Introduction
Everyone is talking about Data Science and its different steps and phases. This article explores Data Science lifecycles, different steps (in each lifecycle) and would be a great start for Data Scientist beginners in Data Science journey.
Data Science Lifecycle
By its simple definition, Data Science is a multi-disciplinary field that contains multiple processes to extract knowledge or useful output from Input Data. The output may be Predictive or Descriptive analysis, Report, Business Intelligence, etc. Data Science has well-defined lifecycles similar to any other projects and CRISP-DM and TDSP are some of the proven standards.
CRISP – DM: Cross Industry Process for Standard Data Mining
TDSP: Team Data Science Process by Microsoft
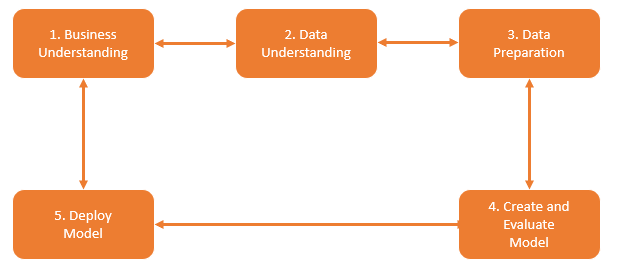
Let's check common lifecycles in Data Science:
- Business Understanding
- Data Understanding
- Data Explore and Preparation
- Create and Evaluate Model
- Deploy Model and turn out effective output
Each lifecycle has different steps and rules to achieve the desired outcome. Multiple iterations of each lifecycle and different component in each cycle make Data Science output as more accurate. In this article, we are going to discuss the first 3 phases in Data Science lifecycles - Business Understanding, Data Understanding and Data Explore and Preparation.
Business Understanding
Business Understanding is always a key phase in any SDLC but it is more critical in Data Science lifecycle. If we misunderstood business, then we would end up with the wrong outcome or even we predicted good output but not acceptable by the customer. The main steps in this phase are:
Identify Stakeholder(s)
Stakeholders are Business Analyst/Expert people and their responsibility is clear all business query from Data Scientist in any phase of Data Science lifecycles.
Set Objective
Understand the business problem and identify whether the problem is applicable to an analytical solution or in other words, if Data science can target business problems. To achieve this, Data Scientist frames the business objective by asking relevant and sharp question to stakeholders. Please find this blog for some relevant questions to be asked to stakeholders.
After this step, Data Scientist summarizes:
-
Proper business requirement and define requirement like - How to increase business profit from 50 to 100 / How to prevent Customer Churn rate, etc.
-
Identity Data Science problem type from the Business requirement and find some Data Science Problem Types.
Data Science Problem Type
| Predictive Analysis | What will happen in the future? |
| Descriptive Analysis | What is happening in the past and now? |
| Prescriptive Analysis | What should be done to enhance or prevent current or future happening? |
Identify and Define Target Variable
Each Data science project contains either Supervised Or Unsupervised learning data.
Supervised learning – In Supervised learning, Data Scientist identifies input and output(target) feature. There are 2 types of Supervised learning.
-
Classification Problem
-
Binary Classification - Identified target feature value is either 0 or 1. Examples – whether people survived or not, is this email Spam or not, etc.
-
Category Classification - Identified target feature value contains multiple discrete values. Examples - How Products are tagged by different category.
-
Regression Problem – Identified target feature values is a continuous type. Examples - Expected mileage for the different type of Cars.
Unsupervised learning – Learn data without being given the correct output feature and mainly focus on the grouping of data or Clustering of Data. Examples - Identify human behavior from video visuals.

Feature and Observation (Columns and Rows)
Data Science Project Execution Plan
Use Project Management Tool like VSTS, JIRA, etc. and create a project execution plan and track each milestone and deliverable in different stages of Data Science lifecycles.
Data Understanding
The main steps in this phase are:
Collect Proper Data Set
Data Scientist collects proper data set that covers all business objectives and ensures Data Sets have required input features that answer all business questions. Data might be stored in a CSV file, database or in different formats and storage media. We can access either entire data and download from its source or through data streaming using a secured API.
Setup Environment for Data
Set up Data hosting environment after Data Scientist collect Data Set. This environment might be either in Local Computer, Cloud and On-premise, etc. Example of Cloud environment is - Azure Blob Storage, Azure SQL Database.
Also, sometimes Data could be in an unstructured format and it has to be converted as structured format before analyzing the same.
Please find Azure environments.
- Azure Notebooks - Free subscription and supports multiple target environments and URL is - https://notebooks.azure.com/
- Data Science Virtual Machine (DSVM) / Deep Learning Virtual Machine (IaaS solution) - Customized virtual machines that contain different tools preconfigures and preinstalled on Azure
- Cloud-based Notebook VM
- ML Studio - UI based tool from Microsoft - https://studio.azureml.net/
- ML Service - PaaS solution
Setup Tools and Package
Setup Tools and Install Packages for data processing. Please find some Tools used in DS - Python, R, Azure Machine Language Learning Environment, SQL and RapidMiner, TensorFlow, etc. There are multiple packages available in each tool to process, manipulate and visualize the data. Panda and Numpy are some of the main packages with Python.
Identity Feature Category
Each feature in Data Set is broadly divided into either Categorical (for string type) or Continuous (for numeric type) Type. Categorical type is further divided into - Ordinal and Binary.
| Feature Type | Description |
| Categorical (Or Nominal) | One or more Category but not quantitative values. Examples - Color with values Red, Green, Yellow, etc. and no numeric significance compare to others. |
| Ordinal | One or more categories but they are quantifiable compared to others. Examples - Bug Priority with values Low, Medium, High and Critical and these values have numerical significance compared to others. |
| Binary | Value of this feature should be either 1 or 0. Examples - Male or Female |
| Continuous | Value between negative infinity to positive infinity. Example: Age
|
Also, there are some other feature types like - Interval, Image, Text, Audio, and Video.
Data Explore and Preparation
The main steps in this phase are:
Data Explore
In this phase, Data Scientist familiarizes each feature in Data Set that includes: Identifies feature type like Categorical, Continuous, etc. How data spread and their distribution, identify if there is any relationship between two features, etc.
Data Scientist uses a different visualization tool to explore the Data and this step helps to fix - missing value, extreme value (outlier) and noisy value in Data preparation phase and determine proper scaling factor in model creation step as well. Here, we are mainly focused on two feature type - Categorical (assume for all string type) and Continuous (for numeric type). Let's discuss different approaches in Data exploring.
Data Exploring - Continuous Feature Type
- Check Centrality Measure Data - Best value that summarizes the measurement of the specific feature
- Check Dispersion Measure - How Data are spreading and its distribution of the specific feature
| Mean | Average value but affected by extreme values |
| Median | Central value of Sorted List and it is not affected by the extreme values and of course Median is best centrality measure if data having extreme values. |
Check Centrality Measure Data
| Range | Difference between maximum and minimum values and if the difference is a small number, then Data packed closely otherwise data packed widely. |
| Box-Whisker Plot | This chart shows how data spread and represented with different Percentiles such as 25%, 50%,75%, minimum, and maximum. Also this chart show any lower and higher outlier values. Examples: For Age feature with 1000 values and if 25% is 32 meant, 25% values are below 32.
|
| Variance | Represents how far each value is from the mean. Small variance meant Data closely packed otherwise widely packed. |
| Histogram | This Graph represents data spread across different bin and this would help to identify outlier and missing value. From Histogram, we can identify – Data Normal Distribution (skewness =0), Positively skewed distribution and Negatively skewed distribution.
|
Dispersion Measure
Data Exploring - Categorical Feature Type
Following options are used are for Categorical feature type data explore.
- Total count for category
- Unique count for category
- BAR chart used to show individual category status
Also, Scatter Plot, Grouping, Cross Tab and Pivot Table and other statistical function can be used to explore both continuous and Categorical Data. There are plenty of frameworks and packages available in each Data Science language to practice any of the above-explained methods. Scatter plot (check the relation between two features) and line chart (for Time series data) are other options for Data explore and mainly used in Advance Data Analysis.
IDEAR and AMAR are custom build utilities for data exploration and these utilities provide clear Data Insight report for each feature based on its type.
Data Preparation
Based on Data Explore, some abnormal behavior can be identified like – Missing Data, Extreme Values (outlier) and Noisy data. These behaviors may impact the accuracy of Data science output and recommended to fix it before creating a model.
- Remove Unwanted Feature - Remove features which make no impact in Data Analysis like Name, Roll Number, etc.
- Fix missing values
- Remove row (observation) which contain the missing feature
- Imputation
- Replace the missing value with a possible value using Mean, Median or Range
- Replace the missing value with Dummy value
- Replace with most frequent value and this would be more applicable for the category feature type
- Forward or Backward fill especially for Time series data
- Fix Outlier (Extreme value) - Outlier value can be identified by Histogram, Box Plot or Scatter plot
- Remove row (observation) which contain the missing feature
- Imputation
- Replace the missing value with a possible value using Mean, Median or Range
- Replace the missing value with Dummy value
- Replace with most frequent value and this would be more applicable for the category feature type
- Binning - Create discrete category from the continuous feature and this would help to place outlier value in any of the bins.
-
Fix Erroneous or noisy Values - Use the same approach of outlier fix
-
Text cleaning - Clean character for Enter, Tab in text data.
In some cases, missing or outlier value cannot be fixed and so Data Scientist creates two models - one with excluding missing data and outlier and other with all data and takes an average of both result as an output.
Feature Engineering
Process of transforming data to another better understanding feature to create better Predictive model. Feature Engineering is a crucial step in any of the Data Science journey and cannot implement without proper Domain knowledge.
Examples: Derive new feature called IsAdult from the Age feature, like IsAdult = 1 if Age > 18 else 0.
Categorical Feature Encoding
Most of the Machine learning algorithms work on numeric data and not Categorical Data. So Data Scientist needs to convert Categorical Type feature to Continuous feature.
The following methods can be used to convert continuous feature from a categorical feature based on feature Type.
Binary Encoding - Use if Category feature has only 2 values like - Male/Female, In this case, Data Scientist creates a new feature like Is_Male with value 0 or 1 accordingly.
Label Encoding - Use if the Category value type is Ordinal Type, i.e., feature values have clear intrinsic sort order. Examples: Software Bug severity - Low, Medium, High and Critical. Here, Data Scientist creates 1 to 4 for Low to Critical values.
One Hot Encoding - Used for Nominal Category Type. Examples - Color with values Red, Blue, and Green. And here, we have to create 3 features like - color_red, color_blue and color_green and fill values appropriately.
So far, we have covered 3 important lifecycles of Data Science - Business Understanding, Data Understanding and Data Preparation and now the Data are ready for model creation. I will discuss the other two lifecycles in the next article and requesting your valuable feedback.
Points of Interest
Familiarizing Data Science lingo like - Supervised learning, Feature Engineering, etc. is one of the most important aspects in Data Science journey.
In this article, I have covered most of the definitions as part of the first 3 lifecycles but recommended to read some other definitions such as Data Correlation, Data Wrangling, Data Factorization and Normalization and advanced statistical functions, etc.
Thank you for reading this article.
History
- 29th April, 2019: First version
- 26th November, 2019: Added Azure environments

