Concurrency makes many promises to the multicore environment but it comes at the cost of some challenges. If it hadn’t been for concurrency, multicore would be no better than a single core. If faster execution of the program is the profound implication of concurrency then mind numbing debugging is subtle. The attempt to run multiple tasks at the same time can introduce many complications and difficulties that accompany the benefits.
This article is the continuation of Programming Concurrency in C++: Part 1 and assumes that you are now familiar with basic concepts of concurrency and multi-threading in C++.
Race Condition- Need for synchronization:
In a concurrent program, resources and data is shared among threads. Suppose that we want to increment a number and also output the result. If we’re solving the problem in multi-threaded environment then the results become un-deterministic and un-predictable. The following picture will make the idea clear.
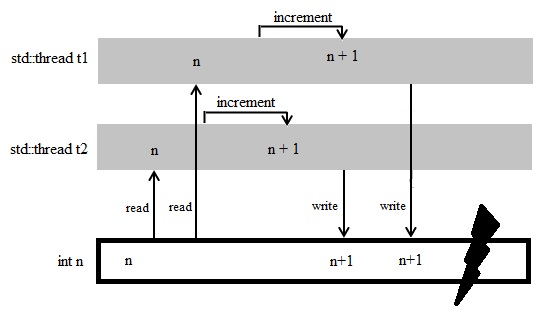
For the hands on type people, consider the following code.
class Race_condition
{
public:
int n;
Race_condition() :n(0) {}
void increment() {
++n;
}
};
Our class Race_condition implements the same scenario that we were talking about earlier. It contains a simple function that increments n. Let’s try calling this function in a multi-threaded environment.
int main()
{
Race_condition racer;
std::thread t1([&racer] {
for (int i = 0; i < 10000; ++i) {
racer.increment();
}
});
std::thread t2([&racer] {
for (int i = 0; i < 10000; ++i) {
racer.increment();
}
});
t1.join();
t2.join();
std::cout << racer.n << std::endl;
return 0;
}
We only created 2 threads to increment the counter racer 10000 times. You can try creating more threads as well. The idea here is to show you that you don’t need tens of threads to run into a problem. Try executing the above program a couple of times and you’ll get different results each time. These are some results I got on my system.
Well, the program is pretty good of a choice if you just want to generate random numbers but to get a predictable result, it surely is not. This is called race condition; an undesirable situation where output depends on the sequence or timing. The increment is not an atomic operation (atomic implies that processor can simultaneously read and write to the same memory location in the same bus operation. We’ll be looking into it in more details later in the article). Also the access to the integer is not synchronized. Threads are accessing it non-continuously. Because of simultaneous access to shared data many errors can appear; the both threads might interleave with each other and so the results become unpredictable. And this is a small and simple problem. Imagine the mess it would be in case of tens of threads manipulating huge data involving millions of calculations and computations.
Synchronization:
Let’s take a more thorough look into the above problem. The increment in the above example implies the execution of three operations:
- Read the current value of n
- Increment the current value of n by 1
- Write the new value of n
The sequence of above operations must be maintained as read, increment and write and repeat the same sequence as many times as we may want. But when we launch multiple threads, the sequence is disturbed as we don’t know which thread might be performing which of the above functions. Note that these operations are being performed over a single object n and the data that it holds is shared among all the 10 threads that we created. In order to avoid the race condition, we need a way to protect the shared data so that it must not be concurrently accessed by more than one thread of execution. Here are some proposed solutions to synchronization problem:
- Semaphores — The C++ standard does not define a semaphore type but offers the possibility that you can write your own. Though not necessarily needed because most uses of semaphores are better replaced with mutexes and/or condition variables.
- Mutex — C++ provides with
std::mutex class for synchronization and avoiding race conditions. A binary semaphore can also be used as mutex - Atomic references — C++ introduces atomic types as a template class
std::atomic - Monitors — guarantees one thread can be active within monitor at a time. C++ does not support monitor.
- Condition variables —
std::condition_variable class provides with the ability to synchronize between threads. - Compare-and-swap — It compares the contents of a memory location to a given value. If both values are same then it will modify the contents of that memory location with that of a new value.
Here we’ll only be exploring the most common solution to synchronization problem in C++ i.e. mutex, atomic types and condition variables.
Mutual Exclusion (mutex):
MUTual EXclusion refers to the idea of preventing simultaneous execution of critical section (a piece of code that accesses a shared resource) by multiple threads. C++ provides std::mutex class for synchronization that is used to protect shared data from concurrent access by more than one thread of execution. It works with locking and unlocking mechanism. Once a mutex is locked, the current executing thread will own the resource until it is unlocked; meaning that no other thread can execute any instructions until mutex unlocks the block of code surrounded by it. Let’s see how we can use the mutex to solve the synchronization problem in our previous example.
class Race_condition
{
public:
std::mutex mutex;
int n;
Race_condition() :n(0) {}
void increment() {
mutex.lock();
++n;
mutex.unlock();
}
};
You create a mutex by instantiating std::mutex, lock it with a call to the member function lock() and unlock it with a call to unlock(). mutex lock make sure that once one thread finishes the modification, only then another thread modifies the data. Now try executing the same above program and see if you get the same expected output each time or not. Here’s the output I got on my system.
If there’s some error exception, system_error is thrown while error codes could be as follow:
- resource_deadlock_would_occur
- resource_unavailable_try_again
- operation_not_permitted
- device_or_resource_busy
- invalid_argument
Let’s see how this works.
std::mutex mutex;
try {
mutex.lock() ;
mutex.lock() ;
}
catch (system_error & error) {
cerr << error.what() << endl;
cerr << error.code() << endl;
}
Here’s what I got on my system.
But is there anything more to mutexes? Yes! There are several mutex classes in the library. For example:
| std::mutex
| Provides basic locking
| | std::recursive_mutex
| Same thread can do the repeated locking without deadlock
| | std::timed_mutex
std::recursive_timed_mutex
| Provides timeout when trying to acquire the lock i.e. thread can do something else when waiting for a thread to finish.
| | std::shared_mutex
| Allows more than one thread to own the mutex
| | std::call_once(std::once_flag flag, function)
| std::call_once is matched to std::once_flag and function would be called only once no matter how many threads are launched.
|
|
| |
All good but what if we forgot to unlock the mutex at the end of the function? It won’t be so wise of us to call the member function directly because we have to remember to unlock() each and every code path (including exceptions) out of function or else we might run into an undesirable situation just like we run into exception while executing the above code. In such a situation, usually program end up calling abort.
Preferred locks to mutexes:
So is there a better option for us? Well, Yes! There are some preferred types of locks that C++ offers.
std::lock_guard implements Resource Acquisition Is Initialization (RAII describes the concept that resource will be held only for object life-time. Follow the link to know more about this programming idiom) for a mutex. It is usually called mutex wrapper that provides the RAII style mechanism meaning the mutex will be owned for the duration of the scoped block. When std::lock_guard is instantiated, it attempts to take the ownership of the mutex it is given (think of it as lock() is called on mutex). The destructor of lock_guard will be called releasing the mutex as soon as the lock_guard object goes out of scope (just as unlock() is called). Let’s use the code problem our previous example but this time implementing lock_guard.
class Race_condition
{
public:
std::mutex mutex;
int n;
Race_condition() :n(0) {}
void increment() {
std::lock_guard<std::mutex> lock(mutex);
++n;
}
};
We pass a mutex to the constructor of std::lock_guard<> to acquire the lock and mutex will be unlocked in the destructor removing the need to call unlock() explicitly. Make the above amendments in your code and execute the previous program.
std::unique_lock offers more functionality and power than std::lock_guard. unique_lock is an object that manages mutex object with unique ownership in both locked and unlocked states. It does not need to own the lock on the mutex it is associated with and also allows you to transfer lock ownership between instances. (We’ll be exploring this flexibility of unique_lock later in the article when talking about deadlock-avoidance. For now just stick with me). At the very least it can be used just like std::lock_guard to simplify the locking and unlocking of a mutex and provide exception safety. Observe the syntax below.
{
std::mutex mutex;
std::unique_lock<std::mutex> lock(mutex);
}
But it has more to it than just locking and unlocking mutex. Let’s see what more functionality it offers.
| unique_lock::try_lock
| Lock mutex if not already locked
|
| unique_lock::try_lock_for
| Try to lock the mutex during specified time span
|
| unique_lock::try_lock_until
| Try to lock the mutex until specified point of time
|
| unique_lock::operator=
| Move-assign unique_lock
|
| unique_lock::swap
| Swap unique locks
|
| unique_lock::release
| Release mutex
|
| unique_lock::owns_lock
| Owns the lock
|
| unique_lock::operator bool
| Returns true if it owns a lock or false otherwise
|
| unique_lock::mutex
| Gets mutex
|
I yet don’t want to dig deep implementing each one of the above because that’s beyond the scope of this article. I would leave it onto you for now to explore and experiment around.
Deadlocks:
Usage of mutexes seems a piece of cake as for now because they ensure that code in critical section can only be accessed by a single thread at any time. locking and unlocking mechanism provides exclusivity but the cat is still in the bag. Let’s write a simple program to unleash the devil.
void print() {
std::cout << "Critical Data" << std::endl;
}
int main() {
std::mutex mutex1, mutex2;
std::thread t1([&mutex1, &mutex2] {
std::cout << "Acquiring First mutex..." << std::endl;
mutex1.lock();
print();
std::cout << "Acquiring second mutex..." << std::endl;
mutex2.lock();
print();
mutex1.unlock();
mutex2.unlock();
});
std::thread t2([&mutex1, &mutex2] {
std::cout << "Acquiring second mutex..." << std::endl;
mutex2.lock();
print();
std::cout << "Acquiring First mutex..." << std::endl;
mutex1.lock();
print();
mutex2.unlock();
mutex1.unlock();
});
t1.join();
t2.join();
return 0;
}
In the above code, we’re passing our mutex objects mutex1 and mutex2 as argument to the thread t1 and t2. It can also be seen that we’re acquiring multiple locks.
Execute the above program and see what happens. Here’s the output I got.

Note: Your output could be different. That’s for the reason that there’s no strict sequence of execution in multi-threaded environment. There’s also a possibility that your program might run successfully and does not end up in deadlock condition (I'll explain the reason later). No there’s nothing wrong with the code. Run your program a few times and you’ll observe the deadlock.
The program just sits there and nothing happens afterwards. Such situation is known as deadlock (A state in which one process is holding onto a resource and waiting for some other resource acquired by some other process and thus both processes ends up waiting for each other to do something endlessly). Such situation can make you pull your hair when you don’t know what’s happening behind the curtain. I, myself got stuck in a deadlock situation for hours trying to figure out what was wrong and how to solve the problem at first. But let me make it easy for you. Here’s what happens.
Our threads t1 and t2 have access to both mutex locks. Thread t1 attempts to acquire the locks in the order mutex1.lock() and mutex2.lock() while thread t2 attempts for mutex2.lock() and mutex1.lock(). Deadlock is possible if thread t1 acquires mutex mutex1 while thread t2 acquires mutex mutex2. Now t1 would wait for mutex mutex2 while t2 will wait for mutex mutex1. Both mutexes will wait for each other to free the resource and thus leading to deadlock condition.
It happened that I executed the program at once and it ran just fine. No deadlocks. That’s for the reason that even though deadlock is possible, it will not occur if thread t1 acquire and release the mutex locks for mutex1 and mutex2 before thread t2 attempts to acquire the locks. And, of course, the order in which the threads run depends on how they are scheduled by the CPU scheduler.
Last but not the least thing to mention here; is that the above code represents the bad code example. Never ever try to acquire a lock while holding onto another lock as it will most certainly lead to deadlock. Avoid nested locks and such code at all cost. It was just intended to make the idea clear by exemplifying it.
Avoiding Deadlocks:
Deadlocks are the nightmare and care must be taken to avoid them at all cost. One of the most common ways of avoiding a deadlock is to lock away the mutexes in the same order. mutex1 is always locked before mutex2 and we’ll not face the deadlock anymore. Well, in our example, it is pretty straightforward and deadlock can be avoided by applying this simple rule. See here
void print() {
std::cout << "Critical Data" << std::endl;
}
int main() {
std::mutex mutex1, mutex2;
std::thread t1([&mutex1, &mutex2] {
std::cout << "Acquiring First mutex..." << std::endl;
mutex1.lock();
print();
std::cout << "Acquiring second mutex..." << std::endl;
mutex2.lock();
print();
mutex1.unlock();
mutex2.unlock();
});
std::thread t2([&mutex1, &mutex2] {
std::cout << "Acquiring First mutex..." << std::endl;
mutex1.lock();
print();
std::cout << "Acquiring Second mutex..." << std::endl;
mutex2.lock();
print();
mutex1.unlock();
mutex2.unlock();
});
t1.join();
t2.join();
std::cout << "Program ran succesfully" << std::endl;
return 0;
}
And now our program will not run into deadlock anymore. Here’s the output.
But not in all cases it’s that simple such as when the mutexes are protecting some separate instance of the same class. In such situation, it is often necessary to apply some extra C++ provided functionality.
There are two common patterns that are used to avoid deadlocks.
- Lock mutexes at the same time and then create the guard afterwards
- Create the guards and then lock mutexes at the same time
The code for both patterns is virtually equivalent and can be replaced with one another. Here’s how it works.
{
std::lock(mutex1, mutex2);
std::lock_guard<std::mutex> lock1(mutex1, std::adopt_lock);
std::lock_guard<std::mutex> lock2(mutex2, std::adopt_lock);
}
Here we acquire the locks first (avoiding deadlocks) and then created guards to release them properly. std::lock() uses deadlock-avoidance algorithm and locks all the objects passed as arguments. std::adopt_lock() is used as possible argument to the constructor of lock_guard (can be used with unique_lock as well). It assumes that calling thread already owns the lock which is pretty much true because we just locked them. Now std::adopt wrapper will adopt the ownership of the mutex and release it as soon as the control goes out of scope.
Here’s the other way to achieve the same functionality.
{
std::unique_lock<std::mutex> lock1 (mutex1, std::defer_lock);
std::unique_lock<std::mutex> lock2 (mutex2, std::defer_lock);
std::lock(lock1, lock2);
}
Here we first create the lock (without acquiring them) and then acquire them simultaneously using std::lock without the risk of a deadlock. std::defer_lock does not acquire the ownership of the mutex rather assumes that lock will be called later by the calling thread to acquire the mutex. Again wrapper will release the lock as soon as the control goes out of scope.
Here’s one thing to note is that you’re not supposed to pass two successive calls to std::lock to acquire the mutexes individually or you’ll again run into deadlock situation.
{
std::unique_lock<std::mutex> lock1 (mutex1, std::defer_lock);
std::unique_lock<std::mutex> lock2 (mutex2, std::defer_lock);
std::lock(lock1);
std::lock(lock2); }
C++ 17 added std::scoped_lock which is also a mutex wrapper providing RAII mechanism for owning one or more mutexes for as long as the scoped block is active. It locks arbitrary number of mutexes all at once using the same deadlock-avoidance algorithm as std::lock. When a scoped_lock object is created; it will try to take the ownership of given mutexes. The object will be destructed as soon as the control leaves the scope in which scope_lock object was created and mutexes will be released in reverse order. Thus, it solves the deadlock problem more elegantly. Observe the syntax.
{
std::scoped_lock<std::mutex, std::mutex> lock(mutex1, mutex2);
}
Synchronization between threads:
It’s just not the shared data that needs to be protected but we also need to synchronize the actions between separate threads. A thread might need to wait for an event to occur or a task to be completed by another thread. For example, a thread notifying another thread that it has finished reading data and the other thread can now process the data further. So a wait/notify mechanism is required to synchronize threads when accessing shared resources. This is more efficient that other methods like poling. C++ Standard Library provides conditional variables to handle such problem.
std::condition_variable class is a synchronization primitive used to block the calling thread until notified to resume. Here are some functions that this class provides.
| condition_variable::wait()
| Wait on a mutex until notified
|
| condition_variable::wait_for()
| Wait for timeout or until notified
|
| condition_variable::wait_until()
| Wait until specified point of time or notified
|
| condition_variable::notify_one
| Awakens a waiting thread
|
| condition_variable::notify_all
| Awakens all waiting threads
|
Let’s implement a simple sender/receiver scenario and see how it works.
std::mutex mutex;
std::condition_variable cv;
bool ready = false;
void print()
{
std::cout << "Waiting for other thread to signal ready!" << std::endl;
std::unique_lock<std::mutex> lock(mutex);
while (!ready)
{
cv.wait(lock);
}
std::cout << "thread is executing now...." << std::endl;
}
void execute()
{
std::cout << "Thready is ready to be executed!" << std::endl;
ready = true;
cv.notify_all();
}
int main()
{
std::thread t1(print);
std::thread t2(print);
std::thread t3(execute);
t1.join();
t2.join();
t3.join();
return 0;
}
Observe that any thread that has to wait on std::condition_variable,needs to acquire a std::unique_lock first. The wait operation will release the mutex atomically (That’s where we use the flexibility provided by unique_lock that waiting thread will release the mutex while waiting) and suspend the execution of the thread. After the condition variable is notified, the thread will be awakened, and the mutex is reacquired.
The flexibility to unlock std::unique_lock can also be used when we are to process data (but before processing it) as data processing can be time-consuming and it’s not a good idea to keep the mutex locked for longer than necessary.
Data Race and Atomics:
I said that increment is not an atomic operation while talking about race-condition but left the statement there to be dig into later. Now is the time that we talk about what are atomic operations and atomics.
An operation is said to be atomic during which a processor can simultaneously read a location and write it, in the same bus operation. Atomic implies indivisibility and irreducibility, meaning they cannot be divided into sub-tasks so an atomic operation must be performed entirely or not performed at all. Thus, it is guaranteed to be executed as a single transaction which means that other threads will see the state of the system before the operation started or after it has finished, but cannot see any intermediate state.
Here, let me take you back to our increment example and explain what I mean. As we’ve talked about earlier, increment is Read-modify-write operation (clearly non-atomic). Here’s what was happening behind the scene when we executed the increment function (without locks).
int n = 0;
Thread 1 — t1:
int tmp = n;
++tmp;
n = tmp;
Thread 2 — t2:
int tmp = n;
++tmp;
n = tmp;
If there is no enforced ordering between two accesses to a single memory location from separate threads, one or both of those accesses is not atomic, and one or both is a write, this is a data race.
(Don’t curse me already for calling it a race condition earlier. Actually it is both. Many race conditions are in fact caused by data races. Think of data race as cause and race condition as effect. Race condition occurs when the timing or ordering of events affects the correctness of program which can also be caused by context switching, memory operations on a multi-processor (here comes the data race) or hardware interrupt. We’ve already talked about how to fix the race condition. Here, I want to talk about how to fix a data race.)
Data race happens when a program involves two or more operations that are performed concurrently by multiple threads, targeting the same location and are not synchronized. Note here that if we make our program thread safe (introducing synchronization between threads), then data race could be avoided and thus resolves the race condition caused by it. (Like what we did previously with locks) But if we’re to adjust a simple value like increment or decrement a counter then there’s more simple and efficient approach available. C++11 concurrency library introduces atomic types as a template class: std::atomic. These types avoid undefined behavior and provide an ordering of operations between threads. Operations are performed automatically on the variable and can be called variable synchronization.
You can use any type you want with the template and the operation on that variable will be atomic and so thread-safe.
std::atomic<Type> object
Let’s try to implement our increment function using atomics.
class Atomic_counter
{
public:
std::atomic<int> n;
Atomic_counter () :n(0) {}
void increment() {
++n;
}
};
int main()
{
Atomic_counter counter;
std::thread t1([&counter] {
for (int i = 0; i < 10000; ++i) {
counter.increment();
}
});
std::thread t2([&counter] {
for (int i = 0; i < 10000; ++i) {
counter.increment();
}
});
t1.join();
t2.join();
std::cout << counter.n << std::endl;
return 0;
}
Now observe the output from above program.
This clearly depicts that we’ve fixed the data race for the reason that ++n is now atomic in behavior. You might have noticed that the above code is lock free and thus more efficient. Well, that’s what all the fuss for atomics is about. Locks (and mutex) actually suspend thread execution and tend to free up resources for other tasks but at the obvious cost of context-switching overheard (stopping and restarting threads incurs some computational cost) while threads don’t wait in atomic operations rather attempts busy-waiting (try attempting to do operation unless and until success) and it is only the duration of the actual operation which is locked out. So they don't incur in context-switching overhead neither free up CPU resources which makes them more efficient. Also they do not suffer from deadlocks.
But it’s not always lock-free. Different locking technique is applied according to the data type and size. Integral types like int, long, float implies lock-free technique which is faster and more efficient than mutex. For big type, the variable cannot be modified during a single tick, so the compiler will insert thread guards before and after the variable which would not imply any performance advantage over mutex.
So what types can be made atomic? Broadly speaking, any trivially copy-able type (No virtual functions, noexcept constructor) can be made atomic.
std::atomic<T>
where T represents all the types e.g.
std::atomic<int> n;
std::atomic<double> d;
struct S {long a; long b;};
std::atomic<S> s;
Other operations:
All atomic operations can be performed on atomic variables such as read, write, special atomic variables or certain type dependent operations. We have already seen the pre-increment; here are some more operations that can be performed.
- Assignment and copy (read and write) for all types; Built-in as well as user-defined
- Increment and decrement for raw pointers
- Addition, subtraction, and bitwise logic operations for integers (++, +=, –, -=, |=, &=, ^=)
std::atomic<bool> is valid, no special operationsstd::atomic<double> is valid, no special operations- Explicit reads and writes:
std::atomic<T> a;
T b = a.load(); a.store(b);
T c = a.exchange(b);
- For integer T, there are various other RMW (Read-modify-write) operations available like
fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor()
std::atomic<int> a;
a.fetch_add(b);
Compare and Swap:
Compare-and-swap (CAS) is used in most lock-free algorithms. Out of all the available RMW operations in C++, compare and swap is absolutely essential. For example:
bool success = a.compare_exchange_strong(b, c);
The important thing about CAS is that the atomic increment only works for int and even in that case, atomic multiplication is not a legal operation.
n *= 2; // No atomic multiplication!
But CAS can be used in such situations. E.g. you can use CAS to implement integer increment, increment doubles, integer multiplication etc.
Here’s how you can do integer increment.
std::atomic<int> x{0};
int n = x;
while ( !x.compare_exchange_strong(n, n+1) ) {}
What about integer multiplication?
while ( !n.compare_exchange_strong(n, n*2) ) {}
There’s also other CAS operations available e.g.
- atomic_compare_exchange_weak,
- atomic_compare_exchange_weak_explicit,
- atomic_compare_exchange_strong_explicit
You can read more about them here.
Threads vs. Tasks:
So far we’ve been talking about low-level management of threads referred to as thread-based parallelism (one might argue whether it is concurrency or parallelism but that debate is beyond the scope of this article). You create threads, launch them, “join” them, etc. Although they are OS abstraction but you’re closest to the hardware at this point. When working with threads, we better know the number of threads we need, how many of them have been running at a particular time and how to balance the load between them or things would get messy in no time.
But that’s not how we do things nowadays. Dealing with machine at such lower level is tedious and error prone. There’s a higher level of abstraction referred to as task-based parallelism where you get to manage the “tasks”. You define the whole chunk of work and then library (or API) manages the threads. It is made sure that there are not too few or too many threads also work load is balanced reasonably among the threads without your intervention. Of course you’re going to have much less control over the low-level system but it is safer and more convenient. Also here are some performance advantages discussed of using Task-Based Parallelism. Though this is rather a detailed discussion and in my humble opinion, performance depends more on the kind of task being performed.
C++ standard library does provide some facilities to allow programming at conceptually task level. Here are some options for you.
future and promisepackaged_taskasync
std::future and std::promise
std::future and std::promise are class templates that are used to return value from a task that might be spawned on a separate thread. They make it easy to transfer the value between threads/tasks without having to use lock explicitly. The idea behind is to promise the value that is to be passed and corresponding future can read it. This graphical illustration will make the idea clear.
std::promise facilitates with a means of setting a value that will be read later through an associated std::future which means that std::future acts as a proxy for the value that will become available. std::future will throw exception if std::promise object is already destroyed before setting the value. Each future and promise holds a pointer to the shared value. These pointers are movable. Let’s write a simple program to see how we can use them.
void func(std::promise<int> * p)
{
int a = 10, b = 5;
int result = a + b;
std::cout << "From inside the Thread...." << std::endl; p->set_value(result);
}
int main()
{
std::promise<int> p;
std::future<int> f = p.get_future();
std::thread th(func, &p);
std::cout << f.get() << std::endl;
th.join();
return 0;
}
We created promise and corresponding future objects in the above program. std::promise allows you to explicitly set the value as we did in p->set_value(result) which is later fetched by the future object. In case we want multiple return values at different point of time then all we need is to pass multiple promise objects in thread and fetch multiple return values from their corresponding future objects.
std::packaged_task
In case of std::promise and std::future, the value should be set in promise object before the thread function could return it in the associated future in main thread or else future will get blocked until the value is available. One more thing to note is that if promise object is destroyed before returning the value, then the result would be an exception. C++ provides std::packaged_task to help with above mentioned scenario. It is a class template wrapper that implies a normal function to run as asynchronous. The constructor of the std::packaged_task takes a function as an argument and creates a packaged_task object (associated callback and returned value or exception stored in its internal shared state). The returned value can be accessed in another thread or main function through the associated future object. One more thing to mention here is that std::packaged_task is for manual task invocation and is mostly used in case of thread pools.
int func()
{
int a = 10, b = 5;
std::cout << "From inside the Thread...." << std::endl;
return a+b;
}
int main()
{
std::packaged_task<int()> p(func);
std::future<int> f = p.get_future();
std::thread th(std::move(p));
std::cout << f.get() << std::endl;
th.join();
return 0;
}
The best thing about packaged_task for me is no pointers. I hope we all can agree that pointers sucks or at least I’m still bad with them so that’s a relief. Also since it’s a wrapper, so any callable could be used i.e. function, functor (function object) or lambda. Feel free to experiment using other methods.
std::async
std::async is a high-level abstracting over promises to accomplish asynchronous execution of tasks. It is a function template that’ll take a callable (function, function object or lambda) as an argument and execute it asynchronously. Consider the below code.
int func()
{
int a = 10, b = 5;
std::cout << "From inside the Thread...." << std::endl;
return a+b;
}
int main()
{
std::future<int> f = std::async(func);
std::cout << f.get() << std::endl;
return 0;
}
Note that std::async eliminated the part of manual thread creation. std::async will automatically create the thread (or will pick up a thread from internal thread pool) and a promise object for us. This std::promise object is then passed to thread function and associated std::future object is returned. The value in promise object is set at the exit of passed argument function and eventually will be returned in corresponding std::future object.
std::async behaves as a task scheduler and the behavior can also be configured with an argument. Observe the following code.
int func(int)
{
return 0;
}
int main()
{
auto f = std::async(func, 1);
int result1 = f.get();
int result2 = func(2);
return 0;
}
Our function will be launched asynchronously using std::async. This is same like as we are executing the function in a new thread (or at least tries to execute it asynchronously in a new thread). Our main continues its execution with function call func(2) once the future object associated with func (being executed by std::async) is returned and stored in f. Another thing to observe about above code that you can easily pass parameters to async interface just as we did std::async(func, 1).
Usually, we need to launch more than one asynchronous call. Now to get each returned future we would have to give them separate names, which is painful not to forget error prone. One way to do so is to use vectors to store futures.
std::vector<std::future<int>> f;
Let’s make things a little more interesting here by using lambda. Let’s write a simple program.
int main() {
std::vector<std::future<int>> f;
for (int i = 0; i < 5; ++i)
{
f.push_back (std::async( [] (int x) {return x*x;}, i));
}
for (auto &result: f) {
std::cout << result.get() << std::endl;
}
return 0;
}
Passing parameters:
We have already seen that std::async allows us to pass parameters. Let’s see if it allows us to pass parameters with reference.
std::string copy_func(std::string const &s) {
return s;
}
int main() {
std::string s = "some string";
auto f = std::async(copy_func, std::ref(s));
std::cout << f.get() << std::endl;
return 0;
}
The same way you can pass parameters using lambda as well.
auto f = std::async([&s]() {return copy_func(s); });
But what about passing exceptions? Does std::async allows that? Let’s see.
int func(){
throw std::runtime_error("An error has occured");
}
int main() {
auto f = std::async(func);
try {
std::cout << "From main..." << f.get() << std::endl;
}
catch (std::runtime_error const& error) {
std::cout << "Caught Exception: " << error.what() << std::endl;
}
}
You see passing exception is as easy as passing parameters. You can directly pass the parameters through std::async interface just as we did in previous examples which make a programmer’s live easy and you won’t have to jump out of the window.
Difference between promise, packaged task and async:
We have seen three ways to associate a task with future so far i.e. promise, packaged_task and async. Let me highlight again what is the difference between them and why any would be preferred over others.
promise allows you to communicate the value to the corresponding future at some different time and does not restrict the return value to the end of a function call. Also manual thread invocation gives you better control at lower level.
packaged_task separates the creation of the future from the execution of the task which allows us to invoke task manually and is most useful when dealing with thread pools.
async is the higher level abstraction over promises and future and saves us the headache of manual task or thread invocation. It deals with the lower level details like thread creation, number of threads and load balancing between them.
Concurrency != Parallelism:
We’ve been talking about how std::async helps us write more concise, smaller and readable threaded programs as compared to std::thread. This sure saves us from reinventing the wheel and dealing with low level constructs but does async enable real task based parallelism? Unfortunately NO!
To understand this let’s talk about launch policies. By defult, std::async decides at run time whether it will execute the task concurrently or will wait until the results are requested. These behaviors can be configured by using the launch flag as first argument.
auto f = std::async( std::launch::async,
auto f = std::async( std::launch::deferred,
Concurrent execution is requested by using std::launch::async. To request that the task is executed only when the result is needed, std::launch::deferred is used.
| std::launch::async
| “as if” in a new thread
|
| std::launch::deferred
| On demand execution
|
| std::launch::async | std::launch::deferred
| Default (runtime chooses)
|
std::launch::async is greedy and would invoke a new thread right away but deferred is much different than async in many ways. If we’re launching the async with deferred policy it means that the future won’t actually run the task but only get() will. This means if we’re waiting onto the task then we’ll be stuck in an infinite loop until get() is called. The reason I’ve been using the default is that async will try to invoke a new thread to accomplish the task concurrently whenever it can or else will wait. This is a good idea when you’re dealing with simpler tasks.
What’s next?
This article was also just meant for the introductory purposes and is solely based on my understanding. Let me also acknowledge here the CppCon which really helped me understand the concurrency concept. There’s much more to discover but is beyond the scope of this article. If you want to dig deeper into concurrency then I would recommend you C++ Concurrency in Action by Anthony A. Williams. Feel free to work around and leave any suggestions if you have for me.

