Introduction
The code corresponding to this article is available on CodePlex here.
Articles in this series:
- Aimee.NET - Refactoring Lucene.NET: Setting up the Project
- Aimee.NET - Faster Unit Tests and Refactoring the Documents Folder
This is the second in a series of article on refactoring Lucene.NET to follow .NET best practices and conventions rather than Java's coding styles and limitations. These articles will be available at The Code Project that follow the process from beginning to end. The first article is available at Aimee.NET - Refactoring Lucene.NET: Setting up the Project, and dealt with
- setting up the project on CodePlex,
- setting up the Visual Studio 2010 solution,
- and determining where to focus efforts to produce a set of tests for TDD style refactoring.
In this article, I will discuss:
I had expected that I would go 2 or 3 articles before I had to make breaking changes to the Lucene.NET API. Unfortunately, as you will see, this was not to be. As a result, the Aimee.NET API is very similar, but has some differences which I feel improve the usability of the library.
As you may remember from the previous article, the Lucene.NET test suite required approximately 45 minutes to execute. This was unacceptable for use in a TDD refactoring exercise. I need to be able to make a small number of changes, and then quickly verify that the code is still functioning as expected and defined by the tests. I analyzed the results from NUnit to determine which tests and/or test suites where taking the most time.
Using the information from the analysis, it became apparent that there are a number of tests that are really performance and stress type tests, not the functional tests that would make up a typical Unit Test suite. That is not to say that these are not important tests, just that they belong in a separate set of test suites.
Fortunately, most of these types of tests had the words Random or Stress in the test name. For the short term, I have placed an [Ignore]attribute on these tests, and will come back to them when I address performance tuning and ensuring threading stability. I don't want to do this now, as I will be making changes that will impact or completely change the way the code works. Any performance tuning at this point would be premature, and probably wasted effort.
Additionally, there were a few test suites that had expensive initialization code in the test setup that should have been in the test suite setup. This was a simple change that shaved several minutes off the test execution time.
The result of all this activity was that the unit test execution time was reduced from 45 minutes to just over 7 minutes. While still a little long, it is acceptable for my purposes. I felt that I would not be gaining much for any additional effort and decided to move on to the more interesting activities.
Throughout the Lucene.NET code, instead of using enum to define states and choices, special classes that mimic enum are used. The first of these that a programmer is likely to encounter are Field.Store Field.Index and Field.TermVector These are used as parameters in the Field constructors to specify the behaviour of Document fields when indexed. All of these derive from the Util.Parameter class.
The Parameter Pseudo-enum Class Hierarchy
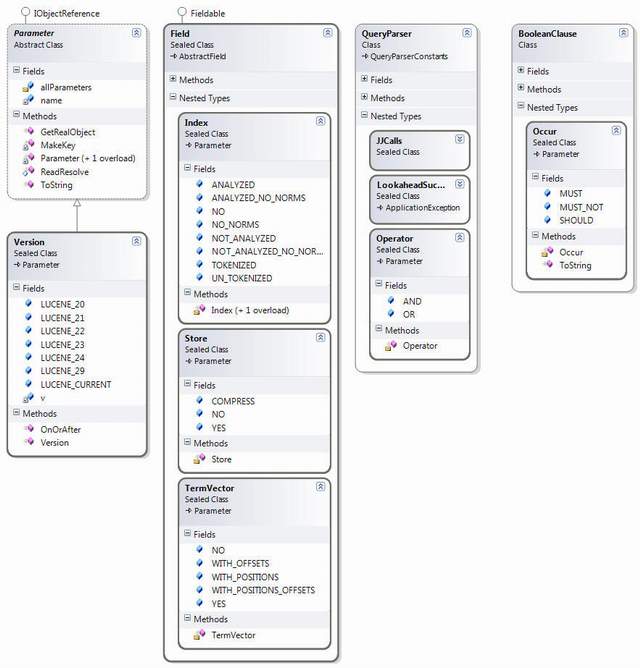
As can be seen from the above diagram, most of these classes are defined within other classes, This creates a hard dependency between the enclosing class and the soon to be enum If we are to end up with code that follows the S.O.L.I.D. principles, we want to be programming to Interfaces, not implementation classes. We want to program to an IField interface that has methods that take the enum as parameters. Both the interface and the enum can be defined in a Core project, and users don't need to worry about the implementation classes, for the most part.
So, the first step was to replace the classes with enum. The Field.Store Version and BooleanClause.Occur were converted to enum. The Field.Index and Field.TermVector classes were converted to enum with the [Flags]attribute. This was done and recompiled. Compilation errors occurred for Version and BooleanClause.Occur This was due to the additional methods that had been added to the original classes. Extension methods were used to solve this issue, as is shown for the Version class below:
public static class VersionExtensions
{
public static bool OnOrAfter(this Lucene.Net.Util.Version v,
Lucene.Net.Util.Version other)
{
return (int)v == 0 || (int)v >= (int)other;
}
}
[Serializable]
public enum Version
{
LUCENE_CURRENT = 0,
LUCENE_20 = 2000,
LUCENE_21 = 2100,
LUCENE_22 = 2200,
LUCENE_23 = 2300,
LUCENE_24 = 2400,
LUCENE_29 = 2900
}
Next, the enums where extracted from their enclosing classes, renamed, and Field enums extracted to separate files using CodeRush. Whether to extract the Operator and the Occur enum from the enclosing classes and move to separate files will be decided when we attack these classes.The new names are shown in the table below:
| Old Name | New Name | Comments |
Lucene.Net.Util.Version | Lucene.Net.Util.Version | Unchanged |
Lucene.Net.Documents.
Field.Index
|
Lucene.Net.Documents.
FieldIndex
| Just remove the last '.' |
Lucene.Net.Documents.
Field.Store
|
Lucene.Net.Documents.
FieldStore
| Just remove the last '.' |
Lucene.Net.Documents.
Field.TermVector
|
Lucene.Net.Documents.
FieldTermVector
| Just remove the last '.' |
Lucene.Net.QueryParsers.
QueryParser.Operator
|
Lucene.Net.QueryParsers.
QueryParser.Operator
| Unchanged |
Lucene.Net.Search.
BooleanClause.Occur
|
Lucene.Net.Search.
BooleanClause.Occur
| Unchanged |
Due to the renaming of the Field enums, a compile of the entire project reported the code changes required. Some tedious editing and the solution, including unit tests and contrib, compiled and passed the unit tests.
Thus, the enum for the Field class now look like:
Field Enums

While editing the code, I noticed that the Lucene.NET code uses Type aliases, using statements in the form of:
using AliasName = TypeFullName;
In the majority of instances, these provided no benefit over the use of namespace using statements, and just added extra lines. Additionally, Type Aliases introduce a code dependency which can result in extra editing when changing or eliminating type names.
This cleaned up the using section of most files from something like:
using System;
using Analyzer = Lucene.Net.Analysis.Analyzer;
using Document = Lucene.Net.Documents.Document;
using AlreadyClosedException = Lucene.Net.Store.AlreadyClosedException;
using Directory = Lucene.Net.Store.Directory;
using ArrayUtil = Lucene.Net.Util.ArrayUtil;
using Constants = Lucene.Net.Util.Constants;
using IndexSearcher = Lucene.Net.Search.IndexSearcher;
using Query = Lucene.Net.Search.Query;
using Scorer = Lucene.Net.Search.Scorer;
using Similarity = Lucene.Net.Search.Similarity;
using Weight = Lucene.Net.Search.Weight;
to:
using System;
using Lucene.Net.Analysis;
using Lucene.Net.Documents;
using Lucene.Net.Store;
using Lucene.Net.Util;
using Lucene.Net.Search;
It was while looking at the Document class that I realized that I was not going to be able to maintain API compatibility with Lucene.NET. The Document is one of the core entities in the Lucene domain. Documents are collections of Fields The user of the Lucene.NET library creates Documents adds Fields to them, and then adds the Documents to an Index Later, the user will ask the Index to return a list of Documents that meet a set of criteria and use the values in certain Fields to display information about the returned Documents
Looking at the code for the document class, I quickly found the code is:
- Using getter and setter methods rather than
Properties - Using an internal class to implement an
Enumerator for the list of fields for the document - LINQ style queries would simplify the code a lot.
- The class has methods using the
Field class and others using the Fieldable interface. I would like it to just know about the Fieldable interface.
Converting Methods to Properties
The first PropertyI implemented was for the Boost value. The GetBoost()and SetBoost(float Value)methods just modified a private field. This made it an excellent candidate for an auto property. Making this change, compiling and fixing the errors was straight forward.
The second property was to replace the Fields getter. This getter returned an untyped IEnumerator which is used to access the Fields that have been added to the Document by returning an instance of an enclosed class implementing an enumerator for the private fields collection. I prefer that typed enumerators be used for added code safety. Thus, I did the following:
Changed the type of the fields field from:
internal System.Collections.IList fields = new System.Collections.ArrayList();
to:
private readonly List<IField> fields = new List<IField>();
This not only added type-safety, but hides the implementation from other classes.
The Fields()method was changed to a property:
public IList<IField> Fields
{
get { return fields; }
}
Now using LINQ queries, the various methods can be made less complex. For example, the Field GetField(string name) oes from:
public Field GetField(System.String name)
{
for (int i = 0; i < fields.Count; i++)
{
Field field = (Field) fields[i];
if (field.Name().Equals(name))
return field;
}
return null;
}
to:
public IField GetField(String name)
{
return fields.FirstOrDefault(f => f.Name == name);
}
The two methods Fieldable[] GetFieldables(string name)and Field[] GetFields(string name)were replaced with a single IField[] GetFields(string name)method.
The two methods Fieldable GetFieldable(string name)and Field GetField(string name)were replaced with a single IField GetField(string name)method.
To accomplish this, I renamed the Fieldable interface to IField as I prefer my Interfaces to begin with I It is important to be able to distinguish between interfaces and classes when understanding and modifying code, they are not the same thing. The convention of starting Interfaces with Imakes this much easier. I also had to add the string ToString()method to this interface.
Future changes may include changing the type of returned collections from IList<IField>to IEnumerator<IField> This would be safer as then it would not be possible to modify the underlying collection with the Add or Remove methods available on IList
Refactoring the Fieldrelated classes followed a similar approach to refactoring Documents There are a number of getter and setter methods that should be implemented as Properties This is shown in the class diagram below:
Original Field Classes
I also:
- Refactored
AbstractField to take advantage of the bit field values for FieldStore and FieldTermVector - Extracted some embedded
IField implementations into separate files for ease of maintainability.
The result is shown below.
Refactored Field Classes
A few small changes were also made to the Documents folder:
NumberTools was removed as it was no longer being used. DateField should be removed, but is required for index backward compatibility. - The
CompressionTools and DateTools classes were made static
In order to make better use of CodeRush's code analysis features, I 'corrected' all the warnings and errors that CodeRush recommended. Most of these fall into two categories:
- Removing redundant namespaces; i.e. changing
System.String to String - Using implicit variables. This means using the
var keyword where possible. I find that this further decouples the code implementation as the type of a variable in a statement like:
var myVar = GetMyVarImplementation()
allows me to change the return type of the method without breaking some code, or any if I have properly programmed to interfaces. Even where the return type changes class hierarchies, if properties and/or methods of the variable are not accessed, then the code doesn't break.
First and foremost, when refactoring always have a working unit test suite. Even simple changes can break other code, and like most developers, I do most of my OSS development at night when tired. I make mistakes. The unit tests catch my mistakes quickly.
The Lucene.NET code is not just a problem due to Java vs. .NET coding styles and practices. There are a number of issues relating to the S.O.L.I.D. principles. This is to be expected in code of this age. However, it does indicate that the Lucene team for the Java code should, and I hope is for V3.X, look at addressing some of these issues.
The next area I will be attacking is the Analysis folder. The reasons for this are twofold. Firstly, it is the next logical step in the Indexing process, and secondly because I have run into issues in my use of Lucene.NET in this area. One big issue is the inability to modify the lexical analyzer used by StandardAnalyzer. This has been implemented using a tool that generates Java, and has Java embedded in the grammar definition.
Following this, I will probably attack the Store folder. This really could take advantage of a number of .NET and Windows features to improve performance.
The probable order for the rest of the folders is shown below, but I am looking for feedback and potential help.
- QueryParser
- Util
- Index
- Search
- Messages
I will also be renaming the namespaces from Lucene.NET to Aimee.NET.
History
- December 6, 2010: First release

