Contents
For the Azure Function contest, I thought it would be interesting to stress test the free Azure Compute Function App capabilities, and since we just had Pi day, and Emma Haruka Iwao, a Google employee, calculated 31,415,926,535,897 digits of pi (that's more than 31 trillion digits), setting a world record (new article here), what better way to stress test Azure Function! While I'm not trying to break any world records, it was instructive, not just for the stress testing, to dabble a little bit with how Azure Function works and is integrated with Visual Studio.
If you haven't read the Code Project competition articles, I recommend you do so to familiarize yourself with them first.
And couple others from Microsoft:
I used the Azure Function HTTP trigger which is one of the many "serverless" function triggers you can create with Azure. Serverless is a misnomer -- obviously, the code runs on a server somewhere -- but the point is that you are only charged for the actual CPU time required to execute the function. This differs from typical cloud-based servers, where you are usually charged for the server instance, disk space, memory, and idle time CPU usage. In other words, you can think of "serverless" is up and running only when it's doing something.
- As an HTTP trigger, the function should "compute" something quickly, otherwise the browser or REST call will time out.
- If you have a long running function, you'll need some other way of reporting the result of the function, which is what I had to implement.
- Frankly, I was disappointed that there wasn't some way to obtain the status of the function (is it still doing work, is it done?) and obtain the result when done. This could be implemented in a variety of ways:
- Polling (not the preferred way)
- Callback notification
- Websocket notification
- Notification could include the result or there could be a separate call to obtain the result.
- Stop/restart is at the granularity of the entire function application, not an individual function. While that makes sense, it would be really useful to be able to kill a specific function execution.
As it stands, the HTTP Trigger is just an API call. I would have liked to have seen something that added a bit more "intelligence" that the client could leverage with regards to point #3 above.
The serverless approach does have its cost savings and simplicity. It is very easy to write a serverless function in Visual Studio, test it locally and publish it to Azure. The complexity of standing up a virtual server, opening ports, setting up the HTTP listener, and publishing updates is effectively eliminated. I find that this makes serverless computing compelling, but given that I would normally stand up a "server-ful" instance (database, email, etc. support), I'm still not convinced that there is much benefit to this approach. However, having gone through this exercise, it is another tool to add to the toolbox of what is the best fit for the requirements.
I used the Spigot Algorithm adopted from this amazing website: https://rosettacode.org/wiki/Pi#C.23. The implementation involves two pieces of code:
- The Azure Function
- The client-side listener for the digits and computation time
And setup involves:
- Creating (if you haven't) an Azure Free account
- Creating Function App
- Opening port 31415 (how appropriate!) on your router to receive output from the Azure function
This assumes you've already created an Azure free account and created a Compute Function App. Do not actually create a function -- we'll be doing that in Visual Studio. Functions created in Visual Studio are read only and display this message when you click on them on the Azure website:

In Visual Studio, create an Azure Function project by selecting Cloud and Azure Functions. According to Microsoft: "These tools are available as part of the Azure development workload in Visual Studio 2017." I didn't have to do anything special -- as the documentation indicates, the development workload was just there.
I called my function "AzureFunctionComputePi" and put it in my usual folder, "c:\projects":
Each function (we have only one, but for general information) require their own class with a Run method, for example:
public static class ComputePi
{
[FunctionName("ComputePi")]
public static async Task<HttpResponseMessage> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)]
HttpRequestMessage req, TraceWriter log)
{
...
}
}
For our purposes, I want to pass in the number of digits to compute and the "chunk size" -- the number of digits to report in each callback to the PiListener (described in the next section):
var response = new HttpResponseMessage(HttpStatusCode.OK);
dynamic data = await req.Content.ReadAsAsync<object>();
string html = "<html>Sending digits...</html>";
var parms = req.GetQueryNameValuePairs();
string strMaxDigits = parms
.FirstOrDefault(q => string.Compare(q.Key, "maxDigits", true) == 0)
.Value;
string strChunkSize = parms
.FirstOrDefault(q => string.Compare(q.Key, "chunkSize", true) == 0)
.Value;
if (String.IsNullOrEmpty(strMaxDigits) || String.IsNullOrEmpty(strChunkSize))
{
html = "<html>Please provide both maxDigits and chunkSize as parameters</html>";
}
... see below ...
response.Content = new StringContent(html);
response.Content.Headers.ContentType = new MediaTypeHeaderValue("text/html");
return response;
The "else" (parameters were found) in the "..." does the rest of the work:
else
{
try
{
int maxDigits = Convert.ToInt32(strMaxDigits);
int chunkSize = Convert.ToInt32(strChunkSize);
var ret = Task.Run(() => CalcPiDigits(maxDigits, chunkSize));
}
catch (Exception ex)
{
html = $"<html>{ex.Message}</html>";
}
}
Notice something interesting here -- We can exit the function with a response (hopefully a happy response) while the function continues its computation in a task:
I was actually surprised by this, as somehow I expected that whatever is executing the function on Azure would terminate the process once it exited, or at least kept the instance cached but otherwise terminate it.
Why run the computation as a task? Because this is an HTTP trigger function, it is invoked from a browser or REST call. As such, it can take considerable time to complete. If we don't run it as a task, Chrome at least ends up displaying one of several timeout messages, such as:
I also found the Stop and Restart useful and function application dashboard:
Particularly when I wanted to kill the function application during long running tests. This is not instantaneous -- I still received several callback posts -- and it does stop the entire function application -- there does not appear to be a way to stop and restart a specific function.
As mentioned previously, I adopted the code from https://rosettacode.org/wiki/Pi#C.23. The only tweak that I made was the POST the digits at "chunk size" intervals and to measure the computation time per chunk. Kudos to the people who wrote this:
private static void CalcPiDigits(long maxDigits, int chunkSize)
{
BigInteger FOUR = new BigInteger(4);
BigInteger SEVEN = new BigInteger(7);
BigInteger TEN = new BigInteger(10);
BigInteger THREE = new BigInteger(3);
BigInteger TWO = new BigInteger(2);
BigInteger k = BigInteger.One;
BigInteger l = new BigInteger(3);
BigInteger n = new BigInteger(3);
BigInteger q = BigInteger.One;
BigInteger r = BigInteger.Zero;
BigInteger t = BigInteger.One;
string digits = "";
int digitCount = 0;
BigInteger nn, nr;
Stopwatch sw = new Stopwatch();
sw.Start();
while (digitCount < maxDigits)
{
if ((FOUR * q + r - t).CompareTo(n * t) == -1)
{
digits += n.ToString();
if (digits.Length == chunkSize)
{
sw.Stop();
Post("digits", new { computeTime = sw.ElapsedMilliseconds, digits });
digitCount += digits.Length;
digits = "";
sw.Restart();
}
nr = TEN * (r - (n * t));
n = TEN * (THREE * q + r) / t - (TEN * n);
q *= TEN;
r = nr;
}
else
{
nr = (TWO * q + r) * l;
nn = (q * (SEVEN * k) + TWO + r * l) / (t * l);
q *= k;
t *= l;
l += TWO;
k += BigInteger.One;
n = nn;
r = nr;
}
}
}
Azure functions can utilize third party libraries quite easily when they are a NuGet package, which RestSharp fortunately is. POSTing is simple:
private static void Post(string api, object json)
{
RestClient client = new RestClient($"{PublicIP}:{Port}/{api}");
RestRequest request = new RestRequest();
request.AddJsonBody(json);
var resp = client.Post(request);
var content = resp.Content;
}
Otherwise, you have to use Kudu, which seems like something complex and too avoid, haha. Read more here.
I saw no reason to keep the client connection around, so instead I just create a new one for each POST.
The listener is straight forward, I'm not going to describe the details of my little WebListener and related classes, it's all straight forward. The important thing is that this logs a run to a file so I can import it into Excel and generate cute graphs.
using System;
using System.Diagnostics;
using System.IO;
using Clifton;
namespace PiListener
{
public class TheDigits : IRequestData
{
public long ComputeTime { get; set; }
public string Digits { get; set; }
}
static class Program
{
static Stopwatch sw = new Stopwatch();
static long numDigits = 0;
static string fn;
const string ip = "192.168.0.9";
[STAThread]
static void Main()
{
var router = new Router();
router.AddRoute("GET", "/test", Test);
router.AddRoute<TheDigits>("POST", "/digits", GotDigits);
var webListener = new WebListener(ip, 80, router);
fn = DateTime.Now.ToString("MM-dd-yyy-HH-mm-ss") + ".log";
webListener.Start();
sw.Start();
Console.WriteLine("Waiting for digits...");
Console.ReadLine();
webListener.Stop();
}
static IRouteResponse GotDigits(TheDigits digits)
{
sw.Stop();
numDigits += digits.Digits.Length;
Console.WriteLine(digits.Digits);
Console.WriteLine($"Total digits: {numDigits}");
Console.WriteLine($"Time = {sw.ElapsedMilliseconds} ms");
Console.WriteLine($"Compute Time = {digits.ComputeTime} ms");
File.AppendAllText(fn, $"{numDigits},{sw.ElapsedMilliseconds},{digits.ComputeTime}\r\n");
sw.Restart();
return RouteResponse.OK();
}
static IRouteResponse Test()
{
return RouteResponse.OK("Test OK");
}
}
}
Configure the PublicIP in the AzureFunctionComputePi project, ComputePi.cs, to your local IP address:
public const string PublicIP = "http://192.168.0.9";
public const int Port = 80;
In the PiListener project, configuring the ip variable again to your local IP address:
const string ip = "192.168.0.9";
Then:
- Start the
PiListener application as administrator - Run the function in Visual Studio
- Navigate to this URL (the port number may be different for your instance depending on what Visual Studio does):
http:
You should see the following output:
Now it's time to test the function on the Azure cloud! Change the IP address to your public IP address (Google "what is my IP" is one way to figure this out) and change the port number to 31415:
public const string PublicIP = "http://[your public IP]";
public const int Port = 31415;
In your router, forward this port to the local IP and port 80 where the PiListener is running. For example, on my router:
Oddly, I was not able to receive packets when I forwarded to an IP on my wireless network -- I had to forward to a computer on a wired connection.
Assuming you are on a wired computer, the PiListener code doesn't need to change.
To verify the routing is working correctly, you can use the test route:
with your public IP in the blacked out area. Remember the :31415 port number!
Once you've established that the PiListener is receiving the test response (and therefore your router is port forwarding correctly), publish the function by right-clicking on the project and selecting Publish:
Assuming that you've created an Azure account, you can select an existing account and publish to the Compute Function:
Copy the site URL in the publish UI:
Then navigate in the browser to your Azure function, for example:
http:
You should see something like this:
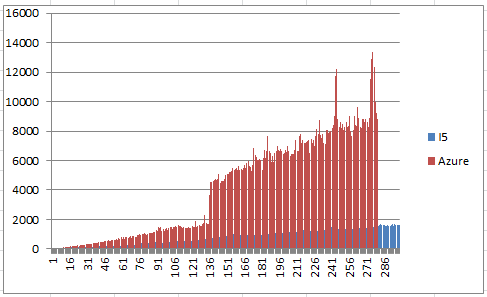
"Time" is the time between receiving POSTs at the client, and "Compute Time" is the time reported to compute the chunk.
If we do something more CPU intensive (3000 digits in 100 digit chunks), we see the Compute Time registering something other than zero:
The vertical axis is computation time in milliseconds, the horizontal axis the number of digits computed, in hundreds -- my input parameters where maxDigits=30000?chunkSize=100.
The blue lines bars are the computation time running the function on my localhost i5-7200U, 8GB, 2.5Ghz laptop, the red bars are the computation time running on Azure.
There are two things of note:
- There is a large increase in computation time around 13,600 digits.
- Running on Azure, the function failed to complete to 30,000 digits.
The fact that it's slower and didn't complete doesn't surprise me. After all, I'm using the free Azure account, and at some point, I imagine the resources required to hold the BigInteger values (they get very very large) exceed whatever memory is allocated to the VM running the function, or some function monitoring process says enough is enough!
I'm impressed with the ease of setup and integration with Visual Studio. Azure Compute Function applications are a useful addition to the toolbox of "cloud computing." Personally, I think more needs to be done though (and this is true also of my brief look at Amazon's Lambda offering) particularly with regards to long running processes. Maybe I'm missing something, but it strikes me that serverless functions, being trigger oriented, are most useful when called from an existing server, particularly if the computation is long running and needs some "client" (as in another server) to post back the results. I can see this as useful though for simple computations that require interfacing with other services (weather, stock market, new feeds, etc.) and even returning a complete web page in the response.
What serverless computing brings to the table is not so much a solution as a question: how do you balance serverless offerings with physical and/or virtual machine configurations (processing power, disk space, RAM) with computing requirements while at the same time dealing with the cost of auto-scaling vs. manual scaling, hardware maintenance (if you have physical hardware) and the difference in setup time/cost, hardware / VM upgrades, and publishing software updates? This requires a case-by-case analysis.
Serverless functions are inherently state-less unless you integrate them with, say, a database (serverless or not) so other questions come in to play as well, such as caching data. Do I want to fetch a weather report from Accuweather for every one of the thousands of people that might request the weather for Albany NY within, say, a 30 minute window? That costs me money to hit Accuweather for each of those requests. Wouldn't it make more sense to cache the results within a window of time? This falls more under the traditional server concept rather than a stateless compute function. Once you bring stateless functions and stateless databases (and other services, such as authentication and authorization) into the equation, the setup and maintenance costs begin to approach that of standing up a traditional server.
Speaking of authentication and authorization, I also don't think serverless computing does much, if anything, to improve the security of your application. Unfortunately, I cannot help but think that these serverless solutions will offer a whole new trove of hacking which can become quite expensive for the business that is running these things and doesn't understand the vulnerability of these endpoints and that they do not go through the typical layers of authentication and authorization that they would go through with a traditional server. Given that this post on security for Azure functions was made in November 2018 "Today, we're announcing new security features which reduce the amount of code you need in order to work with identities and secrets under management." I think I make a valid point. You will also note that the URL for the function works for http as well as https. Google warns you about this:
In order to set up the endpoint as HTTPS only, I have to go through several layers of menus (my function application => Application Settings => Platform Features => Custom Domains) before I can change the default from HTTP to HTTPS:
Only then does an http request redirect to https:
So, let the buyer beware of the pros and cons of these serverless technologies!

