1. Introduction
Discussed in this article is an edge detection algorithm for general images in color or monochrome. This algorithm uses 1-dimensional lines/functions/textures/images generated from input image to find edges in the image.
Compared to results generated from some known methods, this has marked some unseen edges. The algorithm is adaptive and parameter-izable allowing scope to increase or reduce detail and tolerance. This gives a straight forward approach to refine edges within the image with greater accuracy.
The parameters are mostly visual and observable based on human psychological perception (namely angle, color density, subtraction strategy and detail) rather than existing objective and quantitative methods of mathematical transforms.
Since the algorithm does not use heavy matrix calculations / transforms, it delivers more performance. The algorithm is progressive, as it can be used for noisy signals. It can also be used during progressive loading or partly received image. The algorithm can work with as few linear samples as available or as many.
Existing methods are applied to image as a whole and cannot be applied to different parts of the image with different parameters without breaking the image in different parts and later stitching them back.
To add to the above advantages, it is simple to understand and implement.
Later in this document, we also find performance of my current implementation. Also attached are results from experiments conducted with existing images and edges detected by known methods, along with a comparative study with the results generated by the proposed algorithm.
2. Background
Edge detection refers to the process of identifying and locating sharp discontinuities in an image. The discontinuities are abrupt changes in pixel intensity which characterize boundaries of objects in a scene. Classical methods of edge detection involve convolving the image with an operator (a 2-D filter), which is constructed to be sensitive to large gradients in the image while returning values of zero in uniform regions.
Existing methods use a NxN matrix known as kernel to conclude decisions of a point being part of a potential edge. In general and most cases, N=3 where the number of cells in the matrix is 9. Matrix operations are thus performance costly. Also with the increase in the value of N to 4 or 5 or more, the calculations become more complex and duration of first pass results keep increasing.
Many existing methods propose to use noise reduction filter as a pre-requisite for edge detection, thus increasing an additional pass in image processing.
3. How Does It Work
We need a few things here:
- Different colour subtraction methods
- A general line sampler – used for creating 1D images at any angle
- Data Structures customized for different strategies of edge detection
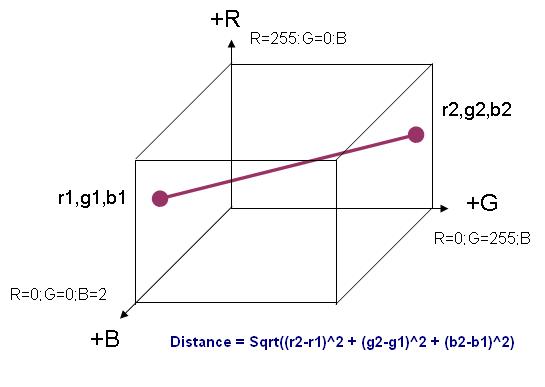
1. Colour subtraction algorithm used to calculate relative difference between any 2 colours:
This distance is used to identify the RGB colour difference between 2 colours. A greater difference increases the probability of the pixel pairs to be detected as an edge point pair. It would be evident from the document later, how the 2 different strategies for suggesting probable edges is dependent on the colour difference.
The proposed method for edge detection allows choice of several colour subtraction methods, as parameters. These methods for colour subtractions are discussed as under.
- Euclidian distance (difference) considering colour as a hypothetical 3D space.
- Sometimes a saturation of different components of colour produce better results. This is more evident, for example, in those images where a) Red-Pass-Filter has been used for image acquisition and the image consists of more red color than green or blue.
Difference = MAX(r1, g1, b1) – MAX(r2, g2, b2)
- For Grayscale images where r=g=b. Then a specific value called luma is used to:
Luma1 = 0.3 * r1 + 0.59 * g1 + 0.11 * b1
Thus Difference = Lima1 – Luma2
2. Line Sampling
The rectangular 2-Dimensional image in this case is split or broken into a list of 1-Dimensional images. It is important to note here that the list of 1-D images or scan lines or 1D-textures would cover the entire image.
Standard line generation algorithm is used here to generate line walking points between start and end points. It is also important here to mention that there may be cases when the number of points generated by the line-walking method is less than the distance between the start and end points. In such cases, additional points are added in equal intervals in the list of generated points, for ease of pixel position approximation.
Below are the examples of how the scan lines would be positioned. For ease of understanding, the scan lines in the example are reasonably spaced. However, in real calculation, the lines are exactly touching each other (distance of 0 pixels between them).

3. Data Structures customized for different strategies of edge detection
Two different strategies are used here too. Both strategies are known to produce different results and have advantages in different situations. They are discussed here along with a block diagram of the process flow.
- Use a user specified parameter to mark ‘maximum edge’ per scan line. In this strategy, a max=N number of pixel pair colour difference values are stored in the data structure. For example,
maxEdges = 5, at the end of a particular scan 5 most difference pixel pairs edge points would be returned by the datastructure suggesting probable edges. Below is a simple flowchart:
- + / - Stack used as an alternative strategy, beneficial in certain situations. In case of a positive
edgePoint (difference of colors between nth and (n+1)th edgePoint is +ve), the pixel pair would get pushed on the stack. Similarly, all +ve edgePoints would get pushed on the stack until a –ve edgePoint is detected. When a ‘-‘ pixel pair color difference is found, all positive edgePoints would get popped until another –ve edgePoint is found on the stack. Immediately after this the current ‘-‘ve edgePoint and the last popped ‘+’ edgePoint would get added in an internal list of edgePoints, thus adding 2 edgePoints to the list.
The above method is applicable for positive pixel pair color difference (edgePoints). Exactly a similar approach would be taken for ‘-‘ve edgePoints too.
At the end of the entire line scan, the remaining entries on the stack would be cleared and ignored. On query for edgePoints the internal list of saved edgePoints encountered would be returned.
A simple block diagram of the flowchart for the above method is mentioned below:
4. Using the Application
A few points of usefulness
Compared to results generated from some known methods, this has marked some unseen edges. The algorithm is adaptive and parameter-izable allowing scope to increase or reduce detail and tolerance. This gives a straight forward approach to refine edges within the image with greater accuracy.
The parameters are mostly visual and observable based on human psychological perception (namely angle, color density, subtraction strategy and detail) rather than existing objective and quantitative methods of mathematical transforms.
Since the algorithm does not use heavy matrix calculations / transforms, it delivers more performance. The algorithm is progressive, as it can be used for noisy signals. It can also be used during progressive loading or partly received image. The algorithm can work with as few linear samples as available or as many.
Existing methods are applied to the image as a whole and cannot be applied to different parts of the image with different parameters without breaking the image in different parts and later stitching them back.
To add to the above advantages, it is simple to understand and implement.
Later in this document, we also find performance of my current implementation. Also attached are results from experiments conducted with existing images and edges detected by known methods, along with a comparative study with the results generated by proposed algorithm.
Please note here that along with this document, I attached a Microsoft PowerPoint presentation, showing more results and comparisons. Here is the list of attachments:
- Microsoft PowerPoint presentation supporting this method
- A C#.NET implementation of the algorithm in a .NET assembly executable
- Some sample images used for testing
A few points to note to check results:
- Open the application which shows a blank form.
- Click on the button called ‘Load’ on the right
- Select one of the test images (or any image) and click okay on the selection dialog
- Adjust the sliders AND/OR choose the strategies to pass parameters to the algorithm
- Please note that the bottom-right segment has 60 degree scan lines which are hard coded. Please call/inform me to make custom angled segments of images.
- Click on generate to see results
- After results are generated, parameters can be readjusted and ‘Generate’ button can be clicked again to refresh the results
- The application in multithreaded and each algorithm configuration runs on a different thread for the 3 different segments
- The numbers written on the right of the form (below the buttons) are the milliseconds required to generate the algorithm, each for each segment
5. Samples
History
- 8th December, 2010: Initial post

