Introduction
To do the full-text search in an MS SQL Server application, you usually have two options:
Select Something From SomeTable Where SomeText Like %SomePhrases%.Or:
- The SQL Server built-in full text engine.
The first option can only handle an 8000 char length field (4000 Unicode char). Sure, you can break a long text into multiple 8K fields, but the problem is the %SomePhrases% pattern. This query will always lead to a "brute force" table scan, which can be very slow when your text grows.
The second option is a better choice. However, it still has two issues:
- The SQL Server desktop edition (MSDE) doesn't have this built-in engine.
- You have little control on it even when you have this engine with your SQL Server edition.
The goal of the FTC method is to make the full-text index and search process on SQL Server easy to understand, easy to implement, and let the programmer gain total control of this process.
The FTC method---How to index
The method is made of Stored Procedures, and runs on all SQL Server editions including MSDE and Express edition.
Let's see a table:
tbl_Content
| ContentID | CreateDate | ContentText |
| 4891 | 3/30/2006 | The quick brown fox jumps over the lazy dog. |
The FTC splits the content text words one by one, and inserts them into an index table. No matter how big it is, the single word is always represented by an integer. This integer is the index ID of the word. Noise words such as "the" are ignored. The FTC maintains an extra table to handle these noise words.
tbl_WordIndex
| WordIndex | IndexWord |
| 1 | quick |
| 2 | brown |
| 3 | fox |
| 4 | jumps |
| 5 | over |
| 6 | lazy |
| 7 | dog |
tbl_IndexMap links tbl_WordIndex and tbl_Content. The three fields of this table are all integers. This eliminates the final table size and makes the search faster. To avoid any "brute force table scan (i.e., the "%%" pattern query against tbl_Content), the FTC records the start position of each word in the text. It's just like a pointer so that the FTC can always tell the word's exact position in the original text.
tbl_IndexMap
| WordIndex | WordStartPosition | ContentID |
| 1 | 5 | quick |
| 2 | 11 | brown |
| 3 | 17 | fox |
| 4 | 21 | jumps |
| 5 | 27 | over |
| 6 | 36 | lazy |
| 7 | 41 | dog |
The FTC method---How to split words
Splitting words from a phrase is called "stemming". Most full-text engines use "stemming symbols" to stem Latin based languages such as English, French, Spanish, Italian, and German. The stemming symbols include space, comma, period, and others. For far east languages such as Chinese, Japanese, and Korean (CJK), a character is a stemming symbol for itself.
The FTC uses the UNICODE range to do stemming. For any given string, the FTC handles it char by char. If the char is between 0x0041 and 0x005a, the FTC knows it is a meaningful Latin char. The FTC doesn't check the next char until it hits any non-Latin UNICODE. When a non-Latin code gets hit, the FTC will build a word from the previous chars. Note: The range 0x0041-0x005a is just an example. Please check www.unicode.org to find out more details about UNICODE.
The FTC method---How to search
Assume you want to search the exact phrase "brown fox jumps" from the content table.
Step 1: Create a temporary phrase table for this job
| WordIndex | PhraseWord | WordRelativePosition |
| Brown | 1 |
| Fox | 7 |
| jumps | 11 |
Basically, the phrase is split into words, and these words are inserted into the temporary phrase table. "WordRelativePosition" is the word position in the phrase.
Step 2: Fill in the index ID for each word (from tbl_WordIndex)
| WordIndex | PhraseWord | WordRelativePosition |
| 2 | Brown | 1 |
| 3 | Fox | 7 |
| 4 | jumps | 11 |
Step 3: Searching...
The goal is to find if there is anything in "tbl_IndexMap" having the same word indexes and the same relative positions as the phrase table. In the temporary phrase table, "brown", "fox", "jumps", respectively, have the positions "1", "7", "11". In tbl_IndexMap, "brown", "fox", "jumps", respectively, have the positions "11", "17", "21". Absolutely, they are different. However, they are relatively the same, they all have the same distance starting from the word "brown". Thus, the FTC program can tell the phrase "brown fox jumps" has an exact search result from "content# 4891".
Tables
The demo implements these tables:
- tdatArchiveEntry -- This table saves all the text entries.
- tdatWordIndex -- This table handles the unique word index. Each word is represented by an integer. The integer is the word index ID.
- tdatWordIndex2Text -- This maps "tdatWordIndex" and "tdatArchiveEntry".
- tdatWordIndexControl -- This provides a chance for the long run index process to stop right away.
- trefIndexStatus -- This is a reference table. It includes four possible statuses of one entry: "do not index", "ready to index", "doing index", "index done".
- trefWordNoise -- This is also a reference table. All the noise words are here, such as "the", "a", "this", "that" etc.
Stored Procedures
The demo implements these Stored Procedures:
up_EntryAddup_EntryAddStringChunkup_EntryContentup_EntryListup_EntryReadyToIndexup_EntryRemoveup_MaxPageNumup_WordIndexup_WordIndexControlup_WordIndexProgressup_WordIndexStartOverup_WordSearch
It's very straightforward naming. You can tell the function based on the name. The two most important SPs are up_WordIndex and up_WordSearch.
up_wordIndex indexes all the entries having the "ready to index" status. After indexed, these entries will have the "index done" status. This procedure can be a long run job. No input parameters are needed. To stop the long running job, you can set tdatWordIndexControl's ynDoIndex field to "no". This will stop the running process right away.
The front-end application calls up_wordSearch to do the exact or all search. "Exact search" means the user wants to find the exact phrase "jumps over the lazy dog" in a text; "all search" means the user wants to find "jumps,dog,fox" together in a text.
Important note: Yes, you can run up_WordIndex concurrently, and of course, you can run it on demand at any time. However, it's a bad idea unless you are developing a single user system.
The index process is a heavy-duty long run process.
Imagine a web application which handles concurrent user input. If the system starts an index process whenever a user submits his/her input, guess what will happen?
If just one user submits, you are lucky; 10 users submit their inputs together, the system annoyingly slows down a bit; 50 users submit together, your system might crash.
Some good practices should be:
- Put the index process in a scheduler and run it as a batch.
- Design your system to make the index process running whenever the system is idle.
Front end tricks
The demo's front end is a C# WinForms application with a web browser control.
The ActiveX control always points to a local HTML file named "ax.htm". Whenever it needs to be refreshed, the FTC program will do some file editing to "ax.htm" and raises the NavigateComplete2 event to update the page.
Whenever a hyperlink such as "view", "delete", "page number" gets clicked in ax.htm, the FTC front-end form will respond to it. The trick behinds those hyperlinks is simple, just "about:WhatEverCommand".
There are so many other documents teaching how to use ATL and COM/ActiveX handler to fulfill the same task, but none of them are as easy as the protocol "about:".
Non-official performance benchmark
The performance of dexleapFTC depends on many factors such as hardware configuration, concurrent requests, index quality and bandwidth etc.
I setup an online live demo to test it as a web portal full text engine. It took about 400 seconds to index 450,000 English words in the online live demo.
I also tested it locally. The "exact phrase" search in 200,000 English words is less than 0.2 seconds on a 800MHz/512M PC; the "exact phrase" search in 700,000 English words is less than 0.5 seconds on the same PC (averagely, one English word composed of 4.5 characters).
Naming conventions in the source code (boring details)
The naming convention is very important. It helps to create a self-explained source code, which is easier for project review and program maintenance.
The FTC project is done by using C# (.NET Framework 1.1/VS.NET 2003) and MSDE2000. Here is the naming convention used throughout the FTC project:
- A
DataTable's name starts with tdat, e.g.: tdatArchiveEntry. - A reference table's name starts with tref, e.g.,
trefIndexStatus. - A Stored Procedure's name is like up_SubjectVerb, e.g.,
up_EntryAddStringChunk. - A class member variable's name starts with lowercase, e.g.,
sCurrentPath. - A function's name starts with uppercase, e.g.,
RefreshIndexProgress(), Dal_sEntryText(int _ixArchiveEntry). - A function local variable's name starts with underscore, e.g.,
_daWordSearch.
A little bit more rules for variables:
- Most variables' name follows the pattern: type + Subject + [Verb] (lowercase/uppercase is part of it).
- No boolean variable used in the FTC project. Something like
_ynDoIndex is used for that purpose. "yes" means do index, "no" means don't index. - "ix" represents "index", which is the position or primary key in the array/list/table/loop.
- "n" represents "status" or "state", which is the one status/state in "n" options.
- "cnt" is "count". The variable will count how many elements in the array/list/table.
- "s" is a UNICODE string; "as" is an ASCII string.
- "conn" is "connection"; "cmd" is "command".
How to use the demo project
The userguide.chm and programmerguide.chm files are included in the demo project folder.
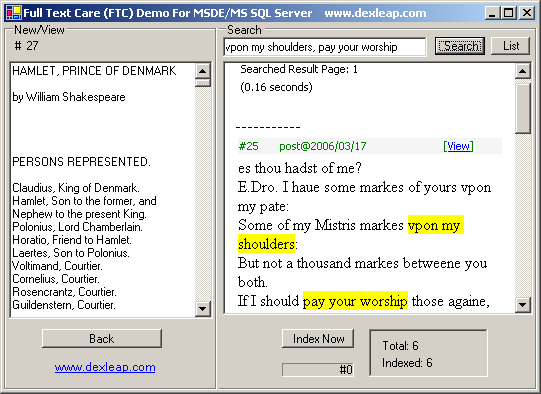
To make you test the demo easier, I already input 6 Shakespeare plays to the database. Many thanks to Project Gutenberg, they make free text without copyright issues.
Finally
© 2005-2006 DEXLEAP.COM All rights reserved.
The only authorized versions of this article are available from: www.codeproject.com, www.dexleap.com.

