data-flow in such pipelines and identified target state of the implementation. Identified goals can be delineated as:
- Avoid the usage of in-Memory buffers to improve on runtime memory
- Work only with necessary fixed size buffers
- be able to create efficient pipeline (chain of operations) end-to-end (source to target)
- Create an API that offers:
- Composability: composition of operations
- Readability: composition are declarative
- Maintainability: promotes single responcibility principle for each underlying composed operation
- Elasticity: open to any exotic and/or regular data processing requirement
- Reusability: permits run-time mutation in a composed chain in a deterministic manner
In this article, we are going to elaborate on the implementation, with respect to defined goals, and several strategical use-cases of such implementation. Following is the table of contents:
Basic Building Block
In part 1, we showed one of many possible ways to achieve efficiency by using nested “using” block while passing streams in cascade fashion. In fact, unknowingly/knowingly, we exploited the Open-Ended nature of intermediary streams in the call-chain. As we know such cascade of streams can improve runtime performance, it suffers from a lot many other problems. Lets investigate some of those issues quickly. Lets say, we have a given streaming cascade which handles file reading, decompression and conversion from JSON text to some object <T>; as shown:
public T StreamCascade<T>(FileInfo jsonFile, ...)
{
using(var fileStream = new FileStream(uncompressedJsonFile, ...))
{
using(var textReader = new TextReader(fileStream, ...))
{
using(var jsonReader = new JsonReader(textReader, ...))
{
}
}
}
}
What we would like is to have full control on the behavior of it, such as:
- Conditional JSON deserialization: Sometimes we would like to Deserialize JSON string to some known object type otherwise just collect JSON string itself, i.e.
public object DeserializeObjectFrom(FileInfo uncompressedJsonFile)
{
using(var fileStream = new FileStream(uncompressedJsonFile, ...))
{
using(var textReader = new TextReader(fileStream, ...))
{
if (deseralize)
{
using(var jsonReader = new JsonReader(textReader, ...))
{
}
} else {
return textReader.ReadToEnd();
}
}
}
}
Now, immediately we start recognizing the limitation of such a construct. Some observations are:
- the return type is now "
object", instead of some concrete <T> type due to the presence of conditional if. - conditional
if itself added yet another nesting level.
Now, to extend our argument further, we would like to pass both compressed and uncompressed file path to it (i.e. making decompression conditional too). Furthermore, we desire to expose all configurational param to our function to control the behavior of serialization, buffer size, cancellation, character encodings, file stream params so on and so forth.
Above all, we desire to add base64 ops (conditionally too!) and/or encryption support? In short, we want to make this function UGLIER!
Based on some experiments we recognized that in order to achieve performance either we were creating dedicated cascade of "using" and duplicating code, or, creating some non-readable complex code fragments. And we decided, those implementation were not acceptable to us; and, thus we decided to create our APIs. But, before we look at it, lets cover some literature.
FUNCTIONAL PROGRAMMING
Functional Programming is a programming paradigm whose explanation is beyond the scope of this article. Here, we will just take a minor tour around first-class functions and higher-order functions as both are important for our implementation. Fortunately, in C# .Net, we have the notion of Functions as first-call citizen, notion of delegates, presence of pre-defined Action<> and Func<> delegates, facility to define Lambda's using these pre-defined delegates. On top of that, as these Action<> and Func<> delegates are generic in nature, creating higer-order function is just a matter of assigning a right type to those generic <T>s (i.e. type placeholders). Lets consider a hypotheical example to understand the use:
Problem Statement:
Generate a positive random integer. If it is odd then multiply it by 2. Print the results to Console.
A normal procedural program might look like following:
public void GeneratePositiveEvenRandomInteger()
{
var randomGenerator = new Random();
var nextRandom = randomGenerator.Next(0, int.MaxValue/2);
if (nextRandom % 2 == 1)
{
Console.WriteLine(nextRandom * 2);
}
Console.WriteLine(nextRandom);
}
Well and good. Now, lets see how we can achieve the same functionality using Functions:
public int MultiplyByTwo(int value)
{
return value * 2;
}
public int GeneratePositiveEvenRandomInteger(Func<int, int> oddToEvenFunc)
{
var randomGenerator = new Random();
var nextRandom = randomGenerator.Next(0, int.MaxValue/2);
return nextRandom % 2 == 1 ? oddToEvenFunc(nextRandom) : nextRandom;
}
var results = GeneratePositiveEvenRandomInteger(MultiplyByTwo);
Console.WriteLine(results);
Ooook! We yet do not see any benefit of it; rather at first glance it might look overwhelming. But, hold on there, observe that:
MultiplyByTwo logic has been separated out of the whole logic, This mean if tomorrow we need to change the logic of "odd number processing" it would be easier for us to make modification only to this function and leaving remaining logic intact (separation of concerns). Plus, unit testing those functions would be easier too!
Yet, it might not look convincing, right! Lets extend the idea a bit further based on following observations:
- GeneratePositiveEvenRandomInteger is doing several things:
- it is creating a new instance of
Random at each call - it is checking the oddness of the
nextRandom value. - returning appropriate value based on oddness
Separating concerns in our example is our next stop.
CLOSURE
It would be sad to not to cover closure when talking about Functional Programming (you may refer to this article for some interesting details). Most of times, you will see an anonymous function (or lambda) as example to demonstrate the concept of closure. Lets do something similar to start with. Let's say in order to have our randomGenerator (from above code), we create a factory function that wraps (closes) on the Random() instance, which is:
public Func<int> RandomIntFactory(int min, int max)
{
var randomGenerator = new Random();
return () => randomGenerator.Next(min, max);
}
var randomIntFactory = RandomIntFactory(0, int.MaxValue/2);
Everytime, we call randomIntFactory() (mark the paranthesis "()" after the name), we get a new random number create by "randomGenerator" (same instance!). In order to better understand how all this magic works, we can change the above code as follows (NOTE: Below code just conveys the idea and by no mean represents the EXACT runtime behavior of .Net code under execution):
public class ClosureClass()
{
public Random _random;
public int _min;
public int _max;
public ClosureClass(Random random, int min, int max)
{
_random = random;
_min = min;
_max = max;
}
public int NextRandom()
{
return _random.Next(min, max);
}
}
public Func<int> RandomIntFactory(int min, int max)
{
var closure = new ClosureClass(new Random(), min, max);
return closure.NextRandom;
}
Now, with the help of first-class function ("NextRandom") it is clearer how magically those values are still present for the next random value generation beyond the scope of RandomIntFactory function! So the magic was that we are still holding a reference to a class-instance-method, which in turn, linked to the class instance itself and the instance itself holds required data (everything is now connected and makes sense!)
Note: Going forwards, we will be using only anonymous functions/lambads in the code and enjoy the closure support provided by .Net itself.
Playing by the rules
After covering closures, we in position to discuss again our unfinished tale of GeneratePositiveEvenRandomInteger. Lets create function for everything (i.e. 1 function for 1 responcibility):
public Func<int> RandomIntFactory(int min, int max)
{
var randomGenerator = new Random();
return () => randomGenerator.Next(min, max);
}
public bool IsOdd(int value)
{
return value % 2 == 1;
}
public int MultiplyByTwo(int value)
{
return value * 2;
}
public int Identity(int value)
{
return value;
}
public int GenerateNumberAndApply(Func<int> factory,
Func<int, bool> predicateFactory,
Func<int, int> whenTrue,
Func<int, int> whenFalse)
{
var value = factory();
return predicateFactory(value) ? whenTrue(value) : whenFalse(value);
}
var factory = RandomIntFactory(0, int.MaxValue/2);
Func<int> generatePositiveEvenRandomInteger = () => GenerateNumberAndApply(factory,
IsOdd,
MultiplyByTwo,
Identity);
Console.WriteLine(generatePositiveEvenRandomInteger());
Everytime, we call generatePositiveEvenRandomInteger() (mark the paranthesis "()" after the name) we have our newly generated random even integer. Ooook! But except each function has become single liner, we do NOT yet see any remarkable genius in it, right? But, observe, we have gain two (2) highly sought characterstics: Maintainability & Reusability!
Why Maintainability?
Though, it looks longer compared to our original GeneratePositiveEvenRandomInteger code; but we should appreciate the fact that all the functions can now be easily tested with their own isolated scope of concerns. Consider, a case, where all the involved functions (i.e. number factory, predicateFactory, and both whenTrue and whenFalse logic) are complex in nature; here, we have achieved a true separation of concerns and even with complex artifacts, we can manage their intricated interplay easily. Aboveall, consider following signature of GenerateNumberAndApply with Generics (i.e. <T>):
public T GenerateNumberAndApply<T>(Func<T> factory,
Func<T, bool> predicateFactory,
Func<T, T> whenTrue,
Func<T, T> whenFalse)
{
var value = factory();
return predicateFactory(value) ? whenTrue(value) : whenFalse(value);
}
var factory = RandomIntFactory(0, int.MaxValue/2);
Func<int> generatePositiveEvenRandomInteger = () => GenerateNumberAndApply<int>(factory,
IsOdd,
MultiplyByTwo,
Identity);
Console.WriteLine(generatePositiveEvenRandomInteger());
Now, we are free to use any generic type, that requires exact same conditional processing; just pass the compatible functions and enjoy! Also, notice, this function has become a strong candidate to be a library function!
Why Reusability?
Consider suddenly we got following new requirement:
Problem Statement:
Generate a positive random integer. If it is even then add 1. Print the results to Console.
Now, to fulfill this new requirement, we need to make following minor change:
public int AddOne(int value)
{
return value + 1;
}
var factory = RandomIntFactory(0, int.MaxValue/2);
Func<int> generatePositiveOddRandomInteger = () => GenerateNumberAndApply<int>(factory,
IsOdd,
Identity,
AddOne);
Console.WriteLine(generatePositiveOddRandomInteger());
So instead of re-writing a complete new function, just to make this minor change, we wrote a new single liner function and re-used existing artifacts!
Not Convinced!
Still the functionality is NOT reflecting the problem statement out of the box! Thats to say, it is missing Readability. Thats true, so adding expressiveness (declarative way) to the code is our next stop.
Adding Sugar!
We know C# is not a declarative programming language. To bring declarative"ness" to our code, we took help from another feature of the laugauge: Extension methods (a.ka. syntactic sugar!) (NOTE: We do not want to fall in the chaotic arguments whether usage of extension methods is an anti-pattern or not! Below example is to simply demonstrate how to enrich expressiveness to those plain delegates).
We know, in the language itself (C# of course), we cannot do much with delegates, hence on those Func<> and Action<>. Apart from, some invocation related methods and associated parameters, there is nothing much provided by the framework. Yet, thanks to Extension methods, we can attach (Visitor kinda) functionality to those. Lets build some of those methods on our random number generation purpose:
public static class HelperExtension
{
public static Func<int> GenerateInt(this Random value, int min, int max)
{
return () => value.Next(min, max);
}
public static Func<Func<int, int>, Func<int>> If(this Func<int> factory,
Func<int, bool> predicateFunc)
{
return whenTrue => () => GenerateNumberAndApply(factory,
predicateFunc,
whenTrue,
Identity);
}
public static Func<int> Then(this Func<Func<int, int>, Func<int>> conditionFunc,
Func<int, int> whenTrue)
{
return conditionFunc(whenTrue);
}
public static void And(this Func<int> func, Action<int> apply)
{
apply(func());
}
}
Action<int> print = val => Console.WriteLine("Value is: " + val);
var randomGenerator = new Random();
randomGenerator.GenerateInt(0, int.MaxValue/2)
.If(IsOdd)
.Then(MultiplyByTwo)
.And(print);
If we ignore bit of C# grammer, while reading the final chain of method call, we experience the following WOW-effect (i.e. Readability):
The WOW-effect (a.k.a. Readability):
randomGenerator.GenerateInt(0, int.MaxValue/2).If(IsOdd).Then(MultiplyByTwo).And(print); =>
Random generator, please generate a new random int, if the number is odd, then multiply the number by two and print the resultant number!
Let's try again:
randomGenerator.GenerateInt(0, int.MaxValue/2).If(val => !IsOdd(val)).Then(AddOne).And(print); =>
Random generator, please generate a new random int, if the number is NOT odd, then add one to the number and print the resultant number!
Equipped with this knowledge lets explore a new way of streaming.
Functional Streaming
As we are going to use the functional programming concepts, we coin the term "Functional Streaming" to tag our APIs. As we will discuss the basic implementation under this title, before adding features to it.
Revisiting Open-Ended Stream
In part 1, we cursorily covered Open-Ended streams. Basically, we call a Stream an Open-Ended stream, when its constructor (Ctor) signature matches following rough pseudo signature:
class SomeStream : Stream
{
public SomeStream(Stream baseStream, ...)
{
... Ctor implementation ...
}
... class implementation ...
}
Internally, when we read (if itʼs either bi-directional or returns CanRead=true) from such stream, it internally reads from the Ctor injected stream (baseStream parameter in above example). Eventually it may manipulate those bytes and provide those as an outcome. Based on configured buffer size, such streams should be capable to read baseStream as many times as needed. We call this mechanism buffer-mutate-forward (BMF) mechanism. We say that a stream that exhibit such characteristics can be called Mutated-Byte-Generators or simply “Generators” for this discussion (though the term "Generator" has a large scope). Following pseudo code exhibits the same idea:
class SomeStream : Stream
{
public SomeStream(Stream baseStream, ...)
{
... Ctor implementation ...
}
public bool CanRead => true;
public int Read(byte[] buffer, int offset, int count)
{
while (buffer != full and baseStream.HasData)
{
baseStream.Read(localBuffer, localOffset, localCount);
If there is NO transformation required, then the function
is an IDENTITY function (returns the localBuffer back).
var mutatedBytes = PerformDataTransformation(localBuffer, localOffset, localCount);
mutatedBytes.CopyTo(buffer);
}
}
... class implementation ...
}
In similar way, when such stream is either bidirectional or, at least, returns CanWrite=true, when can write on it. Again, internally, it writes mutatedbytes on the injected stream while maintaining buffer state. Following pseudo code represents writing mechanism:
class SomeStream : Stream
{
public SomeStream(Stream baseStream, ...)
{
... Ctor implementation ...
}
public bool CanWrite => true;
public int Write(byte[] buffer, int offset, int count)
{
If there is NO transformation required, then the function
is an IDENTITY function (returns the localBuffer back).
var mutatedBytes = PerformDataTransformation(buffer, offset, count);
baseStream.Write(mutatedBytes, ...);
}
... class implementation ...
}
We found enormous potential in such, out of the box, capability of Stream implementation that we based our APIs around it; instead of designing something afresh. Letʼs dissect the concept further.
Visualizing Pipeline
The best way to work on any implimentation is to start with the visualization before writing any code. Thus, lets see how pipelines actually works with the help of following illustration:
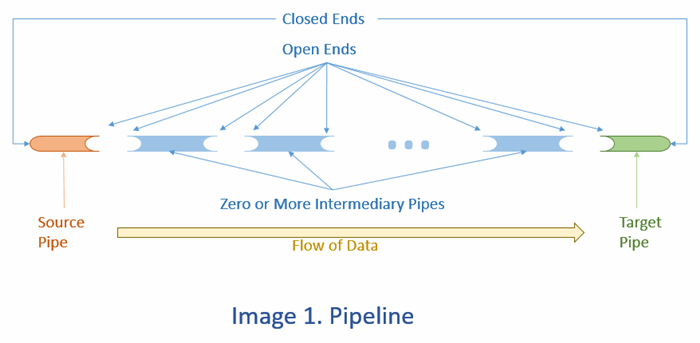
In above diagram we identify three (3) distinct types of pipe:
- Source pipe: which is the first pipe of the pipeline. It contains data (in some form). It is closed at left-hand side and open to accept a new pipe on the right hand side.
- Intermediary pipes: These are optional and connected (if at all) to Source pipe in tandem (like train wagons to the engine in tandem) and finally the last of those is connected to target pipe.
- Target pipe: it is the last pipe in the pipeline that terminates the pipeline. It is open on left-hand side to be connected to either source pipe (in absence of intermediary pipes) or to the last of those intermediary pipes.
Meditating on these thoughts for a while, we can recognize that our:
- Open-ended streams (as discussed above and in part 1) are perfect candidates for Intermediary pipes
- Closed ended streams (discussed in part 1) with
CanRead=true (i.e. reader streams) are Source candidates defined on data types like string, byte[], T[] (where T is some well-defined Type that can be serialized to bytes or string) etc... - Closed ended streams (discussed in part 1) with
CanWrite=true (i.e. writer streams) are Target candidates defined on data types like StringBuilder, writable MemoryStream, List<T> (where T is some well-defined Type that can be serialized to bytes or string) etc...
Based on above listed observations and knowing the how to achieve our goals of all *-ability (Reusability, Maintainability and Readability), all we need to do is to convert those streams into Generators. Next stop is creating on of those simple Generator.
Hoisting Generator(s)
Lets again, we restart our journey with those nested "using" block:
Comments contains part of explanation!
public T DeserializeObjectFrom<T>(FileInfo uncompressedJsonFile)
{
using(var fileStream = new FileStream(uncompressedJsonFile.FullName, ...))
{
using(var textReader = new StreamReader(fileStream, ...))
{
using(var jsonReader = new JsonReader(textReader, ...))
{
}
}
}
}
The problem we had with above code is that the second (2nd) "using" block is inside of the first (1st) one (similarly 3rd "using" inside of 2nd one... so on and so forth). Thus, in order to separate the concerns related to each stream, we need to hoist those inner ones out! As shown in following illustration:

In order to do such hoisting, we go back to the principles of Functional programming as what we discussed above. Surprisingly, we discussed such of an implementation already! Do you remember how did we separate the "If" logic from the "Then" action? Lets revisit it:
Comments contains part of explanation!
public static Func<Func<int, int>, Func<int>> If(this Func<int> factory,
Func<int, bool> predicateFunc)
{
return funcForWhenTrue => () => GenerateNumberAndApply(factory,
predicateFunc,
funcForWhenTrue,
Identity);
though, it is very well possible to pass "whenTrue" as parameter of
}
public static Func<int> Then(this Func<Func<int, int>, Func<int>> conditionFunc,
Func<int, int> whenTrue)
{
return conditionFunc(whenTrue);
}
Lets try some code hoisting on these streams (based on above ideas):
public static Func<Stream> PullData(this FileInfo someFileInfo, ...)
{
return () => new FileStream(someFileInfo.FullName, ...);
}
public static Func<TextReader> ThenGenerateText(this Func<Stream> prevHoist, ...)
{
return () => new StreamReader(prevHoist(), ...);
}
public static Func<T> AndJsonDeserialize(this Func<TextReader> prevHoist, ...)
{
return () =>
{
using(var jsonReader = new JsonReader(prevHoist(), ...))
{
}
};
}
With the above snippet, we have created three (3) generators successfully (at least for example sake):
- PullData : Generator of bytes (i.e.
byte[]) of the File pointed by supplied FileInfo. If we want we can call it immediately and use any of FileStream method on it; but its not that much interesting in itself, as it serves as source pipe in our pipeline. - ThenGenerateText : Generator which is capable of generating text segments (i.e.
char[]) based on the underlying supplied stream. Again, not very interesting to call it immediatly on it as it serves as intermediary pipe in our pipeline. - AndJsonDeserialize : Generator of
<T> object instance based on underlying text segment generator! Yes, we can call it immediately as it serves as an example of our target pipe in the pipeline.
Using these three (3) example pipes... creating a json_file-to-object pipeline is a piece of cake as shown below:
var myObject = new FileInfo("Path to my json file")
.PullData(...)
.ThenGenerateText(...)
.AndJsonDeserialize(...);
Not Convinced!
Yes, we agree too! To set an example it was a good exercise, but, practically it makes no sense creating all those extension methods on each type we encounter... even in this small example, we created extensions on 3 different types:
- PullData on
FileInfo - ThenGenerateText on
Func<Stream> - AndJsonDeserialize on
Func<TextReader>
If we continue on this path we have to handle a lot many variations, which can quickly create a chaos in the code. What we need is something that remains constant i.e. we need to identify a <T> which remains same for all of our extension methods (something like universal streaming object)!
PUSH Vs. PULL
In the part 1, we showed a typical streaming usage as pipeline and also identified associated artifacts and their respective interplay in the pipeline. And, based on the nature of streams (Unidirectional Vs Bidirectional), we identified data-flow related requirements which can be summarized in following tables.
PUSH Based Streaming
We call streaming operation as "PUSH based streaming" when we have a datasource and we have streaming pipes which are writable. In other words, in the pipeline, we have AT LEAST one (1) pipe which is Unidirectional and write-ONLY (i.e. CanRead=false).
For example, in C#, GZipStream (same for DeflateStream) is write-only when using it to compress data. Thus, if we want to stream data which involves compression, we have no choice then constructing write-only pipeline!
We call this pipeline as "PUSH based pipeline" and the First pipe (source pipe) of this pipeline we named as Push(...). Thus, "Push(...)" extension method can be applied to any of below listed source pipe. Example: someString.Push(...), someStream.Push(...) etc.
In the same spirit, we define various intermediary pipes (extension methods) while keeping ".Then" as prefix on them.
Finally, target pipes (also, extension method) having ".And" as naming prefix.
PUSHing Data from Source towards Target1
SOURCE PIPE
(.Push pipe) | INTERMEDIARY PIPEs
(.ThenXXX pipes) | TARGET PIPE
(.AndXXX pipes) |
- string
- StringBuilder
- byte[]
- FileInfo
- ArraySegment<byte>
- Any Stream implementation (thus, FileStream, MemoryStream etc)
- Generic <T>
- Any implementation of IEnumerable<T>
|
- Serialization
- Text Encoding
- Compression
- Hash Computation
- Base64 operations
- Encryption
- WILDCARDs operations2
|
- Any Stream implementation (thus, FileStream, MemoryStream etc)
- byte[]
- ArraySegment<byte>
|
1API is open to more Source/Intermediary/Target Pipes, as long as they can produce compatible signature
2Wildcard operations are Ad-hoc byte-manipulation requirements for example: Counting the bytes in the stream without buffering, Stream Fan-out (a.k.a. TEEing) etc... |
As most of the streaming operations can benefit Async-Await APIs of C#, we have identified Func<PushFuncStream> to be our universal representative of our extension methods, where PushFuncStream struct is defined as follows:
public struct PushFuncStream
{
public Stream Writable { get; }
public bool Dispose { get; }
public CancellationToken Token { get; }
public PushFuncStream(Stream writable, bool dispose, CancellationToken token)
{
Writable = writable.CanWrite.ThrowIfNot(DdnDfErrorCode.Unspecified,
"Cannot write on the stream",
writable);
Dispose = dispose;
Token = token;
}
}
We will see associated implementation in the next section.
PULL Based Streaming
Similarly, we call streaming operation as "PULL based streaming" when we have a datasource and we have streaming pipes which are readable. In other words, in the pipeline, we have AT LEAST one (1) pipe which is Unidirectional and readable ONLY (i.e. CanWrite=false).
For example, in C#, GZipStream (same for DeflateStream) is read-only when using it to decompress data. Thus, if we want to stream data which involves decompression, we have no choice then constructing read-only pipeline!
We call this pipeline as "PULL based pipeline" and the First pipe (source pipe) of this pipeline we named as Pull(...). Thus, "Pull(...)" extension method can be applied to any of below listed source pipe. Example: someByteArray.Pull(...), someStream.Pull(...) etc.
No surprise that for Pull pipeline too, we define various intermediary pipes (extension methods) while keeping ".Then" as prefix on them; and, target pipes (also, extension method) having ".And" as naming prefix.
PULLing Data from Source to Target1
SOURCE PIPE
(.Pull pipe) | INTERMEDIARY PIPEs
(.ThenXXX pipes) | TARGET PIPE
(.AndXXX pipes) |
- Any Stream implementation (thus, FileStream, MemoryStream etc)
- byte[]
- ArraySegment<byte>
|
- Deserialization
- Text Decoding
- Decompression
- Hash Computation
- Base64 operations
- Decryption
- WILDCARDs operations2
|
- string
- StringBuilder
- byte[]
- FileInfo
- ArraySegment<byte>
- Any Stream implementation (thus, FileStream, MemoryStream etc)
- Generic <T>
- Any implementation of IEnumerable<T>
|
1API is open to more Source/Intermediary/Target Pipes, as long as they can produce compatible signature
2Wildcard operations are Ad-hoc byte-manipulation requirements for example: Counting the bytes in the stream without buffering etc... |
Again, in order to take benefit of Async-Await APIs of C#, we have identified Func<PullFuncStream> to be our universal representative of our extension methods, where PullFuncStream struct is defined as follows:
public struct PullFuncStream
{
public Stream Readable { get; }
public bool Dispose { get; }
public PullFuncStream(Stream readable, bool dispose)
{
Readable = readable.CanRead.ThrowIfNot(DdnDfErrorCode.Unspecified,
"Cannot read from the stream",
readable);
Dispose = dispose;
}
}
Let's discuss associated implementation around these concepts.
IMPLEMENTATION NOTE: Worth to mention, if our pipeline is made up of bidirectional pipes only, then both PUSH and PULL based pipeline will yield identical results.
API Implementation
It would be very interesting we see the implementation by considering our original trivial task from part 1, which was:
Problem Statement:
Give a path of a binary file, read all its bytes. First, decompress it using GZip compression algorithm, then deserialize data as a well-defined Object array (i.e. List<T> where T is known) using JSON serializer.
And we recognized following distinct operations, namely:
- Read all bytes from the given file
- Use GZip algorithm to decompress those bytes
- With Json serializer create
List<T> (T is known or it is a generic place holder it hardly matters) from decompressed bytes
Lets prepare our Functional Streaming artifacts to achieve the task:
public static Func<PullStreamFunc> Pull(this FileInfo fileInfo, ...)
{
return () => new PullStreamFunc(new FileStream(fileInfo.FullName, ...), true);
}
public static Func<PullStreamFunc> ThenDecompress(this Func<PullStreamFunc> previous,
bool include = true)
{
return previous.ThenApply(p => {
var prevSrc = p();
var unzip = new GZipStream(prevSrc.Readable,
CompressionMode.Decompress,
!prevSrc.Dispose);
return () => new PullFuncStream(unzip, true);
}, include);
}
public static T AndParseJson<T>(this Func<PullStreamFunc> previous, ...)
{
var prevSrc = previous();
using(var txtReader = new StreamReader(prevSrc.Readable, ...))
{
using(var jsonReader = new JsonReader(txtReader, ...))
{
T instance = ... serialization logic ...
return instance;
}
}
}
public static Func<PullFuncStream> ThenApply(this Func<PullFuncStream> src,
Func<Func<PullFuncStream>, Func<PullFuncStream>> applyFunc,
bool include = true)
{
return include ? applyFunc(src) : src;
}
With above constructs, following would be the solution:
Problem Statement & Solution:
Give a path of a binary file, read all its bytes. First, decompress it using GZip compression algorithm, then deserialize data as a well-defined Object array (i.e. List<T> where T is known) using JSON serializer.
=>
List<T> objectList = new FileInfo("Path of File", ...).Pull()
.ThenDecompress()
.AndParseJson<List<T>>( . . . );
REMARKs: As we never used any in-memory buffer (i.e. MemoryStream) in the whole operation; we achieve our target state that we visualized in part 1.
The API
NOTE: If you are NOT interested in using our APIs, please feel free to skip this section!
Useful Links:
As mentioned above we have divided our implementation in 2 parts:
- PUSH based pipeline: when we have at least one (1) pipe which is write-only.
- PULL based pipeline: when we have at least one (1) pipe which is read-only.
In fact, to facilitate some operations (features), we have added an adapter to convert PULL pipeline to PUSH pipeline. For e.g., if we are reading bytes from some WebAPI method using PULL based pipeline. But at the same time, we want to save the bytes to compressed file on local disk; in such a case, again without buffering data in memory, we can convert our Pull pipeline to Push pipeline and add Compression pipe on it.
The signature of this adapter extension function is:
public static Func<PushFuncStream, Task> ThenConvertToPush(this Func<PullFuncStream> src,
int bufferSize = StdLookUps.DefaultBufferSize)
{
return ...;
}
public static Func<PushFuncStream, Task> ThenConvertToPush(this Func<Task<PullFuncStream>> src,
int bufferSize = StdLookUps.DefaultBufferSize)
{
return ...;
}
Simplifying Keystrokes
VS Studio intellisense helps us discovering method names once we start typing a few characters. Exploiting intellisence capabilities, in order to simplify the usage, we have divided our API pipes, with three (3) distinct prefixes:
- First pipe operations have either
.Push or .Pull prefix. - Intermediary pipes are optional (i.e. pipeline can contain zero or any number of pipes in tandem) and are always prefixed with
.Then. - Target pipe are prefixed as
.And.
By knowing these prefixes one can quickly discover methods.
Once source/target are identified, following signature represents streaming pipeline:
source.PullXXX( ... ).ThenXXX( ... ).ThenXXX( ... ) ... .AndXXX( ... );
source.PushXXX( ... ).ThenXXX( ... ).ThenXXX( ... ) ... .AndXXX( ... );
All above methods have their equivalent ASYNC counterparts. But the chain signature does NOT change (except await in front of it). Following image illustrate the idea of such pipeline at both sender side and at receiver side.
Meta-Pipelines
For the moment, we have been only talking about requirement based pipeline composition. It is true that using such highly reusable and composable pipes, we are able to produce features fast, yet, for each feature we still need to write the pipe composition code. It is like adding a new GET endpoint to a REST service based on new requirement. But, it is tiring too, right? Thats why Facebook came up with the design of GraphQL! With the help of Meta-Pipelines, we define something once and use it's sub-components again and again (i.e. Reusability in broad sense)!
With our API, creating such meta-pipeline is possible and easy. We coin the term "Meta-Pipelines", i.e., pipelines whose behavior is driven by meta-data. Let's see consider following trivial problem statement:
Problem Statement:
Giving a file path, if extension is .zip consider it is GZip compressed file, else a regular file. File contains array of records of some well known type <T>. Read those records from file and create List<T>.
Based on the statement, we know that knowing whether file path terminates by ".zip" or not, we need to apply the compression. Except compression, remaining of the code is same in both cases.
If you are still thinking of writing code using "If-Else", forget it! Following is the way to write Meta-Pipeline with our APIs:
public static bool UseZip(string filePathOrName)
{
return filePathOrName.EndsWith(".zip");
}
fileInfo.Pull( ... )
.ThenDecompress( ... , include:UseZip(fileInfo.FullName))
.AndParseJsonArray<T>(...);
Notice that whenever UseZip returns false; our pipeline bypasses Decompress pipe as if we wrote the code as: "fileInfo.Pull( ... ).AndParseJsonArray<T>(...);" (all thanks to Identity bahavior driven by "include" boolean we explained above).
Another example of such meta driven pipeline usage can be in Web based streaming applications, where meta information about compression, encryption, encoding etc can be obtained from Request Headers. One can construct a static pipeline with as many pipes attached in the pipeline as necessary; and, mask unrequired pipes based on such boolean during content-negotiation phase at runtime.
Knowing this, we can design meta-info based solution and remain confident about runtime behavior of the program.
Elastic Pipelines
We have already covered above, that only Source (.PullXXX or .PushXXX) and Target (.AndXXX) pipes are required pipes of our streaming pipeline. All the ".ThenXXX" pipes are optional; thus, we can have zero or as many of those as we need in order to build the pipeline. This make our API very flexible/elastic.
Though, we have implemented many quotidian pipes (also two exotic one which we will discuss below) as a part of our library; we know our library is NOT exhaustive for every use case (for e.g. it does not contain pipe for Brotli compression). Thus, we have keep all the ends open for ease of extension. If one need to create a new pipe to be used with our lib, below are the simple rules to follow during implementation a new pipe:
- If pipe is PULL based
- If pipe is on a new source (Lets say
TNew): Create a function which accepts an instance of TNew and returns instance of Func<PullFuncStream> (similarly adapt for async counterparts) - If its intermediary pipe: Create a function which accepts an instance of
Func<PullFuncStream> and returns instance of Func<PullFuncStream> (similarly adapt for async counterparts). Inside the implementation, read data from stream obtained from Readable property of input PullFuncStream. - If it is target pipe: Create a function which accepts an instance of
Func<PullFuncStream> and returns TOut (or void). (similarly adapt for async counterparts)
- Similarly, if pipe is PUSH based
- If pipe is on a new source (Lets say
TNew): Create a function which accepts an instance of TNew and returns instance of Func<PushFuncStream> (similarly adapt for async counterparts) - If its intermediary pipe: Create a function which accepts an instance of
Func<PushFuncStream> and returns instance of Func<PushFuncStream> (similarly adapt for async counterparts). Inside the implementation, read data from stream obtained from Writable property of input PushFuncStream. - If it is target pipe: Create a function which accepts an instance of
Func<PushFuncStream> and returns TOut (or void). (similarly adapt for async counterparts)
Next, we discuss two (2) of such exotic pipe we have added in our library using elastic nature of the core API concept.
TEEing & Super-TEEing
Like Unix Pipes ("|"), Unix TEE (command tee) is yet another famous operation. The basic concept of TEE is to read once and replicate (out) more than once (in loose sense). In other words, for each input, it can handle writing it on multiple targets. Same concept is illustrated in the image below.
TEEing is a very interesting use case in streaming application; replicating source stream, to write on multiple targets, has profound use-cases in Data replication, Data Broadcasting etc. You might have heard about Apache Kafka, known MQs (like Rabbit MQ etc) or pub-sub systems like REDIS.
In our APIs, we have added an "concurrent-writer" (intermediary) pipe which exactly does the same. For evey received chunk it replicates data on connected streams concurrently! This pipe is ONLY available on PUSH based (writer) pipeline which make sense too. Nonetheless, as PULL-based pipeline can be converted to PUSH-based pipeline using our "ThenConvertToPush" pipe, theoritically and practically, such concurrent writing can be done when consuming PUSH APIs.
The signature of this this pipe is:
public static Func<PushFuncStream, Task> ThenConcurrentlyWriteTo(this Func<PushFuncStream, Task> src,
Stream writableStream,
...)
{
return ...;
}
await someSource.Push()
.ThenConcurrentlyWriteTo(someStream, ...)
.AndWriteStreamAsync(yetAnotherStream);
await someSource.Push()
.ThenConcurrentlyWriteTo(someStream1, ...)
.ThenConcurrentlyWriteTo(someStream2, ...)
...
.ThenConcurrentlyWriteTo(someStreamN, ...)
.AndWriteStreamAsync(yetAnotherStream);
We coin the term "Super-TEEs" for the concatenated TEEs which can support stream replication along with some intermediary data mutation. Following image illustrate the idea:
Creating such Super TEEs are intuitive using our APIs. Consider a hypothetical case where:
Case Statement and Solution:
We would like to json serialize a List<T>, save json to a local file; at the same time, stream GZipped bytes to web endpoint and, also, save that Gzip data on a shared disk after encryption.
=>
await someList.PushJsonArray( ... )
.ThenConcurrentlyWriteTo( localFileStream, ... )
.ThenCompress( ... )
.ThenConcurrentlyWriteTo( webStream, ... )
.ThenEncrypt<...>( ... )
.ThenConcurrentlyWriteTo( sharedDiskStream, ... );
Byte Counting
Finally, we present one last of our exotic pipes implementation that simply counts the byte. The use-case is to perform such counting measure to embed as header values of response (for e.g. HTTP-Headers) or to precalculate those to satisfy some meta queries (like HTTP Head method). The signature of the pipe is:
public static Func<PushFuncStream, Task> ThenCountBytes(this Func<PushFuncStream, Task> src,
out IByteCounter byteCounter,
...)
{
return ...;
}
Consider again following hypothetical requirement:
Problem Statement & Solution:
Read a file and save its contents as GZipped file and also compute compression ratio.
=>
IByteCounter counterBeforeCompress;
IByteCounter counterAfterCompress;
await someFileInfo.Push( ... )
.ThenCountBytes(out counterBeforeCompress)
.ThenCompress( ... )
.ThenCountBytes(out counterAfterCompress)
.AndWriteFileAsync(targetFileInfo, ...);
Console.WriteLine("Compression Ratio: " + (counterAfterCompress.ByteCount / counterBeforeCompress.ByteCount * 100));
This pipe is available on PUSH pipeline as both .Then (intermediary) and .And (target) pipes. However, on PULL pipeline as .Then (intermediary) pipe only.
Commentary
Based on above (long) discussion, finally we summarize the achieved goals:
- We avoided in-Memory buffers to improve on runtime memory
- Implement all intermediary pipes only with necessary fixed size buffers
- Presented efficient pipeline with the help of end-to-end (i.e. source to target) chain of operations
- Created an API that offers:
- Composability: All pipes (extension methods) are composable and chain can be constructed with zero or more intermediary pipes as deemed required
- Readability: All pipes are quite declarative in nature and expose only optional parameters
- Maintainability: Pipes are build keeping single responcibility principle in mind
- Elasticity: New (ordinary and exotic) pipes can be easily created and can be made an integral part of the existing API
- Reusability: Reusability (in ordinary sense) is achieved through composition & recomposition of pipes. At the same time Reusability (in broad sense) is achieved by exploring the concept of Meta Pipeline.
Happy coding!

