Introduction
Reinforcement Learning is a step by step machine learning process where, after each step, the machine receives a reward that reflects how good or bad the step was in terms of achieving the target goal. By exploring its environment and exploiting the most rewarding steps, it learns to choose the best action at each stage.
Tic Tac Toe Example
This piece is centred on teaching an artificial intelligence to play Tic Tac Toe or, more precisely, to win at Tic Tac Toe. It doesn't actually know anything about the rules of the game or store the history of the moves made. On each turn, it simply selects a move with the highest potential reward from the moves available. The relative merit of these moves is learned during training by sampling the moves and rewards received during simulated games. Before diving into how this is achieved, it may be helpful to clarify some of the nomenclature used in reinforcement learning.
Reinforcement Learning Terminology
The artificial intelligence is known as the Agent. At each step, it performs an Action which results in some change in the state of the Environment in which it operates. The environment responds by rewarding the Agent depending upon how good or bad the action was. The environment then provides feedback to the Agent that reflects the new state of the environment and enables the agent to have sufficient information to take its next step. The Agent follows a policy that determines the action it takes from a given state. The learning process improves the policy. So it's the policy that is actually being built, not the agent. The agent is the agent of the policy, taking actions dictated by the policy. Each state has the value of the expected return, in terms of rewards, from being in that state. A state's value is used to choose between states. The policy is usually a greedy one. That is, the state with the highest value is chosen, as a basic premise of reinforcement learning is that the policy that returns the highest expected reward at every step is the best policy to follow. For this decision process to work, the process must be a Markov Decision Process.
Markov Decision Process
A Markov decision process (MDP) is a step by step process where the present state has sufficient information to be able to determine the probability of being in each of the subsequent states. To get a better understanding of an MDP, it is sometimes best to consider what process is not an MDP. If you were trying to plot the position of a car at a given time step and you were given the direction but not the velocity of the car, that would not be a MDP as the position (state) the car was in at each time step could not be determined. Another example is a process where, at each step, the action is to draw a card from a stack of cards and to move left if it was a face card and to move right if it wasn't. In this case, the possible states are known, either the state to the left or the state to the right, but the probability of being in either state is not known as the distribution of cards in the stack is unknown, so it isn't an MDP.
Implementing Tic Tac Toe as a Markov Decision Process
Tic Tac Toe is quite easy to implement as a Markov Decision process as each move is a step with an action that changes the state of play. The number of actions available to the agent at each step is equal to the number of unoccupied squares on the board's 3X3 grid. The agent needs to be able to look up the values, in terms of expected rewards, of the states that result from each of the available actions and then choose the action with the highest value. The agent learns the value of the states and actions during training when it samples many moves along with the rewards that it receives as a result of the moves. As part of the training process, a record is kept of the number of times that a state's value has been updated because the amount by which the value is updated is reduced with each update. So each state needs to have a unique key that can be used to lookup the value of that state and the number of times the state has been updated. If the state of play can be encrypted as a numeric value, it can be used as the key to a dictionary that stores both the number of times the state has been updated and the value of the state as a ValueTuple of type int,double. The obvious way to do this is to encode the state as a, potentially, nine figure positive integer giving an 'X' a value of 2 and a 'O' a value of 1. So the state of play below would be encoded as 200012101.
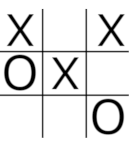
The value of an 'X' in a square is equal to 2 multipled by 10 to the power of the index value (0-8) of the square but it's more efficient to use base 3 rather than base 10 so, using the base 3 notation,, the board is encoded as:
(1*3^0)+(1*3^2)+(2*3^3)+(1*3^4)+(2*3^8)=13267
The method for encrypting the board array into a base 3 number is quite straight forward.
public int BoardToState()
{
int id = 0;
for (int i = 0; i < Squares.Length; i++)
{
int value = 0;
if (!Squares[i].IsEmpty)
{
value = Squares[i].Content == 'X' ? 1 : 2;
id += (int)(value * Math.Pow(3, Squares[i].BoardIndex));
}
}
return id;
}
The decrypt method is as follows:
public IBoard StateToBoard(int s)
{
int state = s;
var board = new OXBoard();
for (int i = board.Squares.Length-1; i >=0; i--)
{
int value =(int)(state/ Math.Pow(3, i));
if(value!=0)
{
board[i].Content = value == 1 ? 'X' : 'O';
state -= (int)(value * Math.Pow(3, i));
}
}
return board;
}
The StateToStatePrimes method below iterates over the vacant squares and, with each iteration, selects the new state that would result if the agent was to occupy that square. The selected states are returned as an array from which the agent can select the state with the highest value and make its move.
public int[] StateToStatePrimes(int state)
{
int existingState = state;
List<int> statePrimes = new List<int>();
for (int i = 8; i >= 0; i--)
{
int value = (int)(state / Math.Pow(3, i));
if (value == 0)
{
var sPrime = existingState + (int)(2 * Math.Pow(3, i));
statePrimes.Add(sPrime);
}
state -= (int)(value * Math.Pow(3, i));
}
return statePrimes.ToArray();
}
With these methods in place, the next thing to consider is how to learn a policy where the values assigned to states are accurate and the actions taken are winning ones. This is where the Bellman Equation comes into play.
The Bellman Equation
Reinforcement learning is centred around the Bellman equation. The equation relates the value of being in the present state to the expected reward from taking an action at each of the subsequent steps. It consists of two parts, the reward for taking the action and the discounted value of the next state.
v(s1) = R + γ*v(s2)
Where v(s1) is the value of the present state, R is the reward for taking the next action and γ*v(s2) is the discounted value of the next state. Gamma (γ) is the discount factor. Its use results in immediate rewards being more important than future rewards. The discount factor is particularly useful in continuing processes as it prevents endless loops from racheting up rewards. The Bellman equation is used at each step and is applied in recursive-like way so that the value of the next state becomes the value of the current state when the next steps taken. So the problem of determining the values of the opening states is broken down into applying the Bellman equation in a series of steps all the way to the end move. Actually, it's easier to think in terms of working backwards starting from the move that terminates the game. That is the approach used in Dynamic programming.
Dynamic Programming
Dynamic Programming is not like C# programming. It is a way of solving a mathematical problem by breaking it down into a series of steps. By repeatedly applying the Bellman equation, the value of every possible state in Tic Tac Toe can be determined by working backwards (backing up) from each of the possible end states (last moves) all the way to the first states (opening moves). To get an idea of how this works, consider the following example.
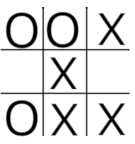
The reward system is set as 11 for a win, 6 for a draw. The agent, playerO, is in state 10304, it has a choice of 2 actions, to move into square 3 which will result in a transition to state 10304 + 2*3^3=10358 and win the game with a reward of 11 or to move into square 5 which will result in a transition to state 10304 + 2*3^5=10790 in which case the game is a draw and the agent receives a reward of 6. The policy selects the state with the highest reward and so the agent moves into square 3 and wins. From this experience, the agent can gain an important piece of information, namely the value of being in the state 10304. From this state, it has an equal choice of moving to state 10358 and receiving a reward of 11 or moving to state 10790 and receiving a reward of 6 So the value of being in state 10304 is (11+6)/2=8.5. States 10358 and 10780 are known as terminal states and have a value of zero because a state's value is defined as the value, in terms of expected returns, from being in the state and following the agent's policy from then onwards. By considering all possible end moves and continually backing up state values from the current state to all of the states that were available for the previous move, it is possible to determine all of the relevant values right the way back to the opening move. This is feasible in a simple game like tic tac toe but is too computationally expensive in most situations. A more practical approach is to use Monte Carlo evaluation.
Monte Carlo Evaluation
Monte Carlo evaluation simplifies the problem of determining the value of every state in a MDP by repeatedly sampling complete episodes of the MDP and determining the mean value of every state encountered over many episodes. In Tic Tac Toe, an episode is a single completed game. If, in the first episode, the result was a win and the reward value was 10, every state encountered in the game would be given a value of 10. If, in the second episode, the result was a draw and the reward was 6, every state encountered in the game would be given a value of 6 except for the states that were also encountered in the first game. These states would now have value of (10+6)/2=8. Over many episodes, the value of the states will become very close to their true value. This technique will work well for games of Tic Tac Toe because the MDP is short. There are, however, a couple of issues that arise when it is deployed with more complicated MDPs. The state values take a long time to converge to their true value and every episode has to terminate before any learning can take place. There are other techniques available for determining the best policy that avoid these problems, a well known one is Temporal Difference Learning.
Temporal Difference Learning
Temporal difference learning is an algorithm where the policy for choosing the action to be taken at each step is improved by repeatedly sampling transitions from state to state. It achieves superior performance over Monte Carlo evaluation by employing a mechanism known as bootstrapping to update the state values. Bootstrapping is achieved by using the value of the next state to pull up (or down) the value of the existing state. As it's a one step look ahead, it can be used while the MDP is actually running and does not need to wait until the process terminates. The learning process involves using the value of an action taken in a state to update that state's value. A state's value is formally defined as the value, in terms of expected returns, from being in the state and following the agent's policy from then onwards. The action value is the value, in terms of expected rewards, for taking the action and following the agent's policy from then onwards. In order to update a state value from an action value, the probability of the action resulting in a transition to the next state needs to be known. It is not always 100% as some actions have a random component. But, if action values are stored instead of state values, their values can simply be updated by sampling the steps from action value to action value in a similar way to Monte Carlo Evaluation and the agent does not need to have a model of the transition probabilities. Temporal Difference Learning that uses action values instead of state values is known as Q-Learning, (Q-value is another name for an action value). The Bellman equation is used to update the action values.
currentStateVal = currentStateVal + alpha * (-1 + (gamma*newStateVal) - currentStateVal);
The Q-value of the present state is updated to the Q-value of the present state plus the Q-value of the next state minus the value of the present state discounted by a factor, 'alpha'. The value of the next state includes the reward (-1) for moving into that state. The variable, alpha, is a discount factor that's applied to the difference between the two states. The more the state is updated the smaller the update amount becomes. Alpha is simply 1/N where N is the number of times the state has been updated. As previously mentioned, γ is a discount factor that's used to discount future rewards. An Epsilon greedy policy is used to choose the action.
Epsilon Greedy Policy Improvement
A greedy policy is a policy that selects the action with the highest Q-value at each time step. If this was applied at every step, there would be too much exploitation of existing pathways through the MDP and insufficient exploration of new pathways. So, at each step, a random selection is made with a frequency of epsilon percent and a greedy policy is selected with a frequency of 1-epsilon percent. In a short MDP, epsilon is best set to a high percentage. In an extensive MDP, epsilon can be set to a high initial value and then be reduced over time.
The Learning Method
Two values need to be stored for each state, the value of the state and the number of times the value has been updated. A Dictionary is used to store the required data. It uses the state, encoded as an integer, as the key and a ValueTuple of type int, double as the value. The key references the state and the ValueTuple stores the number of updates and the state's value.
public Dictionary<int, (int, double)> FitnessDict { get; private set; }
public void Learn(int[] states, GameState gameState)
{
double gamma = Constants.Gamma;
int currState = states[0];
int newState = states[1];
UpdateFitnessDict(newState, gameState);
(int currStateCount, double currStateVal) = FitnessDict[currState];
currStateCount += 1;
double alpha = 1 / (double)currStateCount;
(int newStateCount, double newStateVal) = FitnessDict[newState];
if (gameState != GameState.InPlay)
{
currStateVal = currStateVal + (alpha * (rewardsDict[gameState] - currStateVal));
FitnessDict[currState] = (currStateCount, currStateVal);
return;
}
currStateVal = currStateVal + alpha * (-1 + (gamma*newStateVal) - currStateVal);
FitnessDict[currState] = (currStateCount, currStateVal);
}
private void UpdateFitnessDict(int newState, GameState gameState)
{
if (!FitnessDict.ContainsKey(newState))
{
FitnessDict.Add(newState, (0, rewardsDict[gameState]));
}
}
Training
Training consists of repeatedly sampling the actions from state to state and calling the learning method after each action. During training, every move made in a game is part of the MDP. On the agent's move, the agent has a choice of actions, unless there is just one vacant square left. When it's the opponent's move, the agent moves into a state selected by the opponent. This arrangement enables the agent to learn from both its own choice and from the response of the opponent. It also encapsulates every change of state. Training needs to include games where the agent plays first and games where the opponent plays first. The training method runs asynchronously and enables progress reporting and cancellation.
public void Train(int max, bool isOFirst, IProgress<int> progress, CancellationToken ct)
{
int maxGames = max;
int[] states = new int[2];
char[] Players = isOFirst ? new char[] { 'O', 'X' } : new char[] { 'X', 'O' };
int totalMoves = 0;
int totalGames = 0;
Move move;
while (totalGames < maxGames)
{
move.MoveResult = GameState.InPlay;
move.Index = -1;
int moveNumber = 0;
int currentState = 0;
int newState = 0;
board.Reset();
while (move.MoveResult == GameState.InPlay)
{
char player = Players[moveNumber % 2];
move = player == 'X' ? RandMoveX() : RandMoveO(currentState);
board[move.Index].Content = player;
newState = board.BoardToState();
if (move.MoveResult == GameState.InPlay
&& !board.Lines.Any(l => !l.IsLineOblocked || !l.IsLineXblocked))
{
move.MoveResult = GameState.Draw;
}
states[0] = currentState;
states[1] = newState;
learner.Learn(states, move.MoveResult);
currentState = newState;
moveNumber++;
}
totalMoves += moveNumber - 1;
totalGames += 1;
if(totalGames % Constants.ReportingFreq == 0)
{
progress.Report(totalGames / maxGames);
ct.ThrowIfCancellationRequested();
}
}
}
Infallibility Testing
A training cycle consists of two parts. In the first part, the agent plays the opening moves. In the second part, the opponent starts the games. After every part, the policy is tested against all possible plays by the opponent. When no win is found for the opponent, training stops, otherwise the cycle is repeated. On my machine, it usually takes less than a minute for training to complete. Details of the testing method and the methods for determining the various states of play are given in an earlier article where a strategy based solution to playing tic tac toe was developed.
private Progress<int> progress = new Progress<int>();
private CancellationTokenSource cts = new CancellationTokenSource();
private IRandomTrainer trainer;
private IInfallibilityTester tester;
public TrainingScheduler(IRandomTrainer trainer, IInfallibilityTester tester)
{
this.tester = tester;
this.trainer = trainer;
progress.ProgressChanged += ReportProgress;
}
private void ReportProgress(object sender, int percent)
{
if (Console.KeyAvailable && Console.ReadKey(true).Key == ConsoleKey.Escape)
{
Console.Write(Constants.Cancelling);
cts.Cancel();
}
Console.Write(".");
}
public async Task ScheduleTraining()
{
int runsX = Constants.TrainingRunsX;
int runsO = Constants.TrainingRunsO;
int xFirstResult = -1;
int oFirstResult = -1;
bool isPlayerOFirst = true;
Console.WriteLine(Constants.TrainingPressEsc);
int iterations = 0;
while (xFirstResult != 0 || oFirstResult != 0)
{
if (iterations == Constants.IterationsBeforeReset)
{
iterations = 0;
trainer.Reset();
}
try
{
await Task.Run(() => trainer.Train(runsO, isPlayerOFirst, progress, cts.Token));
await Task.Run(() => trainer.Train(runsX, !isPlayerOFirst, progress, cts.Token));
oFirstResult = tester.RunTester(isPlayerOFirst);
xFirstResult = tester.RunTester(!isPlayerOFirst);
iterations += 1;
}
catch (OperationCanceledException)
{
throw;
}
}
}
Setting The Reward Values
It's important to make each step in the MDP painful for the agent so that it takes the quickest route. A value of -1 works well and forms a base line for the other rewards. There needs to be a positive difference between the reward for a Win and the reward for a Draw or else the Agent will choose a quick Draw over a slow win. The exact values are not critical. It would appear that the state values converge to their true value more quickly when there is a relatively small difference between the Win(10), Draw(2) and Lose(-30), presumably because temporal difference learning bootstraps the state values and there is less heavy lifting to do if the differences are small. The figures in brackets are the values used in the example app, in addition, the discount value 'gamma' is set at 0.9. No doubt performance can be improved further if these figures are 'tweaked' a bit.
Conclusion
Reinforcement learning is an amazingly powerful algorithm that uses a series of relatively simple steps chained together to produce a form of artificial intelligence. But the nomenclature used in reinforcement learning along with the semi recursive way the Bellman equation is applied can make the subject difficult for the newcomer to understand. It's hoped that this oversimplified piece may demystify the subject to some extent and encourage further study of this fascinating subject.
References and Acknowledgements
- Machine Learning by Tom M. Mitchell. An overview of machine learning with an excellent chapter on Reinforcement Learning.
- Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto. This is the oracle of reinforcement learning but the learning curve is very steep for the beginner. A draft version was available online but may now be subject to copyright.
- Reinforcement Learning Course by David Silver. A very informative series of lectures that assumes no knowledge of the subject but some understanding of mathematical notations is helpful. Available fee online here
- TicTacToe - MiniMax Without Recursion by Christ Kennedy. An interesting brute force implementation of Tic Tac Toe with a good explanation of how to encode states of play as a positive base 3 integer.

